Project 4: Build a Tree-sitter Grammar
Define a complete Tree-sitter grammar and query set for a custom language and integrate it with Neovim highlighting.
Quick Reference
| Attribute | Value |
|---|---|
| Difficulty | Advanced |
| Time Estimate | 4-7 days |
| Main Programming Language | JavaScript (Tree-sitter DSL) |
| Alternative Programming Languages | None (Tree-sitter grammar DSL is JS) |
| Coolness Level | Level 8 - You built a parser used by the editor |
| Business Potential | Medium (language tooling foundation) |
| Prerequisites | Grammar basics, parsing concepts, Neovim Treesitter |
| Key Topics | CFGs, precedence, Tree-sitter DSL, queries |
1. Learning Objectives
By completing this project, you will:
- Design a context-free grammar for a real language.
- Implement a Tree-sitter grammar with precedence and associativity.
- Write highlight and fold queries for Neovim.
- Handle error recovery so parsing stays usable while editing.
- Test grammars with
tree-sitterCLI and corpus tests. - Integrate the grammar into Neovim runtime files.
2. All Theory Needed (Per-Concept Breakdown)
2.1 Context-Free Grammars (CFGs)
Description
A CFG defines a language by describing how tokens compose into higher-level constructs.
Definitions & Key Terms
- Nonterminal: A syntactic category like
expressionorstatement. - Terminal: A token like
+oridentifier. - Production: A rule like
expr -> expr + term.
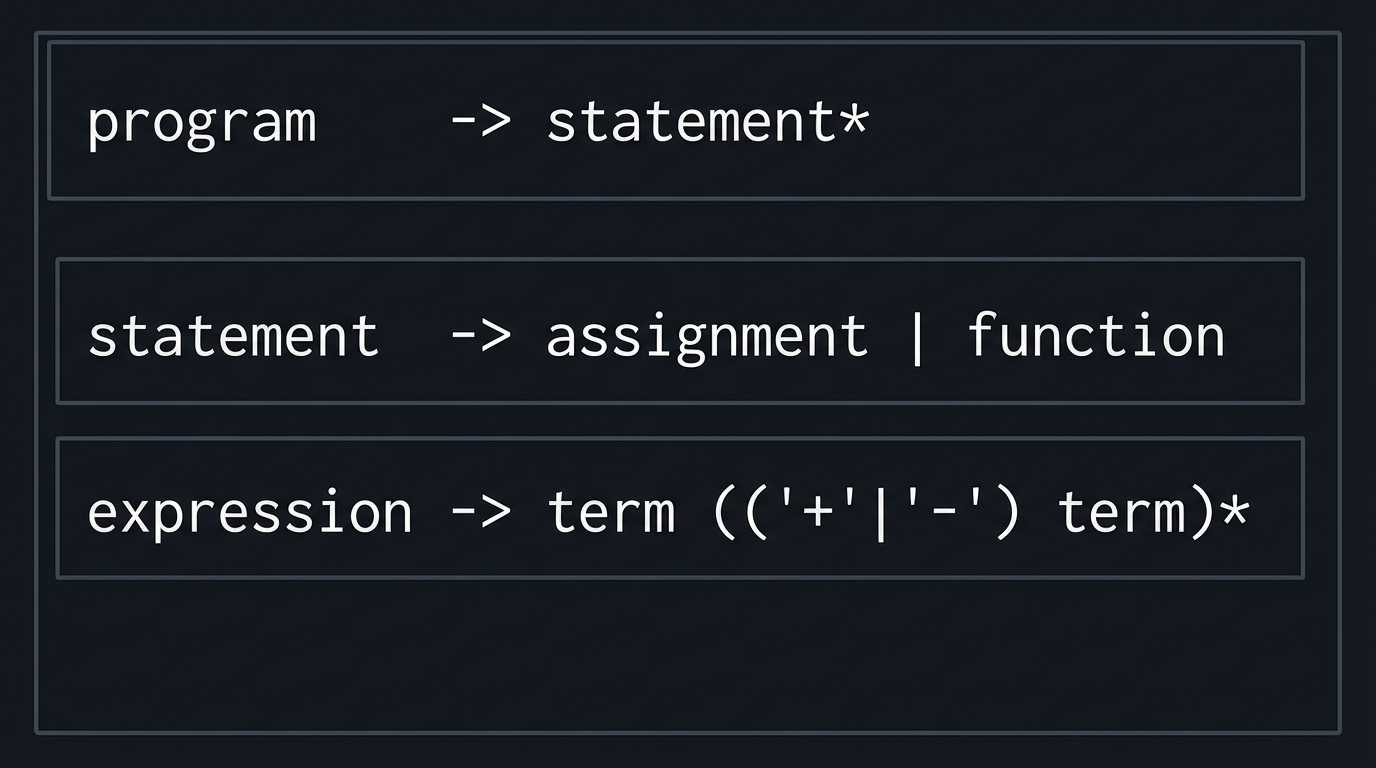
Mental Model Diagram (ASCII)
program
-> statement*
statement
-> assignment | function
expression
-> term (('+'|'-') term)*
How It Works (Step-by-Step)
- Identify core syntactic forms (statements, expressions).
- Define productions that describe valid compositions.
- Use recursion to represent nesting.
- Ensure grammar is unambiguous for common cases.
Minimal Concrete Example
expression -> term (("+"|"-") term)*
term -> number | identifier | "(" expression ")"

Common Misconceptions
- “CFGs define semantics” -> They define structure only.
- “Left recursion is always bad” -> Tree-sitter handles it in specific ways.
Check-Your-Understanding Questions
