TECHNICAL DEBT AND REFACTORING AT SCALE
In 1992, Ward Cunningham coined the term Technical Debt to explain to non-technical stakeholders why a team's velocity was slowing down. He argued that shipping first-time code is like going into debt. A little debt speeds up development, as long as it's paid back promptly with a refactor.
Sprint: Technical Debt & Strategic Refactoring - Real World Projects
Goal: Develop a high-level engineering leadership mindset to identify, measure, and systematically dismantle technical debt without halting product delivery. You will deeply understand the “Financial” nature of software decay, learn to apply the Strangler Fig pattern at the architecture level, and build tools that provide the observability necessary to justify refactoring to non-technical stakeholders.
Why Technical Debt & Refactoring Matters
In 1992, Ward Cunningham coined the term “Technical Debt” to explain to non-technical stakeholders why a team’s velocity was slowing down. He argued that shipping first-time code is like going into debt. A little debt speeds up development, as long as it’s paid back promptly with a refactor.
At organizational scale (100+ engineers), technical debt is the “silent killer” of companies. It’s not just “messy code”—it’s a systemic inhibitor:
- The Linux Kernel manages millions of lines of C code using strict “pay-as-you-go” refactoring.
- 70% of software costs occur in the maintenance phase, mostly dealing with legacy debt.
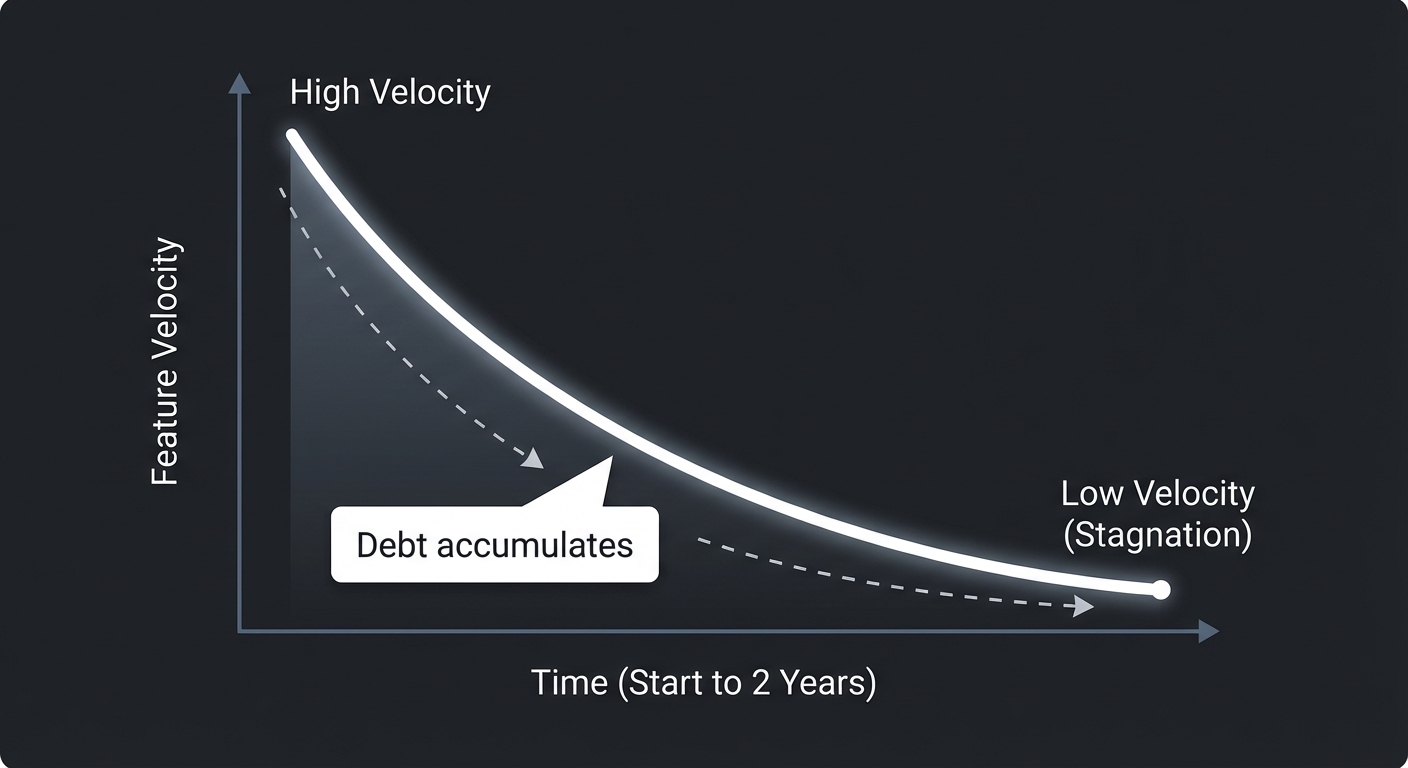
- Velocity decay: Without refactoring, a team’s ability to ship new features drops exponentially over time.
- The Talent Drain: Top engineers leave organizations where they spend 80% of their time fighting “spaghetti” instead of building features.
Feature Velocity over Time
High | *
| *
| *
| * (Debt accumulates)
| *
| *
Low | ***************** (Bankruptcy/Stagnation)
└──────────────────────────
Start 2 Years
The Financial Nature of Software
Every line of code you write is a liability. It must be maintained, tested, and eventually replaced. Technical debt is like a credit card:
- Principal: The effort required to “do it right” vs. “doing it fast.”
- Interest: The extra time you spend fighting bad abstractions every time you touch that code.
- Bankruptcy: When the interest is so high that you can no longer ship features at all.
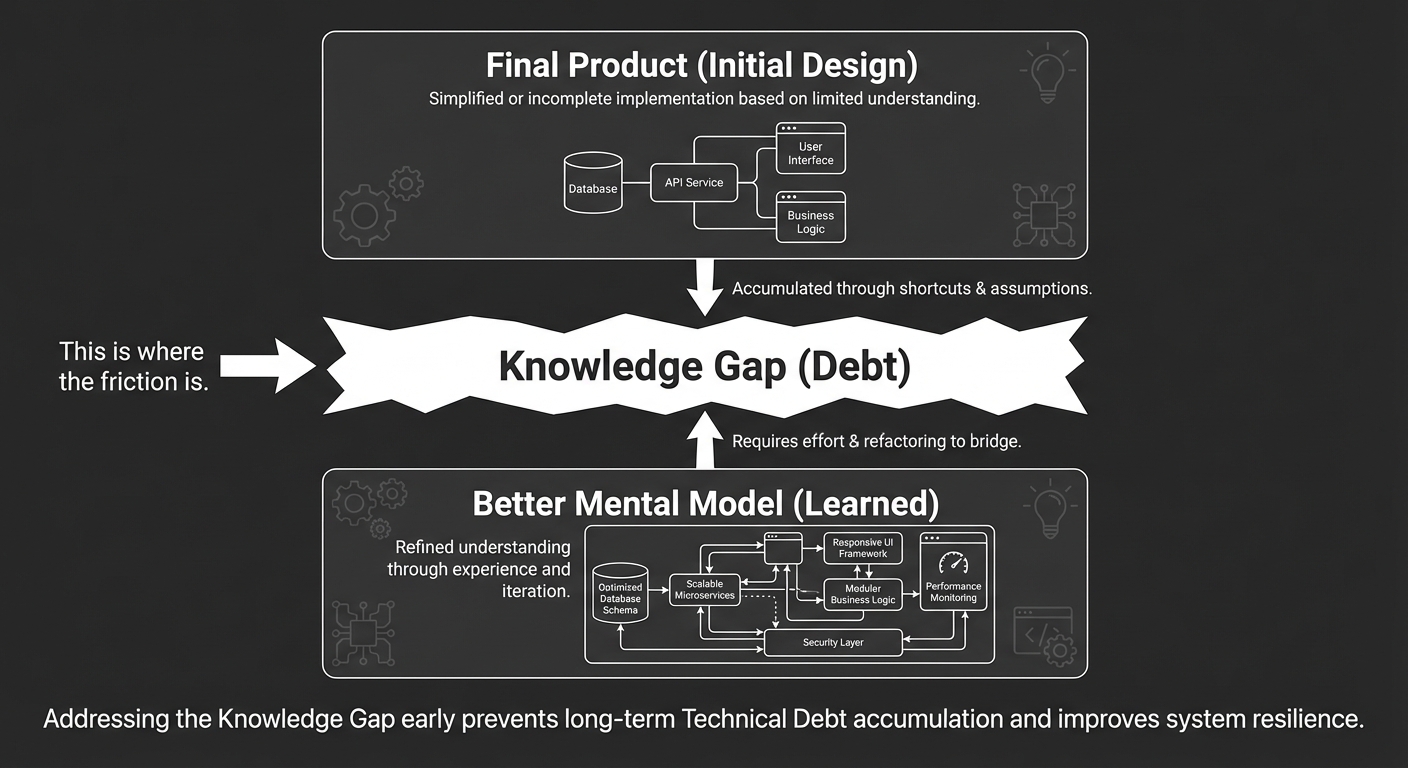
Why does this happen? Usually, it’s not “bad developers.” It’s Knowledge Gap: the team understands the problem better after they’ve built the first version. Refactoring is the process of updating the code to match that new, better understanding.
