Project 15: Compile Functional Language to LLVM/C
Project Overview
| Attribute | Details |
|---|---|
| Difficulty | Master |
| Time Estimate | 2-3 months |
| Primary Language | Haskell |
| Alternative Languages | OCaml, Rust |
| Knowledge Area | Compilers / Code Generation / Functional Language Implementation |
| Tools Required | GHC, LLVM (llvm-hs or llvm-hs-pure), Cabal/Stack |
| Primary Reference | “Compiling with Continuations” by Andrew Appel |
| Prerequisites | Projects 4 (Type Inference) and 14 (Lisp Interpreter), understanding of lambda calculus |
Learning Objectives
By completing this project, you will be able to:
- Implement Hindley-Milner type inference to statically type a functional language before compilation
- Perform closure conversion to transform higher-order functions into first-order code with explicit closures
- Apply lambda lifting to transform local functions into global functions with captured variables as parameters
- Generate LLVM IR for low-level representation of functional programs
- Implement tail call optimization at the compiler level
- Handle memory management with basic garbage collection or reference counting
- Understand the compilation pipeline from source to executable
Deep Theoretical Foundation
Why Compile Functional Languages?
Interpreters are excellent for learning and rapid development, but they have fundamental performance limitations:
- Interpretation overhead: Every expression re-parsed, re-analyzed at runtime
- Dynamic dispatch: Function calls resolved at runtime, not compile time
- No low-level optimization: Cannot leverage CPU features, SIMD, branch prediction
- Memory overhead: AST structures consume more memory than compiled code
A compiler translates high-level functional code into efficient machine code. This project bridges the gap between abstract lambda calculus and concrete hardware.
The challenge: functional features like closures, currying, and higher-order functions have no direct machine-level representation. We must transform them into constructs that do.
The Compilation Pipeline
Source Code
|
v
[Lexer/Parser] -----> Abstract Syntax Tree (AST)
|
v
[Type Inference] ---> Typed AST
|
v
[Desugaring] -------> Core Language (simpler AST)
|
v
[Closure Conversion] -> Explicit Closures
|
v
[Lambda Lifting] ----> First-Order Functions
|
v
[CPS Transform] -----> Continuation-Passing Style (optional)
|
v
[Code Generation] ---> LLVM IR / C Code
|
v
[LLVM/GCC] ---------> Machine Code
|
v
Executable
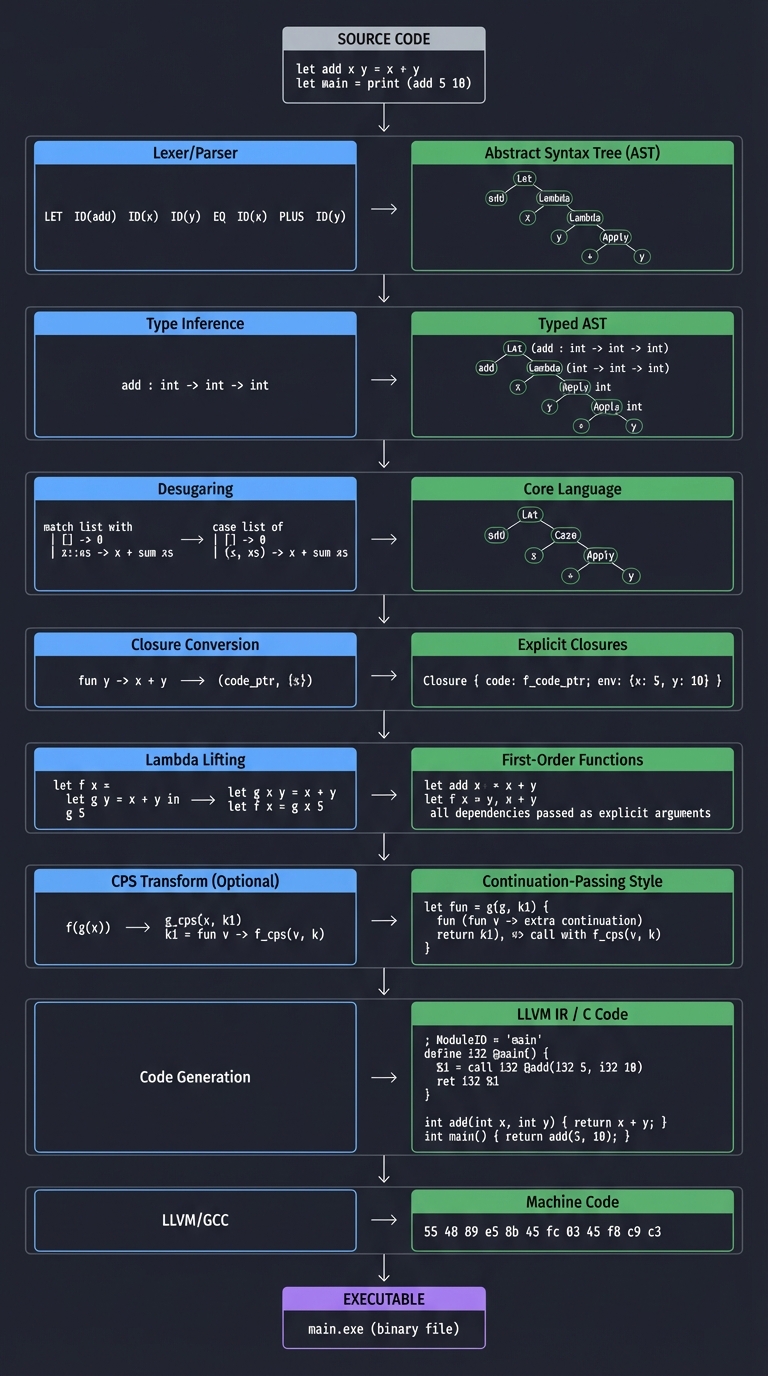