- Explain the difference between terminals and nonterminals.
- Predict what parse tree is produced for
1+2*3with naive rules. - Explain why ambiguity is a problem for incremental parsing.
Where You’ll Apply It
- See §3.2 requirements and §5.10 Phase 1.
- Also used in P05-lsp-server for symbol parsing.
2.2 Tree-sitter DSL and Precedence
Description
Tree-sitter uses a JavaScript DSL to describe grammar rules, precedence, and associativity.
Definitions & Key Terms
seq: Sequence of tokens or rules.choice: Alternatives between rules.prec: Precedence to resolve conflicts.prec.left/right: Associativity controls.
Mental Model Diagram (ASCII)
prec.left(1, seq(expr, "+", expr))
prec.left(2, seq(expr, "*", expr))
How It Works (Step-by-Step)
- Start with minimal grammar rules.
- Add operator precedence with
preccalls. - Use
fieldto label important subnodes. - Run
tree-sitter generateto discover conflicts.
Minimal Concrete Example
module.exports = grammar({
name: "xyl",
rules: {
expression: $ => choice($.binary, $.number),
binary: $ => prec.left(1, seq($.expression, "+", $.expression)),
number: $ => /[0-9]+/,
}
});
Common Misconceptions
- “Precedence fixes everything” -> Some conflicts require grammar refactoring.
- “Left recursion is always allowed” -> Tree-sitter limits certain patterns.
Check-Your-Understanding Questions
- Explain how
prec.leftchanges parse trees. - Predict what happens if two rules have the same precedence.
- Explain why
fieldis helpful for later tooling.
Where You’ll Apply It
- See §5.10 Phase 2 and §7.1 pitfalls.
- Also used in P06-neovim-lite-capstone.
2.3 Lexing, Tokens, and External Scanners
Description
Tree-sitter combines a built-in lexer with optional external scanners for complex tokens.
Definitions & Key Terms
- Token: Smallest unit recognized by lexer.
- External scanner: Custom lexer written in C for complex tokens.
- Conflict: Overlapping token definitions.
Mental Model Diagram (ASCII)
Input stream -> Lexer -> Tokens -> Parser -> CST
How It Works (Step-by-Step)
- Define regex tokens for identifiers, numbers, strings.