Knowledge vs. Implementation
┌──────────────────────────────────┐
│ Final Product (Initial Design) │
└────────────────┬─────────────────┘
│
Knowledge Gap (Debt) <─── This is where the friction is.
│
┌────────────────┴─────────────────┐
│ Better Mental Model (Learned) │
└──────────────────────────────────┘
Core Concept Analysis
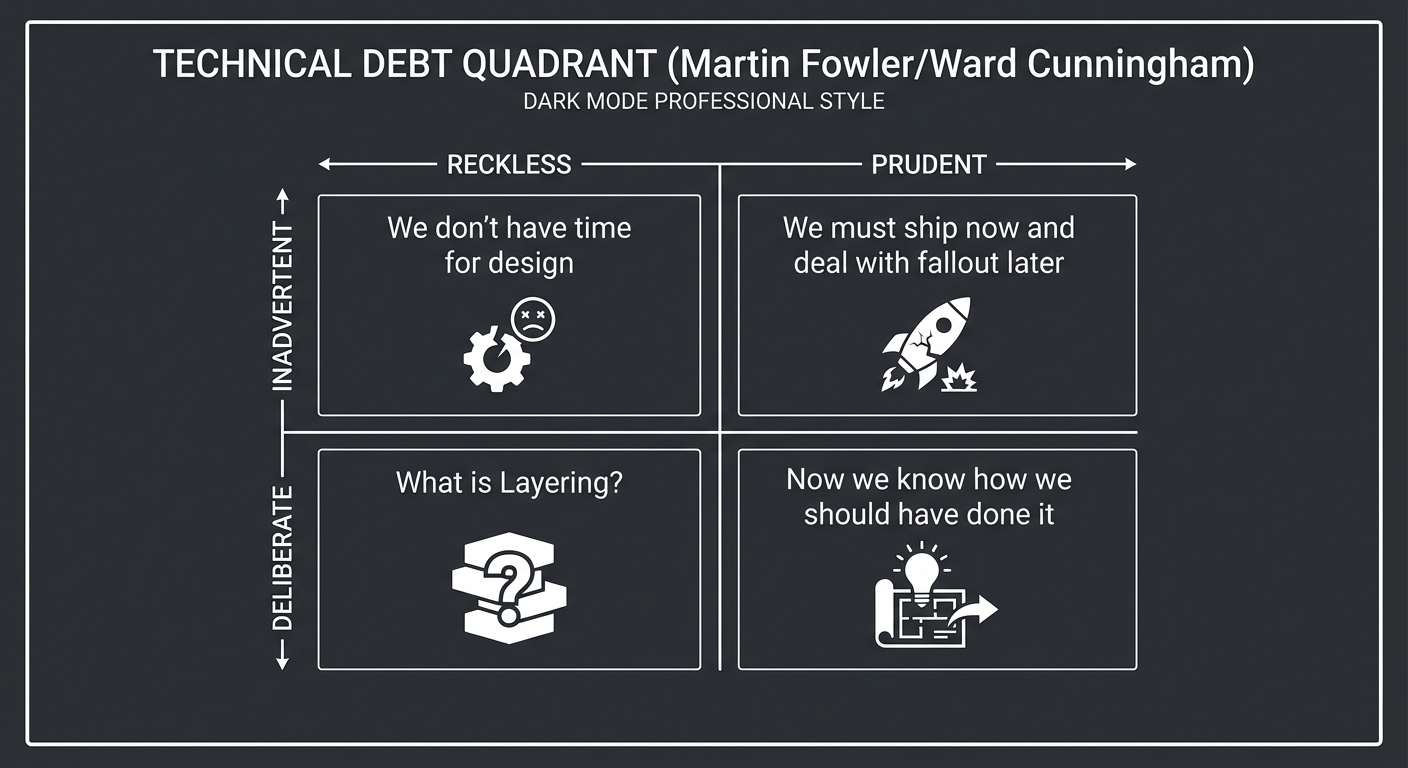
1. The Technical Debt Quadrant
Refactoring should target the right quadrant. Prudent debt is a tool; reckless debt is a mistake.
RECKLESS PRUDENT
┌─────────────────────────┬─────────────────────────┐
│ "We don't have time for │ "We must ship now and │
│ design/testing." │ deal with the fallout │
│ │ later." │
DELIBERATE ├─────────────────────────┼─────────────────────────┤
│ "What is Layering?" │ "Now we know how we │
│ │ should have done it." │
│ │ │
INADVERTENT └─────────────────────────┴─────────────────────────┘
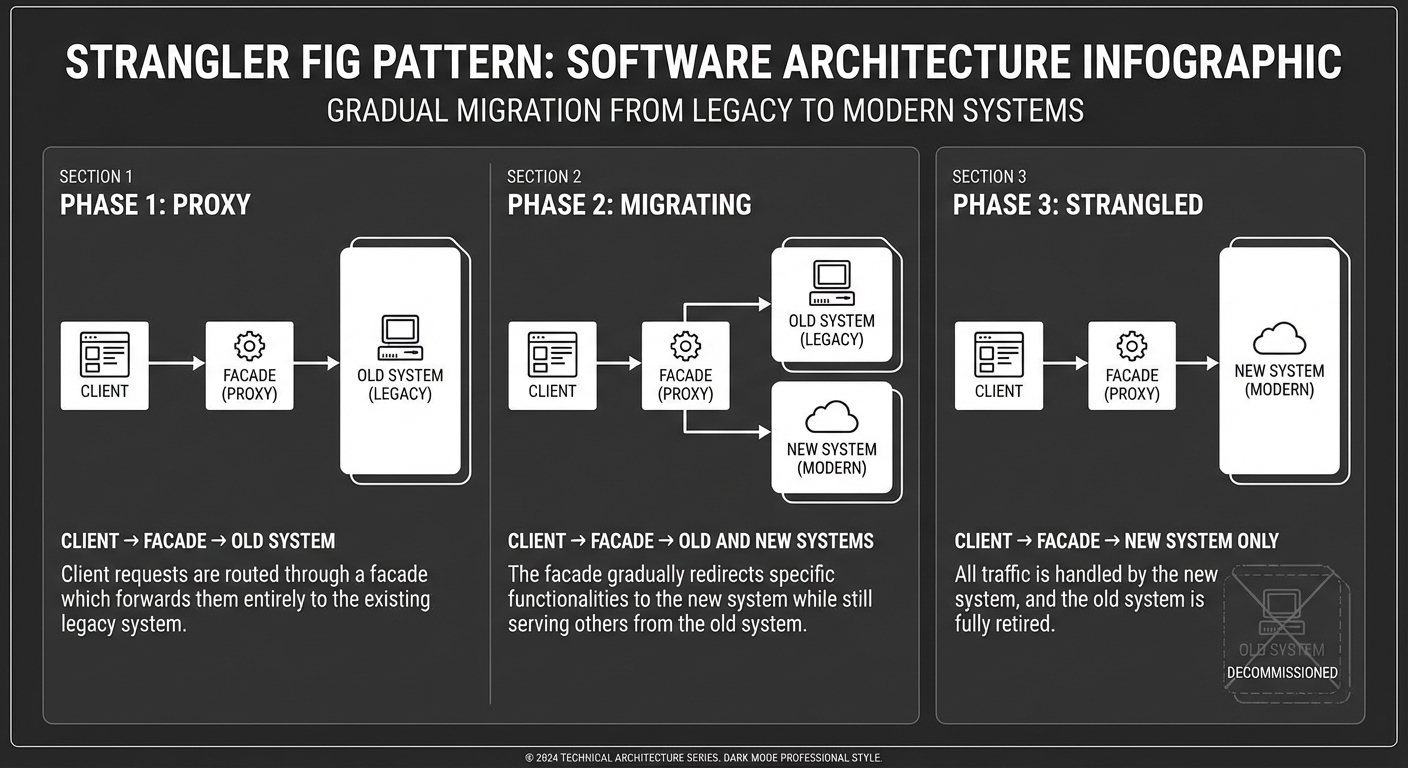
2. The Strangler Fig Pattern
Named after a tree that grows around another tree until it eventually replaces it. This is how you migrate massive systems without a “Big Bang” rewrite.