Each stage transforms the program into a lower-level representation until we reach machine code.
Source Language Design
We will compile a small functional language called “Mini-ML”:
-- Types
Int, Bool, a, b, (a -> b), (a, b)
-- Expressions
x -- variables
42 -- integer literals
true, false -- boolean literals
\x -> e -- lambda abstraction
e1 e2 -- application
let x = e1 in e2 -- let binding
let rec f x = e1 in e2 -- recursive binding
if e1 then e2 else e3 -- conditional
(e1, e2) -- pairs
fst e, snd e -- projections
e1 + e2, e1 - e2, ... -- arithmetic
e1 == e2, e1 < e2, ... -- comparison
Example program:
let rec factorial = \n ->
if n == 0 then 1
else n * factorial (n - 1)
in factorial 10
Hindley-Milner Type Inference
Hindley-Milner (HM) type inference infers types without explicit annotations. Key ideas:
Types:
Type = Int | Bool | TVar a | Type -> Type | (Type, Type)
Type Schemes (polymorphic types):
Scheme = forall a1 ... an. Type
Inference Algorithm (Algorithm W):
- Generate fresh type variables for unknowns
- Traverse AST generating constraints
- Solve constraints via unification
- Generalize to get polymorphic types
infer :: Env -> Expr -> (Subst, Type)
-- Variables: lookup in environment, instantiate scheme
infer env (Var x) =
let scheme = lookup x env
ty = instantiate scheme -- replace forall vars with fresh vars
in (emptySubst, ty)
-- Lambda: infer body with parameter added to env
infer env (Lam x body) =
let alpha = freshTVar
env' = extend env x (Forall [] alpha)
(s, t) = infer env' body
in (s, apply s alpha :-> t)
-- Application: infer function and argument, unify
infer env (App e1 e2) =
let (s1, t1) = infer env e1
(s2, t2) = infer (apply s1 env) e2
alpha = freshTVar
s3 = unify (apply s2 t1) (t2 :-> alpha)
in (s3 `compose` s2 `compose` s1, apply s3 alpha)
-- Let: infer binding, generalize, infer body
infer env (Let x e1 e2) =
let (s1, t1) = infer env e1
scheme = generalize (apply s1 env) t1
(s2, t2) = infer (extend (apply s1 env) x scheme) e2
in (s2 `compose` s1, t2)
Unification:
unify :: Type -> Type -> Subst
unify (TVar a) t = bindVar a t
unify t (TVar a) = bindVar a t
unify (t1 :-> t2) (s1 :-> s2) =
let su1 = unify t1 s1
su2 = unify (apply su1 t2) (apply su1 s2)
in compose su2 su1
unify Int Int = emptySubst
unify Bool Bool = emptySubst
unify t1 t2 = error $ "Cannot unify " ++ show t1 ++ " with " ++ show t2
Occurs Check: Prevent infinite types like a = a -> b.
Let Polymorphism: In let x = e1 in e2, we generalize x’s type to a scheme before checking e2. This is why:
let id = \x -> x in (id 1, id true)
is valid—id gets type forall a. a -> a.