- Use
tokenandtoken.immediatefor precise control. - Add an external scanner when regex is insufficient.
Minimal Concrete Example
identifier: _ => /[a-zA-Z_][a-zA-Z0-9_]*/
string: _ => /"([^"\\]|\\.)*"/
Common Misconceptions
- “Regex is always enough” -> Some tokens need custom logic.
- “Lexing and parsing are separate” -> Tree-sitter blends them.
Check-Your-Understanding Questions
- Explain when you would need an external scanner.
- Predict what happens if two tokens overlap.
- Explain how
token.immediateaffects whitespace handling.
Where You’ll Apply It
- See §3.5 data formats and §5.10 Phase 2.
- Also used in P05-lsp-server for tokenization.
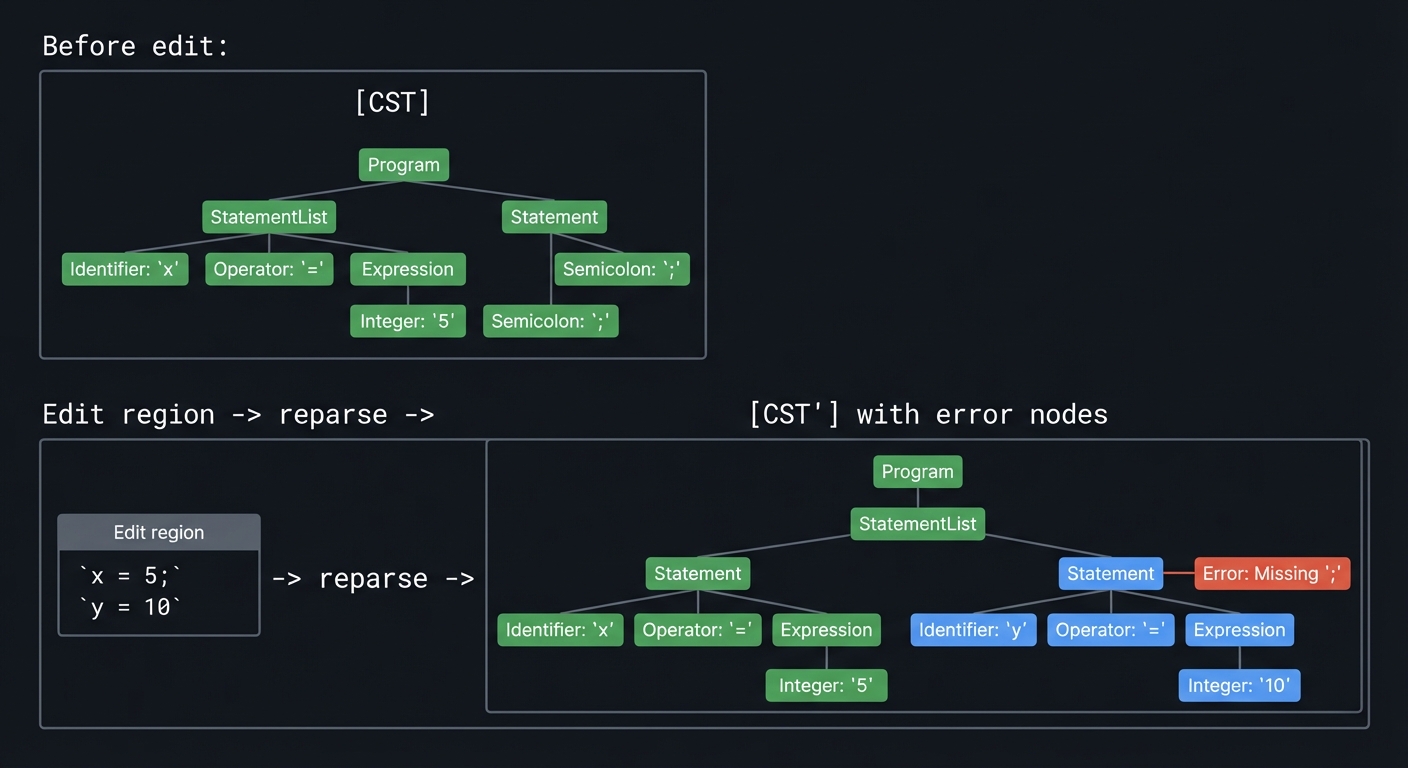
2.4 Error Recovery and Incremental Parsing
Description
Editors need parse trees that survive partial edits and errors.