PHASE 1: PROXY PHASE 2: MIGRATING PHASE 3: STRANGLED
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ CLIENT │ │ CLIENT │ │ CLIENT │
└───────┬───────┘ └───────┬───────┘ └───────┬───────┘
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ ROUTING/API │ │ ROUTING/API │ │ ROUTING/API │
│ FACADE │ │ FACADE │ │ FACADE │
└───────┬───────┘ └───────┬───────┘ └───────┬───────┘
┌────┴────┐ ┌────┴────┐ ┌────┴────┐
│ │ │ │ │ │
▼ │ ▼ ▼ │ ▼
┌───────┐ │ ┌───────┐ ┌───────┐ │ ┌───────┐
│ OLD │ │ │ OLD │ │ NEW │ │ │ NEW │
│SYSTEM │ │ │SYSTEM │ │SYSTEM │ │ │SYSTEM │
└───────┘ │ └───────┘ └───────┘ │ └───────┘
│ (In Progress) │ (Complete)
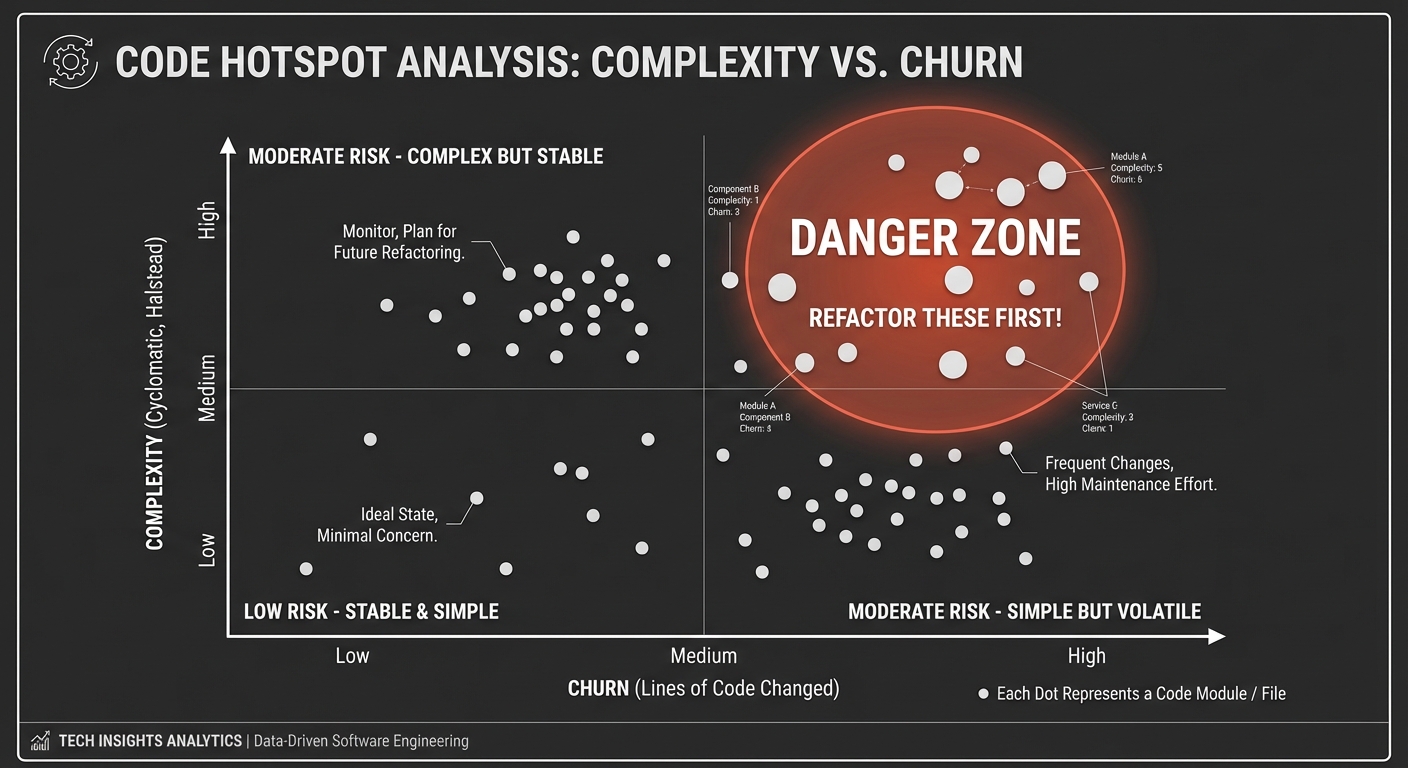
3. Hotspots: Complexity vs. Churn
The “High-Interest” debt lives where code is both Complex and Frequently Changed.
Complexity (Y)
^
│ (DANGER ZONE)
│ High Complexity
│ Low Churn High Churn
│ o O <--- REFACTOR THESE FIRST!
│
│ Low Complexity Low Complexity
│ Low Churn High Churn
│ . o
└──────────────────────────────────> Churn (X)
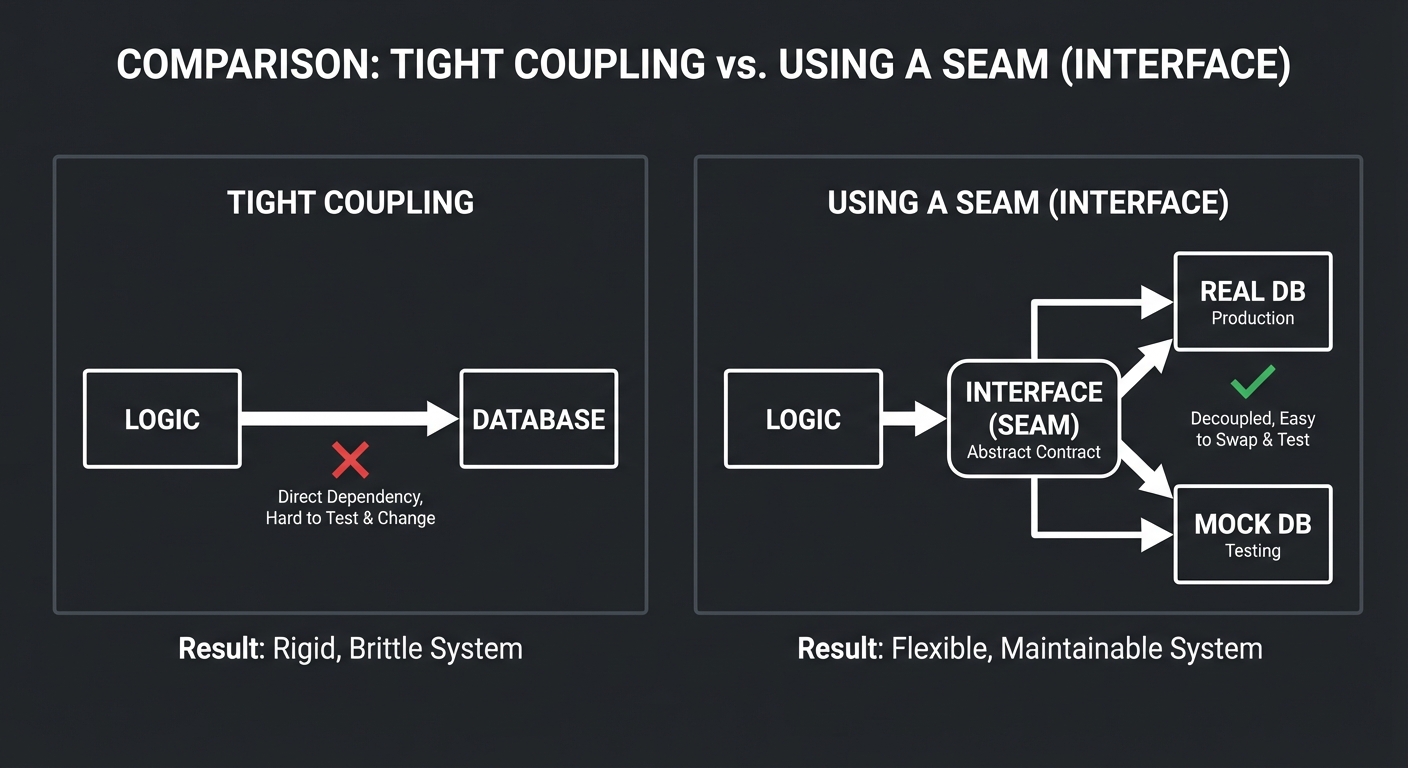
4. Seams and Boundaries
A “Seam” is a place where you can alter behavior in your program without editing in that place. Breaking dependencies is about finding or creating these seams.