Closure Conversion
Higher-order functions with free variables cannot directly become machine functions. Consider:
let add = \x -> (\y -> x + y)
let add5 = add 5
add5 10 -- returns 15
The inner lambda \y -> x + y references x, which is not in scope when the lambda is called. We must capture x in a closure.
Before closure conversion:
\y -> x + y
After closure conversion:
makeClosure(closureFunc, {x = x})
where closureFunc(env, y) = env.x + y
A closure is:
- A function pointer (the “code”)
- An environment record (captured variables)
Algorithm:
- For each lambda, find its free variables
- Create a closure record type containing those variables
- Convert the lambda body to take the environment as first argument
- At lambda creation, build the closure record
-- Find free variables
freeVars :: Expr -> Set String
freeVars (Var x) = singleton x
freeVars (Lam x body) = freeVars body `difference` singleton x
freeVars (App e1 e2) = freeVars e1 `union` freeVars e2
freeVars (Let x e1 e2) = freeVars e1 `union` (freeVars e2 `difference` singleton x)
...
-- Closure conversion
data CExpr
= CVar String
| CApp CExpr CExpr
| CLet String CExpr CExpr
| CMakeClosure String [String] -- function name, captured vars
| CEnvRef Int -- reference to captured variable
| ...
closureConvert :: Expr -> CExpr
closureConvert (Lam x body) =
let fvs = toList (freeVars body `difference` singleton x)
funcName = freshName "closure"
body' = convertBody fvs x body
in CMakeClosure funcName fvs
Lambda Lifting
After closure conversion, we can perform lambda lifting to move all functions to top level:
Before:
let f = \x ->
let g = \y -> x + y
in g 5
After lambda lifting:
g_lifted(x, y) = x + y
f_lifted(x) = g_lifted(x, 5)
The key insight: captured variables become additional parameters.
Algorithm:
- Collect all lambdas in the program
- For each lambda, add free variables as extra parameters
- Replace lambda with call to lifted function, passing free vars
Combined with closure conversion, this gives us first-order code suitable for machine execution.
Continuation-Passing Style (CPS)
CPS makes control flow explicit. Every function takes an extra argument: the continuation (what to do with the result).
Direct style:
let result = f(x) in g(result)
CPS:
f(x, \result -> g(result, halt))
Why CPS?
- Tail calls become obvious: A call in CPS is always in tail position
- No return addresses: Continuations explicitly handle control flow
- Simplifies code generation: No stack needed for function returns
- Enables optimizations: Inlining, dead code elimination become easier
CPS Transformation:
data CPS
= CPSHalt Value
| CPSCall Value [Value] Var CPS -- f(args, \x -> k)
| CPSPrimOp Op [Value] Var CPS -- primop(args, \x -> k)
| CPSIf Value CPS CPS
cpsTransform :: Expr -> (Value -> CPS) -> CPS
cpsTransform (Lit n) k = k (VLit n)
cpsTransform (Var x) k = k (VVar x)
cpsTransform (App e1 e2) k =
cpsTransform e1 (\v1 ->
cpsTransform e2 (\v2 ->
let r = freshVar
in CPSCall v1 [v2] r (k (VVar r))))
cpsTransform (Lam x body) k =
let kVar = freshVar
body' = cpsTransform body (\v -> CPSHalt v)
in k (VLam x kVar body')
LLVM IR Basics
LLVM (Low-Level Virtual Machine) is a compiler infrastructure that provides:
- A well-defined intermediate representation (IR)
- Powerful optimization passes
- Code generation for multiple architectures
LLVM IR Features:
- Static single assignment (SSA) form
- Typed (everything has a type)
- Infinite virtual registers
- First-class functions (sort of)
- Garbage collection support
Basic LLVM IR:
; Define a function
define i32 @add(i32 %a, i32 %b) {
entry:
%result = add i32 %a, %b
ret i32 %result
}
; Call a function
define i32 @main() {
entry:
%x = call i32 @add(i32 3, i32 4)
ret i32 %x
}
LLVM Types:
i1,i8,i32,i64: Integer typesfloat,double: Floating pointptr: Pointer (opaque in modern LLVM){ i32, ptr }: Struct types[10 x i32]: Array typesi32 (i32, i32)*: Function pointer types
For our compiler:
- Closures become structs:
{ ptr, ... }(code pointer + captured vars) - Function calls become indirect calls through closure’s code pointer
- Heap allocation for closures (needs GC or manual management)
Memory Management
Functional languages allocate heavily (every closure, every data structure). We need memory management.