Definitions & Key Terms
- Error node: Node inserted when input does not match grammar.
- Incremental parsing: Update only the affected subtree after edits.
- Recovery rule: Grammar rule that allows fallback.
Mental Model Diagram (ASCII)
Before edit: [CST]
Edit region -> reparse -> [CST'] with error nodes
How It Works (Step-by-Step)
- Define grammar that accepts partial constructs.
- Use
ERRORnodes for recovery instead of failing entirely. - Ensure common mistakes still produce a tree.
- Test by editing files with syntax errors.
Minimal Concrete Example
(statement) -> assignment | expression | ERROR
Common Misconceptions
- “Errors should fail parsing” -> Editors need trees even with errors.
- “Incremental parsing is automatic” -> You must design for it.
Check-Your-Understanding Questions
- Explain why error nodes are useful in an editor.
- Predict the parse tree for an incomplete
if (. - Explain how incremental parsing improves performance.
Where You’ll Apply It
- See §3.6 edge cases and §5.10 Phase 3.
- Also used in P03-neovim-gui-client.
2.5 Query Files and Highlight Captures
Description
Queries map syntax nodes to highlight groups for Neovim.
Definitions & Key Terms
- Query: Pattern matching syntax nodes.
- Capture: Named label for matched nodes.
- Highlights.scm: Query file for highlight groups.
Mental Model Diagram (ASCII)
(node) @keyword
(identifier) @variable
How It Works (Step-by-Step)
- Inspect parse tree with
tree-sitter parse. - Write highlight queries to capture node types.
- Map captures to Neovim highlight groups.
- Verify with
:InspectTreein Neovim.
Minimal Concrete Example
(function_declaration name: (identifier) @function)
"if" @keyword
Common Misconceptions
- “Queries are optional” -> Without them, no highlighting.
- “Captures are arbitrary” -> They map to known highlight groups.
Check-Your-Understanding Questions
- Explain why captures map to highlight groups.
- Predict what happens if a capture name is misspelled.
- Explain how to highlight only keywords.
Where You’ll Apply It
- See §3.1 outcomes and §5.10 Phase 3.
- Also used in P06-neovim-lite-capstone.
2.6 Testing with tree-sitter CLI and Corpus Tests
Description
Grammar tests ensure stability and prevent regressions.
Definitions & Key Terms
- Corpus test: Input/output examples checked by Tree-sitter.
tree-sitter test: Command to validate grammar outputs.
Mental Model Diagram (ASCII)
Input file -> expected CST -> compare -> pass/fail
How It Works (Step-by-Step)
- Create
corpus/*.txtwith input and expected CST. - Run
tree-sitter test. - Fix grammar until tests pass.