Tight Coupling: Using a Seam (Interface):
┌─────────┐ ┌─────────┐
│ Logic │──┐ │ Logic │
└─────────┘ │ └────┬────┘
▼ ▼
┌─────────┐ ┌───────────┐
│ Database│ │ Interface │
└─────────┘ └─────┬─────┘
│
┌───────┴───────┐
▼ ▼
┌──────────┐ ┌──────────┐
│ Real DB │ │ Mock DB │
└──────────┘ └──────────┘
Concept Summary Table
| Concept Cluster | What You Need to Internalize |
|---|---|
| Financial Nature of Debt | Code is an asset; maintenance is a liability. Debt has interest (velocity loss) and principal (refactor cost). |
| Hotspot Analysis | Prioritize refactoring by correlating code complexity with change frequency (churn). |
| Strangler Fig Pattern | Incrementally migrate systems by wrapping them in proxies and siphoning traffic. |
| Seams & Decoupling | Use interfaces and dependency inversion to isolate legacy code before cutting it out. |
| Dark Launching | Deploying refactored code that isn’t yet “active” to verify it under production load. |
| AST & Codemods | Treating code as data to perform mass structural changes automatically. |
| Fitness Functions | Automated tests that enforce architectural rules and prevent regression into debt. |
Deep Dive Reading by Concept
Strategic Refactoring & Debt Theory
| Concept | Book & Chapter | |———|—————-| | The Definition of Debt | “Refactoring” by Martin Fowler — Ch. 1 & 2 | | Software Entropy | “The Pragmatic Programmer” by Hunt & Thomas — Ch. 1: “Software Entropy” | | Measuring Impact | “Accelerate” by Nicole Forsgren — Ch. 2: “Measuring Performance” |
Tactical Refactoring (The How-To)
| Concept | Book & Chapter | |———|—————-| | Refactoring Catalog | “Refactoring” by Martin Fowler — Ch. 6-12 | | Legacy Seams | “Working Effectively with Legacy Code” by Michael Feathers — Ch. 4: “The Seam Model” | | Dependency Inversion | “Clean Architecture” by Robert Martin — Ch. 11: “DIP” |
Migration Patterns
| Concept | Book & Chapter | |———|—————-| | Strangler Fig | “Monolith to Microservices” by Sam Newman — Ch. 4 | | Branch by Abstraction | “Continuous Delivery” by Humble & Farley — Ch. 12 | | Database Refactoring | “Refactoring Databases” by Ambler & Sadalage — Ch. 1-3 |
Automated Analysis & Governance
| Concept | Book & Chapter | |———|—————-| | Hotspot Detection | “Software Design X-Rays” by Adam Tornhill — Ch. 2 & 3 | | Fitness Functions | “Building Evolutionary Architectures” by Neal Ford — Ch. 2 | | AST Manipulation | “The Secret Life of Programs” by Steinhart — Ch. 8 |
Project 1: The Debt Auditor (Visualizing Complexity vs. Churn)
- Main Programming Language: Python
- Alternative Programming Languages: Go, TypeScript
- Difficulty: Level 2: Intermediate
- Knowledge Area: Static Analysis / Data Visualization
- Main Book: “Software Design X-Rays” by Adam Tornhill
What you’ll build: A tool that parses a Git repository’s history and calculates “Hotspots.” It correlates Cyclomatic Complexity (how hard the code is to read) with Churn (how often the file changes).
Why it teaches Technical Debt: You’ll discover that 80% of your debt is usually in 5% of your code. High complexity is fine in a file that hasn’t been touched in 3 years. It’s lethal in a file that changes every day. This project teaches you to prioritize refactoring based on business impact.
Real World Outcome
You will generate a “Hotspot Map.” This is a scatter plot (HTML/Interactive) where the X-axis is “Number of Changes” (Churn) and the Y-axis is “Complexity.” Files in the top-right quadrant are your “Interest-Bearing Debt.”
CLI Output Example:
$ python debt_auditor.py --repo ./my_monorepo --since "2024-01-01"
[1/3] Parsing Git history... 4,200 commits found.
[2/3] Calculating complexity for 850 files...
[3/3] Correlating data...
TOP 3 HOTSPOTS (Refactor immediately!):
1. src/payments/processor.c
- Complexity: 125 (Very High)
- Churn: 84 changes (Weekly)
- Debt Score: 10,500
2. src/auth/session_manager.c
- Complexity: 82
- Churn: 45 changes
- Debt Score: 3,690
3. src/core/main_loop.c
- Complexity: 210
- Churn: 12 changes
- Debt Score: 2,520
Report generated: hotspots.html
# Open hotspots.html to see a D3.js or Plotly scatter plot where circle size = file size.
The Core Question You’re Answering
“If I have 2 hours to refactor this week, where will it save the most time for my team next week?”
Before you write any code, sit with this question. Refactoring “ugly” code that never changes is a waste of company money. Refactoring “ugly” code that everyone touches is a massive investment.
Concepts You Must Understand First
- Cyclomatic Complexity
- What is the difference between linear code and nested conditionals?
- How many test cases are required for a function with complexity N?
- Book Reference: “Code Complete” Ch. 19 - Steve McConnell
- Git Log Analysis
- How do you get a list of files changed in a specific commit range?
- How do you ignore “noise” like whitespace-only changes?
- Reference:
git log --pretty=format: --name-only
- Software Hotspots
- Why is churn a proxy for “importance”?
- Book Reference: “Software Design X-Rays” Ch. 2 - Adam Tornhill
Questions to Guide Your Design
- Analysis Strategy
- Should you measure complexity by AST (Abstract Syntax Tree) or simple indentation levels (a good proxy)?
- How do you handle file renames? If
old.cbecomesnew.c, does the churn reset?
- Presentation
- How do you visualize “Size” vs. “Complexity”? (Hint: Circle size vs position)
Thinking Exercise
The Churn Paradox
Imagine two files:
- File A: 50 lines. Changed 100 times in 6 months.
- File B: 500 lines. Changed 2 times in 6 months.
Questions:
- Which file is more likely to contain a bug today?
- Which file is a better candidate for an automated test suite?
- If File A is simple but File B is a “god object,” which one is actually costing you more velocity?
The Interview Questions They’ll Ask
- “How do you justify a ‘Refactoring Sprint’ to a Product Manager?”
- “What metrics do you use to identify technical debt?”
- “Is high cyclomatic complexity always a sign of bad code?”
- “What is ‘Code Churn’ and why does it matter for system stability?”
Hints in Layers
Hint 1: Git Parsing
Use subprocess.check_output(['git', 'log', '--name-only', '--pretty=format:']) to get the list of changed files. Pipe it to a counter.
Hint 2: Complexity Proxy If AST parsing is too hard, use “Maximum Indentation Level” per file. It’s 90% correlated with Cyclomatic Complexity and much easier to calculate.
Hint 3: Data Output
Output a JSON file like [{ "file": "path/to/f.c", "complexity": 10, "churn": 5 }]. Use a simple HTML template with Chart.js to render the scatter plot.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Hotspot Theory | “Software Design X-Rays” | Ch. 2-3 |
| Complexity Metrics | “Code Complete” | Ch. 19 |
| Refactoring Strategy | “Refactoring” | Ch. 2 |
Project 2: The Seam Inspector (Dependency & Layer Violation)
- Main Programming Language: Go (excellent for parsing)
- Alternative Programming Languages: Java, TypeScript
- Difficulty: Level 3: Advanced
- Knowledge Area: Compilers / Graph Theory
- Main Book: “Working Effectively with Legacy Code” by Michael Feathers
What you’ll build: A tool that builds a directed graph of your codebase’s internal dependencies. It will specifically flag “Circular Dependencies” and “Layer Violations” (e.g., when the Database layer tries to call the UI layer).
Why it teaches Technical Debt: You can’t refactor a “Big Ball of Mud” because everything is connected. To refactor, you must find “Seams”—places where you can break the code apart. This project teaches you to visualize the “Spaghetti” so you can start cutting the right strands.
Real World Outcome
A visual graph (SVG/PNG) where nodes are modules and edges are dependencies. Circular dependencies are highlighted in RED. Layer violations are highlighted in ORANGE.
CLI Output Example:
$ seam-inspector --config arch_rules.json --src ./src
[VIOLATION] src/db/query_builder.go -> src/api/response.go
Reason: Lower layer (DB) cannot depend on Higher layer (API).
[CYCLE DETECTED]
AuthModule -> PermissionService -> UserModel -> AuthModule
This cycle prevents these 3 modules from being tested in isolation.
Graph saved to: dependency_graph.dot
Run 'dot -Tpng dependency_graph.dot -o graph.png' to visualize.
The Core Question You’re Answering
“Where can I put a ‘Seam’ to isolate this code for testing?”
If you cannot instantiate a class in a test without bringing in 50 other classes, you have a dependency problem.
Concepts You Must Understand First
- The Seam Model
- What is a seam? (Preprocessing, Link, or Object seams)
- How do you use a seam to break a dependency?