Options:
- Manual allocation (simple, leaky): Allocate but never free
- Fine for short-running programs
- Memory grows without bound
- Reference counting: Track how many references to each object
- Free when count reaches zero
- Problem: cycles (A -> B -> A never freed)
- Solution: weak references or cycle detection
- Tracing garbage collection: Periodically find all reachable objects
- Mark-and-sweep: Mark all reachable, sweep unmarked
- Copying: Copy all reachable to new space, abandon old
- Generational: Young objects collected more often
- Using Boehm GC: Conservative GC library
- Drop-in replacement for malloc
- Automatically collects garbage
- Easy to integrate
For this project, we recommend starting with Boehm GC:
#include <gc.h>
void* ptr = GC_malloc(size); // No need to free!
Tail Call Optimization
A tail call is a function call whose result is immediately returned:
-- Tail call (can optimize)
f x = g (x + 1)
-- Not a tail call (uses result)
f x = 1 + g x
Why TCO matters: Without it, recursive functions consume stack proportional to recursion depth.
Implementation:
- In CPS: All calls are tail calls (no stack growth)
- In direct style: Check if call is in tail position, use
jmpinstead ofcall - LLVM: Use
musttailattribute:musttail call i32 @factorial(i32 %n_minus_1, i32 %new_acc)
Trampoline approach (for non-TCO targets):
typedef struct {
int tag; // 0 = value, 1 = thunk
union {
int value;
struct { void* func; void* arg; } thunk;
};
} Bounce;
int trampoline(Bounce b) {
while (b.tag == 1) {
b = ((Bounce(*)(void*))b.thunk.func)(b.thunk.arg);
}
return b.value;
}
Calling Conventions
How do we call functions? The calling convention defines:
- How arguments are passed (registers vs stack)
- Who saves registers (caller vs callee)
- How return values are passed
For closures:
call(closure, arg1, arg2, ...)
= call(closure.code, closure.env, arg1, arg2, ...)
The environment pointer is an implicit first argument.
LLVM calling convention for closures:
; Closure struct: { code_ptr, env_ptr }
%closure = type { ptr, ptr }
; Closure call
define i32 @call_closure(ptr %clos, i32 %arg) {
%code_ptr = getelementptr %closure, ptr %clos, i32 0, i32 0
%code = load ptr, ptr %code_ptr
%env_ptr = getelementptr %closure, ptr %clos, i32 0, i32 1
%env = load ptr, ptr %env_ptr
%result = call i32 %code(ptr %env, i32 %arg)
ret i32 %result
}
Optimization Opportunities
Once in IR form, many optimizations become possible:
- Inlining: Replace function call with function body
- Constant folding: Evaluate constant expressions at compile time
- Dead code elimination: Remove unused computations
- Common subexpression elimination: Compute repeated expressions once
- Strength reduction: Replace expensive ops with cheaper ones
- Loop optimizations: Unrolling, invariant code motion
LLVM provides these optimizations—we just need to generate reasonable IR.
Complete Project Specification
What You Are Building
A compiler called miniml that compiles Mini-ML to native executables:
miniml compile program.ml -o program
./program
Language Features
-- Core expressions
42, true, false, "string" -- literals
x -- variables
\x -> e -- lambda
e1 e2 -- application
let x = e1 in e2 -- let binding
let rec f = \x -> e in e' -- recursive binding
if e1 then e2 else e3 -- conditional
(e1, e2) -- pairs
fst e, snd e -- projections
-- Arithmetic and comparison
+, -, *, / -- arithmetic
==, /=, <, >, <=, >= -- comparison
&&, ||, not -- boolean operations
-- Optional: Algebraic data types
data List a = Nil | Cons a (List a)
case e of { Nil -> e1 ; Cons x xs -> e2 }
Compilation Stages
Source (.ml)
|
[Parser] -----------> Expr (AST)
|
[Type Inference] ---> TypedExpr (AST with types)
|
[Desugar] ----------> Core (simplified AST)
|
[Closure Convert] --> CCExpr (explicit closures)
|
[Lambda Lift] ------> LLExpr (all functions top-level)
|
[CodeGen] ----------> LLVM Module
|
[LLVM] ------------> Object file (.o)