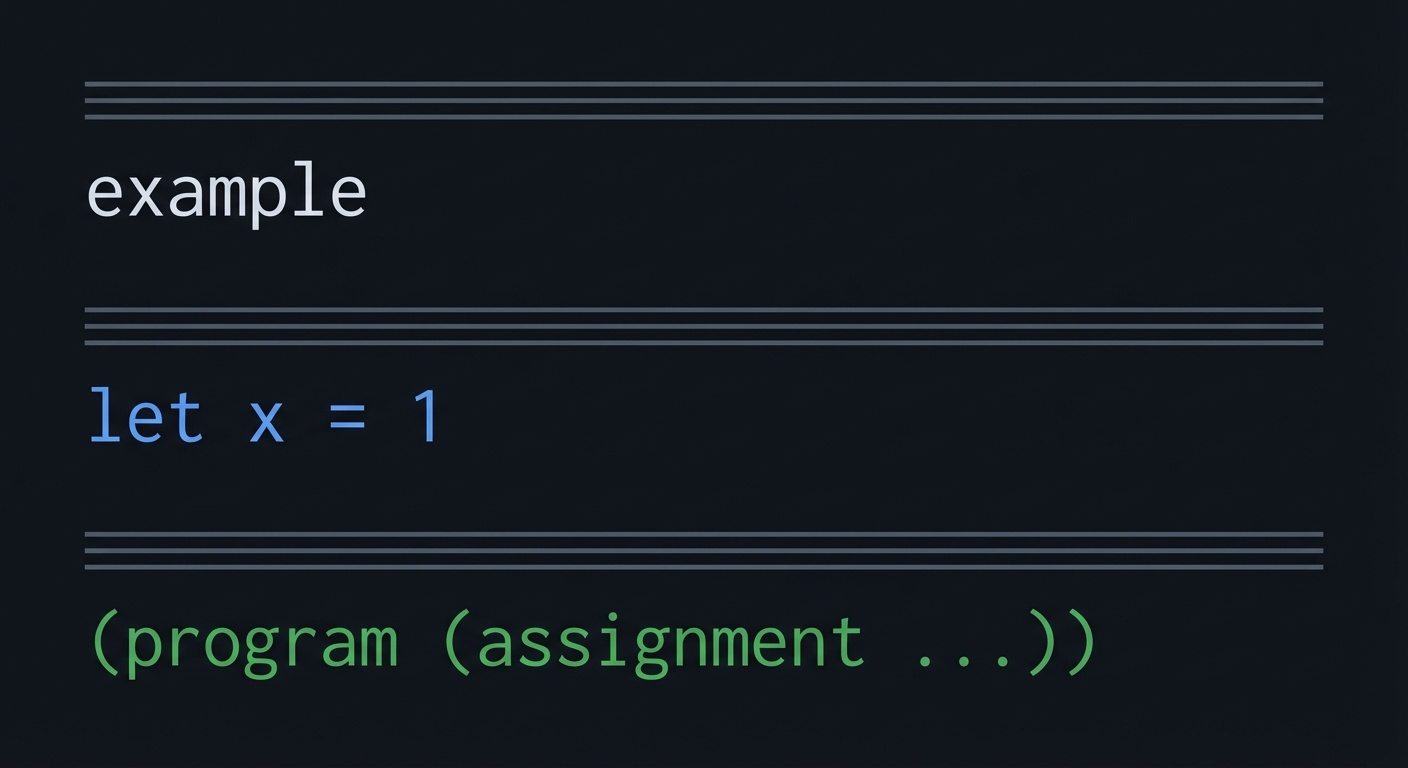
Minimal Concrete Example
===
example
===
let x = 1
---
(program (assignment ...))
Common Misconceptions
- “Manual inspection is enough” -> Tests catch regressions.
- “Corpus tests are optional” -> They are critical for long-term stability.
Check-Your-Understanding Questions
- Explain why corpus tests are important for grammar evolution.
- Predict what happens if the CST changes after a rule tweak.
- Explain how to update corpus tests safely.
Where You’ll Apply It
- See §6 testing and §5.10 Phase 3.
- Also used in P05-lsp-server.
3. Project Specification
3.1 What You Will Build
A Tree-sitter grammar for a custom language “xyl” with:
- Statements, expressions, and functions
- Strings, numbers, identifiers
- Highlight and fold queries
Included: core grammar, queries, basic error recovery. Excluded: full language tooling or LSP features.
3.2 Functional Requirements
- Grammar parses valid
xylfiles. - Highlight queries map keywords, strings, and functions.
- Folding queries identify blocks.
- Error recovery keeps CST usable with syntax errors.
3.3 Non-Functional Requirements
- Performance: Incremental parsing for large files.
- Reliability: No unresolved conflicts.