- Book Reference: “Working Effectively with Legacy Code” Ch. 4
- Directed Acyclic Graphs (DAG)
- What happens when a graph is NOT a DAG? (Cycles)
- How does a cycle affect compilation and testing?
- Book Reference: “Algorithms, 4th Ed” Ch. 4 - Sedgewick
- Layered Architecture Rules
- Why should ‘Domain’ not know about ‘Web’?
- Book Reference: “Clean Architecture” Ch. 25
Questions to Guide Your Design
- Parsing Dependencies
- How do you find imports/includes across different file types?
- Should you track function-level calls or just file-level imports?
- Policy Definition
- How do you define “Layers” in a JSON config file so the tool can check them?
Thinking Exercise
The Hidden Cycle
If A calls B, and B calls C, and C calls A, you have a cycle. Question: How do you fix this without deleting code? (Hint: Interface extraction or a third “Common” module).
The Interview Questions They’ll Ask
- “What is a circular dependency and why is it problematic for deployment?”
- “Explain the ‘Dependency Inversion Principle’ in the context of refactoring.”
- “What is a ‘Seam’ in legacy code?”
- “How do you break a dependency between two tightly coupled classes?”
Hints in Layers
Hint 1: Regex is enough
Start by using simple regex to find import or include statements. You don’t need a full compiler frontend yet.
Hint 2: Cycle Detection Use Tarjan’s Strongly Connected Components algorithm to find cycles in your dependency graph.
Hint 3: Graphviz
Don’t write a drawing engine. Output the graph in .dot format and let the Graphviz tool handle the layout.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Seams & Legacy | “Working Effectively with Legacy Code” | Ch. 4 |
| Architecture Boundaries | “Clean Architecture” | Ch. 11 & 25 |
| Graph Algorithms | “Algorithms, 4th Ed” | Ch. 4 |
Project 3: The Feature Flag Kill-Switch (Decoupling Release from Deployment)
- Main Programming Language: TypeScript (Node.js/React)
- Alternative Programming Languages: Go, Python
- Difficulty: Level 2: Intermediate
- Knowledge Area: Distributed Systems / Configuration Management
- Main Book: “Building Microservices” by Sam Newman
What you’ll build: A system that allows you to swap implementations of a service at runtime. You’ll build the middleware that routes traffic based on a “Flag” (e.g., 90% of traffic goes to the Legacy SQL DB, 10% goes to the New NoSQL DB).
Why it teaches Technical Debt: The biggest fear in refactoring is “Breaking Production.” Feature flags allow you to deploy your refactored code into production while it’s still “Dark” (not receiving traffic). You can then slowly ramp up traffic and “Kill” it instantly if errors spike.
Real World Outcome
A dashboard where you can toggle features on/off and a backend proxy that routes requests based on those toggles.
Example Log Output:
[REQ 1024] User: 45 (BETA_GROUP) -> [FLAG: new_search_v2] -> Routing to REFACTORED_SERVICE
[REQ 1025] User: 89 (STANDARD) -> [FLAG: new_search_v2] -> Routing to LEGACY_SERVICE
[ADMIN] Set flag 'new_search_v2' to 50% rollout...
[REQ 1026] User: 90 (STANDARD) -> [FLAG: new_search_v2] -> Routing to REFACTORED_SERVICE
[ERROR] Spike detected in REFACTORED_SERVICE!
[ADMIN] KILL SWITCH ACTIVATED for 'new_search_v2'.
[REQ 1027] User: 45 (BETA_GROUP) -> Routing to LEGACY_SERVICE (Safety First)
The Core Question You’re Answering
“How can I test my refactor in production without risking a single real user’s experience?”
Concepts You Must Understand First
- Decoupling Deployment from Release
- Deployment = Moving code to servers.
- Release = Turning it on for users.
- Book Reference: “The DevOps Handbook” Ch. 12
- Canary Releasing
- Why send only 1% of traffic initially?
- Book Reference: “Continuous Delivery” Ch. 10
Questions to Guide Your Design
- Persistence
- Where do you store flag states so they are fast to read? (Redis? Local cache?)
- Context
- How do you ensure a user gets a consistent experience (doesn’t flip-flop between old and new)?
Thinking Exercise
The “Permanent” Debt of Flags
Question: If you never delete the flag after a migration is 100% complete, what kind of debt have you created? How do you track “Stale” flags?
The Interview Questions They’ll Ask
- “What is the difference between a Feature Toggle and a Canary Release?”
- “How do you handle database migrations when using feature flags for code?”
- “What happens if your feature flag service goes down? Does it fail open or closed?”
Hints in Layers
Hint 1: The Middleware
Implement the flag check in a piece of middleware that wraps your service calls. if (flags.isEnabled('new_logic')) { ... }.
Hint 2: Sticky Sessions
Use a hash of the UserID (hash(userId) % 100 < rolloutPercentage) to ensure a specific user always gets either the OLD or NEW logic, but not both.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Microservice Patterns | “Building Microservices” | Ch. 5 |
| Continuous Delivery | “Continuous Delivery” | Ch. 10 |
| DevOps Practices | “The DevOps Handbook” | Ch. 12 |
Project 4: The Strangler Proxy (Service Isolation)
- Main Programming Language: Go or Rust (High-performance proxying)
- Alternative Programming Languages: Node.js, Python (FastAPI)
- Difficulty: Level 3: Advanced
- Knowledge Area: Networking / Distributed Systems
- Main Book: “Monolith to Microservices” by Sam Newman
What you’ll build: A reverse proxy that sits in front of a legacy monolith. You will implement a routing table that “Strangles” the monolith by redirecting specific HTTP paths or gRPC calls to a new, refactored microservice.
Why it teaches Technical Debt: The “Strangler Fig” pattern is the gold standard for paying down debt without stopping the world. This project forces you to handle the hard parts: session sharing between systems, data synchronization, and the “Interception” layer.
Real World Outcome
A live system where /api/v1/orders goes to an old PHP monolith, but /api/v2/orders goes to a new Go service, with the user never knowing the difference.
Example Proxy Logs:
$ ./strangler-proxy --config routes.yaml
[STRANGLER] Proxy started on :8080
[STRANGLER] Traffic Split: [Monolith: 90%] [Orders-v2: 10%]
[14:30:01] GET /api/v1/user/123 -> MONOLITH (Legacy)
[14:30:02] GET /api/v1/orders -> ORDERS-V2 (New Service)
[14:30:03] POST /api/v1/orders -> ORDERS-V2 (New Service)
[14:30:05] GET /api/v1/admin -> MONOLITH (Legacy)
# Monitoring metrics show 0% error rate on ORDERS-V2.
# Increasing traffic to 50%...
The Core Question You’re Answering
“How do I move functionality out of a monolith without any downtime or ‘Big Bang’ deployment?”
Concepts You Must Understand First
- The Strangler Fig Pattern
- Intercept, ELement, and Extract.
- Book Reference: “Monolith to Microservices” Ch. 4
- Reverse Proxying
- How to forward requests while preserving headers (X-Forwarded-For).
- Branch by Abstraction
- How to switch implementations within the code vs at the network level.
Questions to Guide Your Design
- Session Management
- If the user logs into the Monolith, how does the New Service know who they are? (Shared Redis session? JWT transformation?)
- Data Consistency
- If a user updates their profile in the New Service, does the Monolith’s database see it?
Thinking Exercise
The Proxy Bottleneck
Question: If you put a proxy in front of everything, you’ve created a single point of failure. How do you ensure the proxy itself doesn’t become a source of technical debt (complexity/performance)?
The Interview Questions They’ll Ask
- “What are the risks of the Strangler Fig pattern?”
- “How do you handle atomic transactions that span both the old and new systems?”
- “Describe a situation where a ‘Big Bang’ rewrite is actually better than a Strangler migration.”
Hints in Layers
Hint 1: Simple Reverse Proxy
In Go, use httputil.NewSingleHostReverseProxy. It handles the heavy lifting of copying request/response bodies.
Hint 2: Routing Logic
Use a trie-based router (like chi or gin) to decide which requests go to which backend based on the path.
Hint 3: Traffic Mirroring Before actually switching traffic, implement a “Shadow Mode” where the proxy sends the request to BOTH backends but only returns the Monolith’s response to the user. Compare the responses in the background.
Project 5: The Codemod Automation (Mass Refactoring)
- Main Programming Language: JavaScript (jscodeshift)
- Alternative Programming Languages: Python (LibCST), Go (AST)
- Difficulty: Level 3: Advanced
- Knowledge Area: Compilers / AST Manipulation
- Main Book: “Refactoring” by Martin Fowler
What you’ll build: A suite of scripts that perform massive, structural code changes across thousands of files simultaneously. For example: changing a function signature used in 500 places, or migrating from one library to another (e.g., from jQuery to Fetch API).