|
[Linker] ----------> Executable
Expected Output
$ cat factorial.ml
let rec factorial = \n ->
if n == 0 then 1
else n * factorial (n - 1)
in
factorial 10
$ miniml compile factorial.ml -o factorial
Parsing... done
Type checking... factorial : Int -> Int
Closure converting... done
Lambda lifting... done
Generating LLVM IR... done
Compiling to native... done
$ ./factorial
3628800
$ miniml compile factorial.ml --emit-llvm
; ModuleID = 'factorial'
define i64 @factorial(i64 %n) {
entry:
%cmp = icmp eq i64 %n, 0
br i1 %cmp, label %then, label %else
then:
ret i64 1
else:
%n_minus_1 = sub i64 %n, 1
%rec_result = call i64 @factorial(i64 %n_minus_1)
%result = mul i64 %n, %rec_result
ret i64 %result
}
define i64 @main() {
entry:
%result = call i64 @factorial(i64 10)
ret i64 %result
}
Solution Architecture
Module Structure
src/
MiniML/
Syntax/
AST.hs -- Surface syntax AST
Core.hs -- Core language
Parser.hs -- Parser (Megaparsec)
Lexer.hs -- Lexer
Types/
Type.hs -- Type definitions
Infer.hs -- Type inference (Algorithm W)
Unify.hs -- Unification
Subst.hs -- Substitutions
Transform/
Desugar.hs -- Desugar to Core
ClosureConvert.hs -- Closure conversion
LambdaLift.hs -- Lambda lifting
CPS.hs -- Optional CPS transform
CodeGen/
LLVM.hs -- LLVM IR generation
Runtime.hs -- Runtime support
Driver/
Compile.hs -- Compilation pipeline
CLI.hs -- Command-line interface
Main.hs -- Entry point
runtime/
runtime.c -- C runtime (GC, printing, etc.)
runtime.h
Core Data Types
-- Surface syntax
data Expr
= ELit Lit
| EVar String
| ELam String Expr
| EApp Expr Expr
| ELet String Expr Expr
| ELetRec String Expr Expr
| EIf Expr Expr Expr
| EPair Expr Expr
| EFst Expr
| ESnd Expr
| EBinOp BinOp Expr Expr
deriving (Show)
-- Types
data Type
= TInt
| TBool
| TVar TyVar
| TFun Type Type
| TPair Type Type
deriving (Eq, Show)
data Scheme = Forall [TyVar] Type
deriving (Show)
-- Core language (after desugaring)
data Core
= CLit Lit
| CVar String
| CLam String Core
| CApp Core Core
| CLet String Core Core
| CIf Core Core Core
| CPrimOp PrimOp [Core]
deriving (Show)
-- After closure conversion
data CCExpr
= CCLit Lit
| CCVar String
| CCMakeClosure String [String] -- func name, captured vars
| CCCallClosure CCExpr [CCExpr]
| CCLet String CCExpr CCExpr
| CCIf CCExpr CCExpr CCExpr
| CCPrimOp PrimOp [CCExpr]
deriving (Show)
-- Top-level function (after lambda lifting)
data TopLevel
= TopFunc String [String] CCExpr -- name, params, body
deriving (Show)
Key Algorithms
Closure Conversion:
closureConvert :: Core -> State Int CCExpr
closureConvert (CLam x body) = do
body' <- closureConvert body
let fvs = toList $ freeVars (CLam x body)
funcName <- freshName "closure"
-- Register new top-level function
emitFunction funcName ("env" : x : []) (substituteEnv fvs body')
return $ CCMakeClosure funcName fvs
closureConvert (CApp e1 e2) = do
e1' <- closureConvert e1
e2' <- closureConvert e2
return $ CCCallClosure e1' [e2']
-- Other cases...
LLVM Code Generation:
genExpr :: CCExpr -> LLVM Operand
genExpr (CCLit (LInt n)) = return $ ConstantOperand (Int 64 n)
genExpr (CCVar x) = do
ptr <- lookupVar x
load ptr
genExpr (CCMakeClosure funcName captured) = do
-- Allocate closure struct
closSize <- closureSize (length captured)
ptr <- gcMalloc closSize
-- Store function pointer
funcPtr <- getFunction funcName
storeAt ptr 0 funcPtr
-- Store captured variables
forM_ (zip [1..] captured) $ \(i, var) -> do
val <- lookupVar var
storeAt ptr i val
return ptr
genExpr (CCCallClosure clos args) = do
closPtr <- genExpr clos
argVals <- mapM genExpr args
-- Load function pointer from closure
funcPtr <- loadAt closPtr 0
-- Load environment pointer
envPtr <- loadAt closPtr 1
-- Call with env as first arg
call funcPtr (envPtr : argVals)
genExpr (CCPrimOp op args) = do
vals <- mapM genExpr args
genPrimOp op vals
Phased Implementation Guide
Phase 1: Parser and AST (Week 1)
Goal: Parse Mini-ML source code into an AST.