- Usability: Clear highlight groups and folds.
3.4 Example Usage / Output
$ tree-sitter parse examples/sample.xyl
(program (function_declaration name: (identifier) ...))
3.5 Data Formats / Schemas / Protocols
grammar.jsfor syntax rules.queries/xyl/highlights.scmfor highlights.queries/xyl/folds.scmfor folds.
3.6 Edge Cases
- Unterminated strings.
- Nested expressions with ambiguous operators.
- Incomplete block at EOF.
3.7 Real World Outcome
You can open .xyl files in Neovim with proper syntax highlighting.
3.7.1 How to Run (Copy/Paste)
npm install
tree-sitter generate
nvim examples/sample.xyl
3.7.2 Golden Path Demo (Deterministic)
- Use
examples/sample.xylwith fixed content. - Run
tree-sitter parseand compare to expected output.
Expected:
- Parse tree matches
corpus/sample.txtexactly.
3.7.3 Failure Demo
$ tree-sitter generate
Error: Unresolved conflict for symbol "expression"
Exit code: 1
Exit codes:
0success1grammar conflict2parse failure
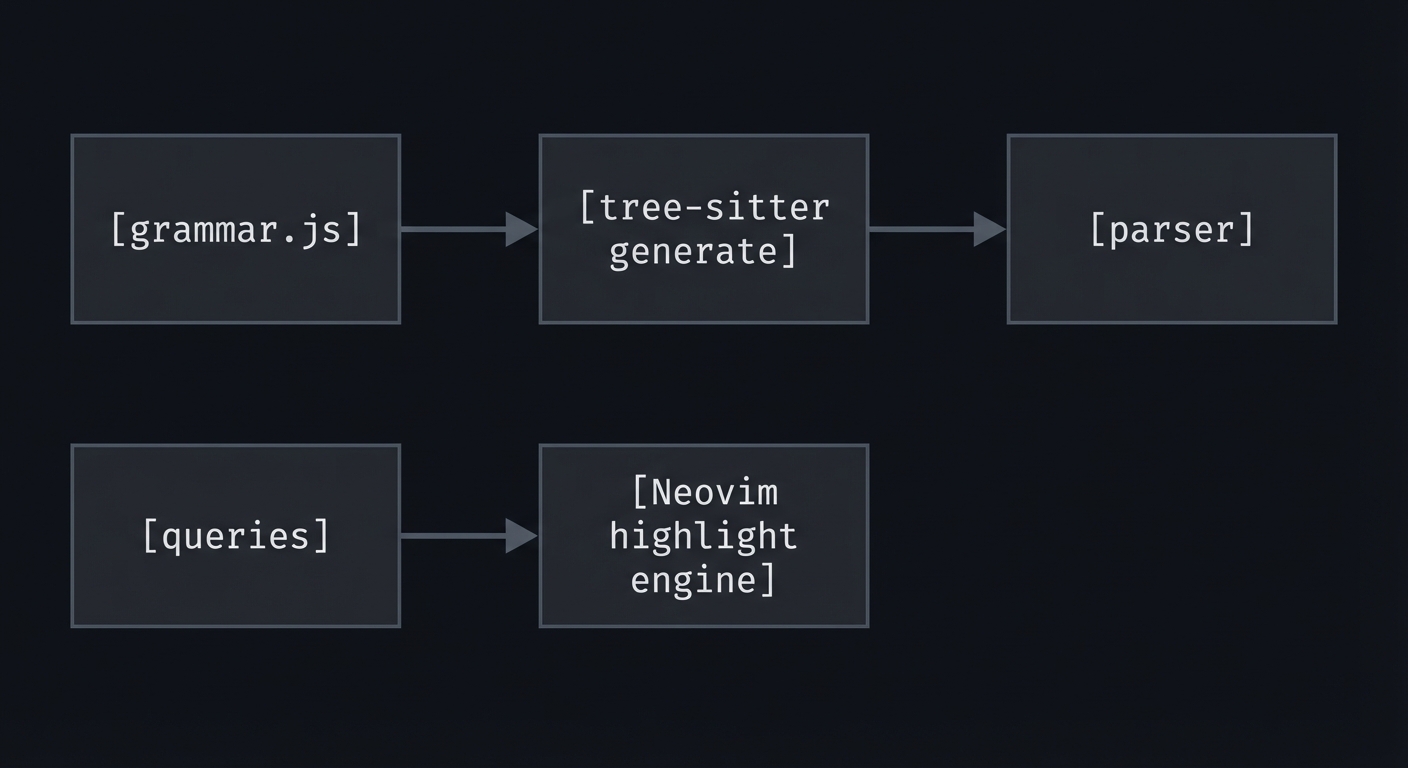
4. Solution Architecture
4.1 High-Level Design
[grammar.js] -> [tree-sitter generate] -> [parser]
[queries] -> [Neovim highlight engine]
4.2 Key Components
| Component | Responsibility | Key Decisions |
|---|---|---|
| Grammar | Rules + precedence | Minimal conflicts |
| Lexer | Tokens and keywords | Regex vs external scanner |
| Queries | Highlight + fold captures | Stable capture names |
| Tests | Corpus verification | Coverage of syntax |
4.3 Data Structures (No Full Code)
CST nodes: program, function_declaration, block, expression
4.4 Algorithm Overview
Key Algorithm: Expression Precedence
- Define base expressions (numbers, identifiers).
- Define binary expressions with
prec.left. - Ensure higher precedence operators have higher
prec.
Complexity Analysis:
- Time: O(n) per parse pass
- Space: O(n) for CST
5. Implementation Guide
5.1 Development Environment Setup
node --version
npm --version
tree-sitter --version
5.2 Project Structure
/tree-sitter-xyl/
├── grammar.js
├── package.json
├── queries/
│ └── xyl/