Why it teaches Technical Debt: Manual refactoring is error-prone and slow. At scale, you must treat your code as data. This project teaches you to think in terms of Patterns, not just lines of code.
Real World Outcome
A single command that updates an entire codebase, turning a week-long manual task into a 10-second script execution.
Example Output:
$ npx jscodeshift -t transform-deprecated-api.js ./src --dry
Processing 1,245 files...
[OK] src/components/Header.js
[OK] src/api/user.js
[MODIFIED] src/utils/legacy_helper.js (Changed 14 occurrences of old_func to new_func)
Results:
1,102 files would be modified.
143 files unchanged.
Done in 8.4s.
# Running for real...
$ npx jscodeshift -t transform-deprecated-api.js ./src
$ git status
# 1,102 files changed. Ready to commit!
The Core Question You’re Answering
“How do I perform a refactor that touches 1,000 files without losing my mind or introducing syntax errors?”
Concepts You Must Understand First
- Abstract Syntax Trees (AST)
- What is the difference between a ‘Token’ and a ‘Node’?
- Why is Regex dangerous for mass refactoring? (Hint: nested scopes)
- Book Reference: “The Secret Life of Programs” Ch. 8
- The Boy Scout Rule
- “Leave the campground cleaner than you found it.”
- Book Reference: “Clean Code” Ch. 1
Questions to Guide Your Design
- Targeting
- How do you find the exact function call you want to change without affecting functions with the same name in different modules?
- Preserving Style
- How do you ensure the modified code still follows the team’s
prettieroreslintrules?
- How do you ensure the modified code still follows the team’s
Thinking Exercise
Code as Data
If you treat code as a tree structure instead of a string of text, how does that change your ability to “Search and Replace”?
The Interview Questions They’ll Ask
- “When should a refactor be automated (codemod) vs. manual?”
- “What is an AST and how is it used in modern build tools?”
- “How do you verify a codemod worked correctly across a large repo?”
Hints in Layers
Hint 1: Use AST Explorer
Go to astexplorer.net. Paste your code. See the tree. This is your map for writing the transformation.
Hint 2: Small Steps Don’t try to change the whole architecture in one script. Write one script for one specific transformation (e.g., “Rename argument X to Y”).
Hint 3: Snapshot Testing
Write tests for your codemod! Input: f(a, b). Expected Output: f({ first: a, second: b }).
Project 6: The “Fitness Function” Runner (Architectural Testing)
- Main Programming Language: Java (ArchUnit)
- Alternative Programming Languages: C# (NetArchTest), Python (Import-Linter)
- Difficulty: Level 2: Intermediate
- Knowledge Area: Software Architecture / Testing
- Main Book: “Building Evolutionary Architectures” by Neal Ford
What you’ll build: A set of automated tests that don’t test “features,” but test “structure.” You’ll write rules like: “Classes in the domain package must never import classes from the infrastructure package.”
Why it teaches Technical Debt: Prevention is cheaper than cure. Technical debt often creeps in when developers take “shortcuts” that break layering. This project teaches you to automate architectural governance.
Real World Outcome
Your CI/CD pipeline will fail if someone introduces a dependency that violates your architecture rules.
Example Test Failure:
$ ./gradlew test
> Task :test FAILED
Architecture Violation:
Rule 'Classes in [..domain..] should not depend on classes in [..infrastructure..]' was violated:
- Class src.domain.OrderService depends on src.infrastructure.SqlRepository in (OrderService.java:42)
# This prevents the "Big Ball of Mud" from forming!
The Core Question You’re Answering
“How do we stop the ‘Rot’ from coming back once we’ve refactored?”
Concepts You Must Understand First
- Fitness Functions
- Why do we need automated architectural checks?
- Book Reference: “Building Evolutionary Architectures” Ch. 2
- Linguistic Anti-Patterns
- Why shouldn’t a ‘Getter’ modify state?
- Book Reference: “Software Design X-Rays” Ch. 6
Questions to Guide Your Design
- Severity
- Should all violations break the build, or should some just be “Warnings”?
- Legacy Exceptions
- How do you handle the 500 existing violations while preventing the 501st? (Hint: The “Freeze” or “Ratchet” pattern).
Thinking Exercise
The “Illegal” Dependency
Imagine a system with three layers: Web -> Service -> Database.
Now imagine a developer adds a call from the Database layer to a Web helper function to “format a currency string” for a report.
Questions:
- Why is this a problem for testing the
Databaselayer in isolation? - If you want to move from a
WebUI to aCLIUI, how does this dependency affect you? - How could the developer have achieved the same result without breaking the layer boundary? (Hint: The Service layer or a shared
Utilspackage).
The Interview Questions They’ll Ask
- “What is an architectural fitness function?”
- “How do you enforce layering in a monorepo?”
- “Describe the difference between a unit test and an architectural test.”
Hints in Layers
Hint 1: ArchUnit Basics
In Java, ArchUnit allows you to write: classes().that().resideInAPackage("..domain..").should().onlyBeAccessedByClassesThat().resideInAPackage("..api..").
Hint 2: Import Linter
If using Python, import-linter uses a simple .ini config. Define your “Contracts” (Layers, Independence, etc.).
Hint 3: The “Ignore” List Store existing violations in a text file. If a new violation occurs that ISN’T in the file, fail the build. As you refactor, remove items from the file.
Project 7: The Data Migration Synchronizer (Refactoring Databases)
- Main Programming Language: Python or SQL
- Alternative Programming Languages: Go, Java
- Difficulty: Level 4: Expert
- Knowledge Area: Databases / Distributed Systems
- Main Book: “Designing Data-Intensive Applications” by Martin Kleppmann
What you’ll build: A tool that synchronizes two different database schemas in real-time. This allows you to refactor your database (e.g., splitting a table, changing column types) without downtime. It implements “Double Writing” or “CDC” (Change Data Capture) to keep the Old and New schemas in sync during the transition.
Why it teaches Technical Debt: Database refactoring is the “Final Boss” of technical debt. Unlike code, data has state and cannot be simply “reverted” if a migration fails halfway. This project teaches you the safety patterns required for stateful refactoring.
Real World Outcome
A system where an update to Legacy_Orders table automatically propagates to the refactored New_Order_System database with sub-second latency.
Example Migration Status:
$ sync-monitor --job order-refactor
Phase: Backfilling (65% complete)
Throughput: 1,200 records/sec
In-Sync Verification:
[MATCH] Legacy ID 4055 == New ID 4055
[MATCH] Legacy ID 4056 == New ID 4056
[DRIFT DETECTED] ID 4057 (Status mismatch) -> Triggering auto-fix...
[FIXED] ID 4057 re-synced.
# You can now safely point your new services to the refactored database.
The Core Question You’re Answering
“How do I refactor a database schema without taking the site offline for a migration script?”
Concepts You Must Understand First
- Change Data Capture (CDC)
- How to stream database logs (WAL) to another system.
- Book Reference: “Designing Data-Intensive Applications” Ch. 11
- The Parallel Run
- Running two versions of the same system and comparing results.
- Book Reference: “Monolith to Microservices” Ch. 4
- Double Writing Anti-patterns
- Why writing to two DBs in one app function is dangerous (partial failures).
Questions to Guide Your Design
- Conflict Resolution
- If an update happens to the SAME record in both schemas at the same time, who wins?
- Backfilling
- How do you move 10 years of legacy data into the new schema without killing the production DB’s performance?
Thinking Exercise
Data Gravity
Question: Once data is in a certain format, it’s very hard to move. How can you design your “New” schema to be more refactor-friendly than the “Old” one?
The Interview Questions They’ll Ask
- “How do you perform a zero-downtime database migration?”
- “What is CDC and why is it better than polling for changes?”
- “How do you verify data integrity between two different schemas in real-time?”
Hints in Layers
Hint 1: Simple CDC
Use Debezium or a similar tool to stream changes from MySQL/Postgres to a Kafka topic.
Hint 2: The Transformer Write a small consumer script that reads the Kafka topic, transforms the “Legacy” JSON into “New” SQL, and inserts it into the second DB.
Hint 3: Idempotency
Ensure your “Insert/Update” operations in the new DB are idempotent (using UPSERT or ON CONFLICT DO UPDATE). This prevents errors if the same message is processed twice.
Project 8: The “Debt Ledger” Dashboard (Measuring Interest)
- Main Programming Language: TypeScript (Next.js)
- Alternative Programming Languages: Python (Streamlit)
- Difficulty: Level 2: Intermediate
- Knowledge Area: Data Engineering / Business Analytics
- Main Book: “Accelerate” by Nicole Forsgren
What you’ll build: A dashboard that pulls data from Jira (tickets) and GitHub (commits) to calculate the “Interest” being paid on specific modules. It calculates the correlation between a module and “Bug Tickets” or “Cycle Time.”