Tasks:
- Define
ExprAST data type - Implement lexer with Megaparsec
- Implement parser for all expression forms
- Add pretty-printer for debugging
- Write parser tests
Validation:
parse "\\x -> x + 1" == ELam "x" (EBinOp Add (EVar "x") (ELit (LInt 1)))
Hints:
- Handle operator precedence carefully
- Support multi-line expressions
- Add source locations for error messages
Phase 2: Type Inference (Weeks 2-3)
Goal: Implement Hindley-Milner type inference.
Tasks:
- Define
TypeandSchemedata types - Implement substitution and composition
- Implement unification with occurs check
- Implement Algorithm W
- Add type error messages
- Test on polymorphic examples
Validation:
infer "\\x -> x" == Forall [a] (a -> a)
infer "\\f -> \\x -> f x" == Forall [a,b] ((a -> b) -> a -> b)
Hints:
- Use
Statemonad for fresh variable generation Either TypeErrorfor error handling- Generalization happens at let bindings only
Phase 3: Closure Conversion (Week 4)
Goal: Transform lambdas into explicit closures.
Tasks:
- Implement free variable analysis
- Define closure-converted AST
- Implement closure conversion algorithm
- Generate closure allocation code
- Transform function applications to closure calls
Validation:
Before: \x -> \y -> x + y
After: makeClosure("f1", []) where f1(env, x) = makeClosure("f2", [x])
and f2(env, y) = env[0] + y
Hints:
- Track which variables are from environment vs parameters
- Generate unique names for closure functions
- Test with nested lambdas
Phase 4: Lambda Lifting (Week 5)
Goal: Move all functions to top level.
Tasks:
- Collect all closure functions
- Generate top-level function definitions
- Replace closure creation with allocation + init
- Handle recursive functions specially
- Verify all functions are now global
Validation: No nested lambdas remain; all functions at top level.
Hints:
- Maintain a map from closure names to their definitions
- Recursive closures need special handling (store function pointer after allocation)
Phase 5: LLVM Code Generation (Weeks 6-8)
Goal: Generate LLVM IR from closure-converted code.
Tasks:
- Set up llvm-hs-pure or llvm-hs library
- Generate code for literals and arithmetic
- Implement closure struct representation
- Generate code for closure creation
- Generate code for closure calls
- Implement primitive operations
- Create main function
Validation:
miniml factorial.ml --emit-llvm | lli
# Outputs: 3628800
Hints:
- Start with a minimal runtime (just printing)
- Use
i64for all integers initially - Test each construct in isolation
Phase 6: Runtime and GC (Weeks 9-10)
Goal: Add runtime support and memory management.
Tasks:
- Create C runtime with print functions
- Integrate Boehm GC for allocation
- Handle program startup (call main)
- Add error handling (division by zero, etc.)
- Link runtime with generated code
Validation: Programs run without memory leaks (check with valgrind).
Hints:
- Keep runtime minimal
- Use GC_malloc for all heap allocations
- Compile runtime to object file, link with generated code
Phase 7: Optimization and Polish (Weeks 11-12)
Goal: Optimize generated code and improve UX.
Tasks:
- Add LLVM optimization passes
- Implement tail call optimization
- Improve error messages
- Add
--emit-llvmand--emit-asmflags - Handle multiple source files
- Write comprehensive tests
Validation: Factorial of 1,000,000 runs without stack overflow (with TCO).
Hints:
- LLVM’s optimization passes are powerful—use them
musttailfor tail calls- Profile and optimize hot paths
Testing Strategy
Unit Tests
-- Parser tests
testParseLambda = parse "\\x -> x" @?= Right (ELam "x" (EVar "x"))
testParseApp = parse "f x y" @?= Right (EApp (EApp (EVar "f") (EVar "x")) (EVar "y"))
-- Type inference tests
testInferIdent = inferType "\\x -> x" @?= Right (Forall [a] (TVar a :-> TVar a))
testInferConst = inferType "\\x -> \\y -> x" @?=
Right (Forall [a,b] (TVar a :-> TVar b :-> TVar a))
-- Closure conversion tests
testClosureSimple = closureConvert (ELam "x" (EVar "x")) @?=
CCMakeClosure "f0" []
testClosureCapture = closureConvert (ELam "x" (ELam "y" (EBinOp Add (EVar "x") (EVar "y")))) @?=
-- Should capture x in inner closure
...