│ ├── highlights.scm
│ └── folds.scm
├── corpus/
│ └── sample.txt
└── examples/
└── sample.xyl
5.3 The Core Question You’re Answering
“How do we describe a language precisely enough that the editor can parse it in real time?”
5.4 Concepts You Must Understand First
Stop and research these before coding:
- CFG basics and ambiguity
- Tree-sitter precedence rules
- Query capture names
5.5 Questions to Guide Your Design
- What are the minimal syntax constructs for your language?
- Where is ambiguity likely (binary ops, call vs grouping)?
- What highlight groups matter most for readability?
5.6 Thinking Exercise
Design a tiny task-list language and list the node types you would need:
- task
- tag
- due_date
5.7 The Interview Questions They’ll Ask
- Why is incremental parsing valuable in editors?
- How do you resolve grammar conflicts in Tree-sitter?
- What is the difference between CST and AST?
5.8 Hints in Layers
Hint 1: Start minimal Define only program, statement, and expression.
Hint 2: Add precedence carefully
Use prec.left for operators.
Hint 3: Write corpus tests early They will guide your grammar updates.
Hint 4: Queries last Stabilize grammar before writing highlight queries.
5.9 Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Parsing | Engineering a Compiler | Ch. 2-4 |
| Syntax trees | Compilers: Principles and Practice | Ch. 4 |
| DSL design | Language Implementation Patterns | Ch. 1-2 |
5.10 Implementation Phases
Phase 1: Grammar Skeleton (2-3 days)
Goals:
- Basic CFG
- Sample parsing
Tasks:
- Define tokens and identifiers.
- Add core statement forms.
- Generate parser and parse sample input.
Checkpoint: tree-sitter parse works on sample files.
Phase 2: Precedence and Error Recovery (2-3 days)
Goals:
- Resolve conflicts
- Add error nodes
Tasks:
- Add precedence rules for expressions.
- Introduce error recovery rules.
- Update corpus tests.
Checkpoint: No unresolved conflicts.
Phase 3: Queries and Integration (1-2 days)
Goals:
- Highlights and folds
Tasks:
- Write highlight queries.