Why it teaches Technical Debt: To get funding for refactoring, you must speak the language of the business. This project teaches you to quantify debt in terms of Money and Time.
Real World Outcome
A dashboard for engineering managers showing which parts of the codebase are “Money Pits.”
Example Dashboard Output:
DEBT INTEREST REPORT - Q4 2025
Module: Payments-Legacy
- Change Frequency: +45% (High Churn)
- Average Bug Count: 12/week (vs 2/week avg)
- Cycle Time: 8.5 days (vs 3.2 days avg)
- ESTIMATED COST OF DEBT: $12,500 / month in wasted engineering hours.
RECOMMENDATION: ALLOCATE 20% SPRINT CAPACITY TO REFACTORING.
The Core Question You’re Answering
“How do I prove to my Product Manager that refactoring this module will actually speed up our roadmap?”
Concepts You Must Understand First
- DORA Metrics
- Deployment Frequency, Lead Time for Changes, MTTR, Change Failure Rate.
- Book Reference: “Accelerate” Ch. 2
- The Cost of Delay
- How much does it cost the company every day a feature is NOT shipped?
Thinking Exercise
The ROI of a Refactor
You have two modules:
- Module A: High churn, low bug rate, high cycle time (takes forever to add features).
- Module B: Low churn, high bug rate, low complexity.
Questions:
- Which one is “Interest-Bearing Debt”?
- If you refactor Module A, how do you measure the success if the bug count was already low?
- How do you translate “High Cycle Time” into a dollar amount that a CFO would understand?
The Interview Questions They’ll Ask
- “How do you measure the ROI (Return on Investment) of a refactor?”
- “What are DORA metrics and why are they better than ‘Lines of Code’?”
- “How do you explain technical debt to a non-technical stakeholder?”
Hints in Layers
Hint 1: APIs
Start by using the GitHub API to get commit history and the Jira API to get issue history. Link them by searching for patterns like [PROJ-123] in commit messages.
Hint 2: Simple Metrics Calculate “Bugs per 100 commits” for each directory. Directories with the highest ratio are your likely candidates for refactoring.
Hint 3: Visualization
Use Recharts or D3 to show a trend line: As “Debt Score” goes up, “Feature Velocity” goes down.
Project 9: The Change Coupling Detector (Finding Logical Dependencies)
- Main Programming Language: Python
- Alternative Programming Languages: R, Julia
- Difficulty: Level 3: Advanced
- Knowledge Area: Data Science / Git Internals
- Main Book: “Software Design X-Rays” by Adam Tornhill
What you’ll build: A tool that finds “Logical Coupling”—files that always change together even if they don’t have a direct code dependency. If PaymentProcessor.c and LoggingUtils.c are changed in the same commit 90% of the time, they are “Coupled.”
Why it teaches Technical Debt: Logical coupling is a hidden form of debt. It indicates a failure in encapsulation. When you refactor, these are the dependencies that “break” your new service boundaries.
Real World Outcome
A report showing “Ghost Dependencies” that aren’t visible in the source code.
CLI Output Example:
$ python coupling_detector.py --repo ./my_app
ANALYSIS COMPLETE.
Found 12 Hidden Couplings (Files changed together > 80% of time):
1. [STRONG] src/orders.c <-> src/email_templates.json (94% coupling)
* Danger: Changing order logic requires updating JSON. These should be decoupled!
2. [STRONG] src/db/schema.sql <-> tests/integration/db_test.py (88% coupling)
* Expected: Database and its tests are naturally coupled.
3. [WARNING] src/auth.c <-> src/ui/login_button.js (82% coupling)
* Danger: Back-end and Front-end are too tightly coupled across layers.
Heatmap generated: coupling_matrix.png
The Core Question You’re Answering
“Why did changing the ‘User Avatar’ logic break the ‘Invoice PDF’ generator?”
Concepts You Must Understand First
- Logical Coupling
- Why files that change together are “connected” even without an
importstatement. - Book Reference: “Software Design X-Rays” Ch. 3
- Why files that change together are “connected” even without an
- Afferent vs Efferent Coupling
- Who depends on me vs who do I depend on?
Questions to Guide Your Design
- Thresholds
- What is the minimum number of commits a file must have before you consider its coupling “significant”?
- Filtering
- How do you ignore mass changes (like updating a copyright header in every file)?
Thinking Exercise
The invisible bridge
If two files have high logical coupling but NO code dependency, where is the dependency actually located? (Hint: It’s in the developer’s head or a shared database schema).
The Interview Questions They’ll Ask
- “What is logical coupling and how is it different from code coupling?”
- “How does high logical coupling affect the ‘Strangler Fig’ migration?”
- “Can you have logical coupling between two different repositories?”
Hints in Layers
Hint 1: Git Log Sets
For every commit, create a “Set” of files changed. Commit1: {A, B}, Commit2: {B, C}, Commit3: {A, B}.
Hint 2: Co-occurrence Matrix
Create a matrix where Matrix[A][B] counts how many times A and B appeared in the same set.
Hint 3: Jaccard Similarity
Use the Jaccard index: (Times A & B changed together) / (Times A OR B changed). This gives you a percentage of coupling.
Project 10: The Incident-to-Debt Mapper (Root Cause Correlation)
- Main Programming Language: Python
- Alternative Programming Languages: JavaScript, Go
- Difficulty: Level 2: Intermediate
- Knowledge Area: DevOps / Reliability Engineering
- Main Book: “Site Reliability Engineering” (Google)
What you’ll build: A tool that cross-references “Production Incidents” (from PagerDuty or logs) with specific areas of the codebase. It creates a heatmap of “Dangerous Code”—where the debt is actually causing system crashes.
Why it teaches Technical Debt: Not all debt is “expensive” (slowing you down). Some debt is “dangerous” (breaking the system). This project teaches you to prioritize refactoring based on Risk.
Real World Outcome
A risk heatmap showing which files are most likely to cause the next production outage.
Example Heatmap Data (JSON):
{
"src/auth/token_store.c": {
"incidents": 5,
"total_downtime": "120m",
"last_failure": "2025-11-20",
"risk_level": "CRITICAL"
},
"src/ui/sidebar.js": {
"incidents": 1,
"total_downtime": "0m",
"last_failure": "2024-02-01",
"risk_level": "LOW"
}
}
The Core Question You’re Answering
“Which part of our ‘Messy Code’ is actually scaring the Ops team and causing outages?”
Concepts You Must Understand First
- Error Budgets
- How much failure is acceptable before we stop shipping features?
- Book Reference: “SRE Book” Ch. 3
- Mean Time to Repair (MTTR)
- Why debt increases repair time (haunted graveyards).
Questions to Guide Your Design
- Attribution
- When a crash happens at line 500, how do you know which “Module” is responsible?
- Context
- How do you distinguish between a hardware failure and a software debt failure?
Thinking Exercise
The Flaky Test
If a module has a lot of flaky tests, is that technical debt? Does it correlate with production incidents?
The Interview Questions They’ll Ask
- “What is an Error Budget and how does it relate to technical debt?”
- “How do you handle a post-mortem for an incident caused by legacy debt?”
- “Should you always refactor the code that caused the most recent outage?”
Hints in Layers
Hint 1: Log Parsing
Use grep or a Python script to scan your application logs for stack traces. Extract the filename and line number from the trace.
Hint 2: Incident Linking If your team uses PagerDuty, use their API to get incident reports. Look for “Root Cause” notes that mention specific files or PRs.
Hint 3: Weighting
Assign a “Risk Score”: (Number of Incidents * 10) + (Minutes of Downtime). Sort by this score.
Project 11: The Migration “Long Tail” Tracker (Ensuring Completion)
- Main Programming Language: Bash / Python
- Difficulty: Level 1: Beginner
- Knowledge Area: Engineering Management / Automation
- Main Book: “Software Engineering at Google” by Winters et al.
What you’ll build: A tool that tracks the “Burn down” of a deprecated pattern. For example, if you are migrating from Native-SQL to ORM, this tool scans the codebase daily and charts the progress (Total counts of deprecated_func() calls).
Why it teaches Technical Debt: The most dangerous part of a refactor is the “90% done” state. Having two ways to do things is more debt than having one bad way. This project teaches you the discipline of Finishing.
Real World Outcome
A “Migration Burn-down Chart” that updates every time someone pushes to main.
CLI Output Example:
$ ./track-migration.sh --pattern "mysql_query\("
MIGRATION PROGRESS: [Native-SQL -> ORM]
- Initial Count (Jan 1st): 1,200 calls
- Current Count (Dec 26th): 142 calls
- Progress: 88.1% Complete
- Estimated Completion: 2 weeks.