Integration Tests
Create test files and verify output:
# test_arith.ml
let x = 2 + 3 in x * 4
# Expected output: 20
integrationTest :: FilePath -> String -> Test
integrationTest file expected = TestCase $ do
compile file "test_output"
result <- readProcess "./test_output" [] ""
assertEqual file expected result
Property-Based Tests
-- Type inference preserves semantics
prop_typePreservation :: Expr -> Property
prop_typePreservation e =
isRight (inferType e) ==>
eval e == eval (compileAndRun e)
-- Closure conversion preserves semantics
prop_closureCorrect :: Expr -> Property
prop_closureCorrect e =
interpret e == compileAndRun e
Common Pitfalls and Debugging
Pitfall 1: Wrong Free Variable Calculation
Symptom: Closures don’t capture the right variables.
Cause: Forgetting to remove bound variables.
Solution:
freeVars (ELam x body) = freeVars body `difference` singleton x
-- NOT: freeVars body (wrong!)
Pitfall 2: Closure Self-Reference
Symptom: Recursive closures segfault.
Cause: Closure tries to call itself before it’s fully constructed.
Solution:
-- Allocate first, then store function pointer
closPtr <- allocateClosure size
funcPtr <- getFunction funcName
storeAt closPtr 0 funcPtr -- Now we can store pointer to self
Pitfall 3: Type Inference Infinite Loop
Symptom: Type inference hangs on certain expressions.
Cause: Missing occurs check in unification.
Solution:
unify (TVar a) t
| a `occursIn` t = Left $ InfiniteType a t -- Occurs check!
| otherwise = Right [(a, t)]
Pitfall 4: LLVM Type Mismatches
Symptom: LLVM rejects generated IR with type errors.
Cause: Mixing up types (i32 vs i64, ptr vs value).
Solution:
- Always track types explicitly
- Use helper functions that ensure type consistency
- Validate IR with
opt -verify
Pitfall 5: Missing GC Roots
Symptom: Programs crash or produce garbage after GC.
Cause: Live pointers not visible to garbage collector.
Solution:
- Store all live pointers in GC-visible locations
- Use
GC_mallocfor all heap allocation - Consider using Boehm GC’s conservative scanning
Debugging Tips
- Emit intermediate representations: Add
--dump-core,--dump-closureflags - Test each stage: Verify parser, then type inference, then closure conversion, etc.
- Use
llifor testing: LLVM interpreter catches many IR errors - Compare with reference: Use GHC to verify expected behavior
- Add runtime tracing: Print when closures are created/called
Extensions and Challenges
Extension 1: Algebraic Data Types
Add sum types and pattern matching:
data List a = Nil | Cons a (List a)
let length = \xs ->
case xs of
Nil -> 0
Cons _ rest -> 1 + length rest
Requires:
- Type inference for ADTs
- Representation of constructors (tagged unions)
- Pattern match compilation (decision trees)
Extension 2: Polymorphic Recursion
Support polymorphic recursive functions:
let rec length = \xs ->
case xs of
Nil -> 0
Cons _ rest -> 1 + length rest -- length called polymorphically
Requires explicit type annotations or more sophisticated inference.
Extension 3: Separate Compilation
Support multiple source files:
-- Lib.ml
let square = \x -> x * x
-- Main.ml
import Lib
square 5
Requires:
- Module system
- Interface files
- Linking multiple object files
Extension 4: Optimizations
Implement optimizations:
- Inlining small functions
- Constant propagation
- Dead code elimination
- Unboxing specialized monomorphic code
Challenge: Self-Hosting
Write the compiler in Mini-ML itself:
-- In Mini-ML
let parse = \source -> ...
let typeCheck = \ast -> ...
let compile = \ast -> ...
let main = \() ->
let source = readFile "input.ml" in
let ast = parse source in
let typedAst = typeCheck ast in
compile typedAst
This is the ultimate test—your language can compile itself!