- Add fold queries.
- Load grammar in Neovim runtime.
Checkpoint: Neovim highlights .xyl correctly.
5.11 Key Implementation Decisions
| Decision | Options | Recommendation | Rationale |
|---|---|---|---|
| Ambiguity resolution | precedence, grammar refactor | precedence + refactor | clearer parse trees |
| Error handling | strict, permissive | permissive | better editor UX |
| Query scope | minimal, rich | minimal first | stabilize grammar |
6. Testing Strategy
6.1 Test Categories
| Category | Purpose | Examples |
|---|---|---|
| Grammar Tests | Validate parse output | corpus tests |
| Integration Tests | Neovim highlighting | open files |
| Edge Case Tests | Broken syntax | unterminated strings |
6.2 Critical Test Cases
- Nested expressions with mixed precedence.
- Unterminated string errors still produce CST.
- Fold queries match blocks.
6.3 Test Data
corpus/
sample.txt
errors.txt
7. Common Pitfalls & Debugging
7.1 Frequent Mistakes
| Pitfall | Symptom | Solution |
|---|---|---|
| Grammar conflict | generate fails |
Add precedence or refactor |
| No highlighting | Queries not loaded | Check runtimepath |
| Overlapping tokens | Wrong parse | Adjust regexes |
7.2 Debugging Strategies
- Use
tree-sitter parsefrequently. - Inspect parse trees with
:InspectTreein Neovim. - Add corpus tests for every new feature.
7.3 Performance Traps
- Excessive use of
choicewith many alternatives. - Highly ambiguous rules causing backtracking.
8. Extensions & Challenges
8.1 Beginner Extensions
- Add comments and highlight them.
- Add basic string interpolation support.
8.2 Intermediate Extensions
- Add external scanner for complex tokens.
- Add language injection queries.
8.3 Advanced Extensions
- Add error recovery tuned for common mistakes.
- Generate an AST for use by an LSP.
9. Real-World Connections
9.1 Industry Applications
- Syntax highlighting engines: Tree-sitter is used in Neovim, Helix.
- IDE tooling: Grammars enable folding, navigation, and linting.
9.2 Related Open Source Projects
- tree-sitter-javascript: Example of complex grammar.
- nvim-treesitter: Neovim integration layer.
9.3 Interview Relevance
- Compiler fundamentals: CFG, parsing, ambiguity.
- Language tooling: highlighting and editor integration.
10. Resources
10.1 Essential Reading
- Tree-sitter documentation (grammar and queries)
- Engineering a Compiler - Ch. 2-4
10.2 Video Resources
- Tree-sitter grammar walkthroughs (search: “tree-sitter grammar tutorial”)
10.3 Tools & Documentation
tree-sitter generatetree-sitter test- Neovim
:help treesitter
10.4 Related Projects in This Series
- P05 - LSP Server: uses parse trees
- P06 - Neovim Lite Capstone: integrates Tree-sitter
11. Self-Assessment Checklist
11.1 Understanding
- I can explain CFGs and precedence rules.
- I can write highlight queries for a CST.
- I can explain incremental parsing.
11.2 Implementation
- Grammar generates without conflicts.
- Highlights and folds work in Neovim.
- Errors do not break the CST.
11.3 Growth
- I can add a new language feature end-to-end.
- I can explain this project in an interview.
12. Submission / Completion Criteria
Minimum Viable Completion:
- Grammar parses sample files.
- Highlight queries work in Neovim.
tree-sitter testpasses.
Full Completion:
- All minimum criteria plus:
- Error recovery handles incomplete code.
- Fold queries work correctly.
Excellence (Going Above & Beyond):
- External scanner for complex tokens.
- Language injection queries.
13. Determinism and Reproducibility Notes
- Use fixed
examples/sample.xylandcorpus/sample.txtfor golden demos. - Do not include timestamps in test output.
- Failure demo uses a known conflict to produce a stable error.