WARNING: 3 NEW calls added to src/legacy/report_gen.c!
# Breaking the build to prevent "Migration Leakage".
The Core Question You’re Answering
“How do we ensure that we actually finish our refactors instead of leaving ‘Zombies’ in the code forever?”
Concepts You Must Understand First
- Deprecation Policies
- How to communicate that a function is “No longer allowed.”
- Book Reference: “Software Engineering at Google” Ch. 15
- The Incremental Migration
- Why “Stopping the world” for a rewrite never works.
Questions to Guide Your Design
- Detection
- How do you find the pattern reliably without too many false positives? (Regex vs AST).
- Prevention
- How do you stop a new developer from using the “Old Way” because they found it in an old file?
Thinking Exercise
The Zombie Apocalypse
A team starts a migration from Library A to Library B. After 3 months, 80% of the code is migrated. Then, a “Priority 1” project comes in, and the migration is paused.
6 months later, the original developers have left.
Questions:
- What is the cost of having two different ways to do the same thing in the codebase for new hires?
- How do you “Kill the Zombies” (the remaining 20%) when no one remembers why they weren’t migrated in the first place?
- Would it have been better to never start the migration if you weren’t sure you could finish it?
The Interview Questions They’ll Ask
- “Why is the ‘90% done’ state dangerous for a large codebase?”
- “How do you manage cross-team migrations at scale?”
- “What is ‘Migration Leakage’ and how do you prevent it?”
Hints in Layers
Hint 1: Git Grep
git grep -c "pattern" is the fastest way to get a count across the whole repo.
Hint 2: History
Write the count and timestamp to a CSV file. Use a simple Python script with matplotlib to plot the “Burn-down” line.
Hint 3: CI Hook
Add a step to your CI that runs the count. If current_count > previous_count, fail the build. This is the “Ratchet” that ensures progress only goes one way.
Project 12: The API Shadow-Traffic Runner (Verifying Refactors)
- Main Programming Language: Go
- Alternative Programming Languages: Rust, Node.js
- Difficulty: Level 4: Expert
- Knowledge Area: Networking / Quality Assurance
- Main Book: “Release It!” by Michael Nygard
What you’ll build: A system that “clones” real production traffic and sends it to your refactored code in the background. It then compares the responses from the “Legacy” and “New” systems. If they differ, it logs a “Refactor Bug” without the user ever seeing an error.
Why it teaches Technical Debt: This is the ultimate “No-Risk” refactoring technique. It teaches you how to prove that your refactored code is Logically Equivalent to the old code using real-world edge cases that your test suite missed.
Real World Outcome
You can deploy a massive refactor with 100% confidence because it has already processed 1 million real production requests without a single mismatch.
Example Comparison Log:
[SHADOW] Request: GET /api/v2/products?id=45
[LEGACY] Status: 200, Body: {"name": "Widget", "price": 10.99}
[NEW] Status: 200, Body: {"name": "Widget", "price": 10.99}
[RESULT] MATCH
[SHADOW] Request: GET /api/v2/products?id=999 (Invalid ID)
[LEGACY] Status: 404, Body: {"error": "Not Found"}
[NEW] Status: 500, Body: {"error": "Internal Server Error"}
[RESULT] MISMATCH! -> Bug found in New implementation handling edge cases.
The Core Question You’re Answering
“How can I prove my refactor is ‘Correct’ when the ‘Old Code’ has no documentation and 5,000 edge cases?”
Concepts You Must Understand First
- Shadowing (Traffic Mirroring)
- Mirroring traffic at the load balancer level.
- Book Reference: “Building Microservices” Ch. 5
- Idempotency
- Why you should only shadow “Read” requests initially! (Don’t shadow a
DELETErequest or you’ll delete the data twice).
- Why you should only shadow “Read” requests initially! (Don’t shadow a
Questions to Guide Your Design
- Comparison Logic
- How do you handle fields that are NATURALLY different (like
server_timestamporrequest_id)?
- How do you handle fields that are NATURALLY different (like
- Performance
- How do you ensure shadowing doesn’t slow down the response to the real user? (Async / Fire-and-forget).
Thinking Exercise
Trusting the Shadow
You are shadowing traffic for a new “Pricing Engine.”
The Shadow result says: New: $10.00, Legacy: $9.99.
You investigate and find that the Legacy code was actually wrong (it had a rounding bug that favored the customer).
Questions:
- Is the refactor “Correct” if it doesn’t match the legacy behavior?
- How do you communicate to stakeholders that “The new code is different because the old code was broken”?
- How do you handle cases where the “Truth” (Legacy) is actually the “Error”?
The Interview Questions They’ll Ask
- “What is Shadow Traffic and when should you use it?”
- “How do you handle ‘Dirty Reads’ when shadowing traffic?”
- “Describe how to safely shadow a ‘Write’ request.”
Hints in Layers
Hint 1: Mirroring
If using Go, use a Goroutine to send the second request. go sendShadowRequest(req). Make sure to clone the request body as it’s a stream that can only be read once.
Hint 2: Sanitization
Before comparing two JSON bodies, delete keys that you expect to be different (timestamps, IDs, etc.). Use a library like reflect.DeepEqual.
Hint 3: Sampling Don’t shadow 100% of traffic if you’re worried about load. Start with 1% and increase as you gain confidence.
Project Comparison Table
| Project | Difficulty | Time | Depth | Fun |
|---|---|---|---|---|
| 1. Debt Auditor | Level 2 | 1 Week | High (Strategic) | ★★★★☆ |
| 2. Seam Inspector | Level 3 | 1 Week | High (Tactical) | ★★★★★ |
| 3. Feature Flag Switch | Level 2 | Weekend | Medium (Process) | ★★★☆☆ |
| 4. Strangler Proxy | Level 3 | 2 Weeks | High (Architectural) | ★★★★☆ |
| 5. Codemod Automation | Level 3 | 1 Week | Medium (Syntax) | ★★★★★ |
| 6. Fitness Functions | Level 2 | Weekend | High (Governance) | ★★★☆☆ |
| 7. Data Sync | Level 4 | 2 Weeks | Maximum (State) | ★★★★☆ |
| 8. Debt Ledger | Level 2 | 1 Week | High (Business) | ★★☆☆☆ |
| 9. Coupling Detector | Level 3 | 1 Week | High (Logic) | ★★★★☆ |
| 10. Incident Mapper | Level 2 | 1 Week | High (Risk) | ★★★☆☆ |
| 11. Migration Tracker | Level 1 | Weekend | Medium (Completion) | ★★☆☆☆ |
| 12. Shadow Runner | Level 4 | 2 Weeks | Maximum (Verification) | ★★★★★ |
Recommendation
If you are a Developer: Start with Project 5 (Codemods) or Project 2 (Seam Inspector). These will give you immediate “Superpowers” in your daily work and help you understand how code is structured at a deep level.
If you are an Architect/Lead: Start with Project 1 (Debt Auditor) and Project 6 (Fitness Functions). These tools will help you visualize the “Rot” and put guardrails in place to stop it from spreading.
If you are an SRE/DevOps: Start with Project 4 (Strangler Proxy) and Project 12 (Shadow Traffic). These are the “Heavy Lifting” techniques for massive, zero-downtime migrations.
Final Overall Project: The “Zero-Downtime Monolith Extraction”
The Scenario: You have a massive, 10-year-old Monolith managing “E-Commerce.” You need to extract the “Inventory Service” into a separate system because it’s the source of 90% of your production bugs and is blocking the team’s velocity.
The Mission: Apply everything you’ve learned to perform a “textbook” extraction:
- Audit: Use the Debt Auditor to prove the Inventory module is the bottleneck.
- Isolate: Use the Seam Inspector to find the boundaries and fix circular dependencies.
- Govern: Implement Fitness Functions to ensure no new dependencies are added to the Inventory module.
- Proxy: Deploy a Strangler Proxy in front of the Monolith.
- Sync: Use Data Migration Synchronization to keep the Inventory DB in sync.
- Verify: Use Shadow Traffic to prove the New Inventory Service behaves exactly like the Old one.
- Toggle: Use a Feature Flag to ramp up traffic to 100%.
- Cleanup: Use a Codemod to remove the old Inventory code from the Monolith.
Expected Outcomes
After completing these projects, you will:
- Quantify Debt: Translate “ugly code” into “dollar loss” and “time interest” for leadership.
- Isolate Legacies: Use seams and proxies to build “firewalls” around decaying systems.
- Migrate Safely: Implement zero-downtime strategies for both logic and data.
- Automate Governance: Use fitness functions and codemods to maintain quality at scale.
- Master Complexity: Navigate and dismantle 100k+ LOC systems without fear.
You’ll have built 12 working tools that demonstrate a mastery of software evolution—moving from a code-writer to a system-shaper.