Real-World Connections
Where These Techniques Appear
- GHC (Haskell): Uses STG machine, a specialized closure representation
- OCaml: Direct-style compilation with efficient closures
- Rust closures: Compile to structs with captured variables
- JavaScript engines (V8): Closure optimization for performance
- Clang/LLVM: LLVM IR is the industry standard
Industry Applications
- Facebook Hack/HHVM: JIT compilation of PHP/Hack
- Apple Swift: LLVM-based, aggressive optimization
- WebAssembly compilers: Functional language to Wasm
- MLton: Whole-program optimizing SML compiler
- Graal/Truffle: Self-optimizing language implementations
What This Project Teaches You
- Compiler architecture (applicable to any language)
- Type system implementation (fundamental for language tools)
- Low-level code generation (useful for performance optimization)
- LLVM IR (industry-standard intermediate representation)
- Memory management strategies (important for systems programming)
Interview Questions
After completing this project, you should be able to answer:
- What is closure conversion and why is it necessary?
- Higher-order functions reference free variables
- Machine functions cannot access caller’s stack
- Solution: pack free variables into a data structure
- Closure = code pointer + environment
- How does Hindley-Milner type inference work?
- Generate constraints from expression structure
- Solve constraints via unification
- Generalize at let bindings (let polymorphism)
- Algorithm W or Algorithm J
- What is the difference between lambda lifting and closure conversion?
- Closure conversion: make closures explicit data structures
- Lambda lifting: move functions to top level, add params for free vars
- Often used together
- Lifting can avoid runtime closure allocation in some cases
- How do you implement tail call optimization?
- Identify tail position calls
- Reuse current stack frame instead of pushing new
- In LLVM:
musttailattribute - Alternative: CPS makes all calls tail calls
- What is CPS and what are its benefits for compilation?
- Continuation-passing style: explicit continuations
- Makes control flow explicit
- All calls become tail calls
- Easier to implement exceptions, generators, coroutines
- How does garbage collection work with closures?
- Closures contain pointers to captured values
- GC must trace through closure environments
- Conservative GC (Boehm) scans all memory for pointers
- Precise GC requires stack maps
- What is LLVM IR and why is it useful?
- Low-level intermediate representation
- Typed, SSA form
- Platform-independent
- Powerful optimization passes
- Easy code generation for multiple architectures
Self-Assessment Checklist
Before considering this project complete, verify:
- Parser handles all language constructs
- Type inference correctly infers polymorphic types
- Let polymorphism works (same function used at different types)
- Closure conversion correctly identifies free variables
- Closures capture their lexical environment
- Lambda lifting produces only top-level functions
- Generated LLVM IR is valid (passes
opt -verify) - Simple programs compile and run correctly
- Recursive functions work
- Higher-order functions work
- Tail recursive functions don’t overflow stack (with TCO)
- Memory doesn’t grow unboundedly (GC works)
- Error messages are helpful
Resources
Essential Reading
| Topic | Resource | Notes |
|---|---|---|
| Compilation overview | “Modern Compiler Implementation in ML” by Andrew Appel | Comprehensive textbook |
| CPS and closures | “Compiling with Continuations” by Andrew Appel | Deep dive into CPS-based compilation |
| Type inference | “Types and Programming Languages” by Pierce, Ch. 22 | Hindley-Milner algorithm |
| LLVM | LLVM Language Reference Manual | Official IR documentation |
| llvm-hs | Hackage documentation | Haskell LLVM bindings |
| Garbage collection | “The Garbage Collection Handbook” by Jones et al. | Comprehensive GC reference |
Papers
- “The Definition of Standard ML” - Milner et al.
- “Practical Type Inference for Arbitrary-Rank Types” - Peyton Jones et al.
- “Orbit: An Optimizing Compiler for Scheme” - Kranz et al.
- “Making a Fast Curry” - Marlow & Peyton Jones
- “Lambda Lifting in Quadratic Time” - Morazán & Mulder
Books
- “Compilers: Principles, Techniques, and Tools” (Dragon Book) by Aho et al.
- “Engineering a Compiler” by Cooper & Torczon
- “Essentials of Programming Languages” by Friedman & Wand
- “Lisp in Small Pieces” by Queinnec
Online Resources
- LLVM Tutorial: Kaleidoscope - Official LLVM tutorial
- Write You a Haskell - Stephen Diehl’s compiler tutorial
- Implementing Functional Languages - SPJ’s tutorial
- An Incremental Approach to Compiler Construction - Ghuloum’s paper
Reference Implementations
- GHC: The Glasgow Haskell Compiler (production quality)
- MLton: Whole-program SML compiler
- Chicken Scheme: Scheme to C compiler
- Mini-Haskell compilers: Various tutorials online
“A programming language is low level when its programs require attention to the irrelevant.” - Alan Perlis
By completing this project, you will understand why functional languages require sophisticated compilation techniques—and you’ll have built a real compiler that transforms elegant lambda calculus into efficient machine code.