Learn Software Engineering Practices: From Zero to Software Engineering Practices Master
Goal: Deeply understand the practices that make software reliable over time: how advanced testing strategies prove behavior, how code review workflows surface risk, how technical debt accumulates interest, and how legacy systems can be refactored safely. You will build tools and processes that expose invariants, reduce regressions, and quantify quality. You will learn to design systems where change is safe, reversible, and observable. You will be able to assess, improve, and evolve real production codebases with confidence.
Why Software Engineering Practices Matter
Modern software fails less because of missing features and more because of missing discipline. The last 20 years turned “software” from a product into a continuously evolving service. This makes testing, review, debt management, and refactoring the real engines of reliability.
Key reasons it matters:
- Early software was shipped on disks and rarely updated; today, continuous delivery means every change is a production risk.
- Incidents rarely come from “unknown unknowns”; they come from unchecked assumptions and broken contracts.
- Legacy systems hold core business value, and replacing them is often riskier than refactoring them.
- Strong practices unlock higher velocity because change becomes safer, not slower.
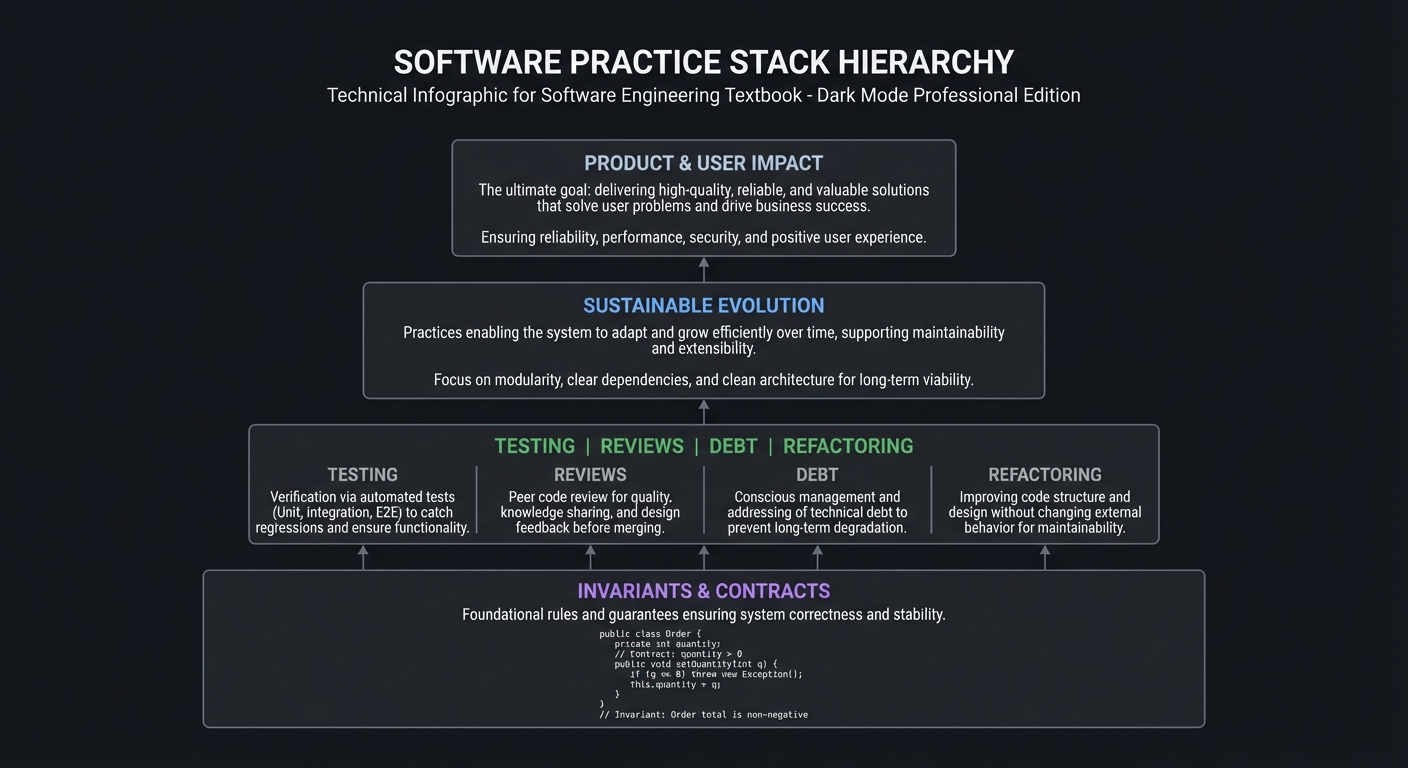
ASCII view of the practice stack:
┌───────────────────────────┐
│ Product & User Impact │
└─────────────┬─────────────┘
│
┌─────────────▼─────────────┐
│ Sustainable Evolution │
└─────────────┬─────────────┘
│
┌────────────────────▼───────────────────┐
│ Testing | Reviews | Debt | Refactoring │
└────────────────────┬───────────────────┘
│
┌─────────────▼─────────────┐
│ Invariants & Contracts │
└───────────────────────────┘
Core Concept Analysis
1. Invariants and Contracts: The Rules Your System Must Never Break
Software engineering practices are just ways of enforcing invariants when the system evolves.
INVARIANTS
┌──────────────────────────────┐
│ Data must always be valid │
│ Security rules never relax │
│ API behavior stays stable │
│ Critical paths stay fast │
└──────────────────────────────┘

Key idea: Every testing or review activity is a way to protect one of these invariants.
2. Testing Strategies as Evidence, Not Just Checks
Different testing strategies answer different questions.
PROPERTY TESTS ──> "What must always be true?"
FUZZING ──> "What inputs break me?"
CONTRACT TESTS ──> "Do I still match the agreement?"
CHARACTERIZATION ─> "What does this system do today?"
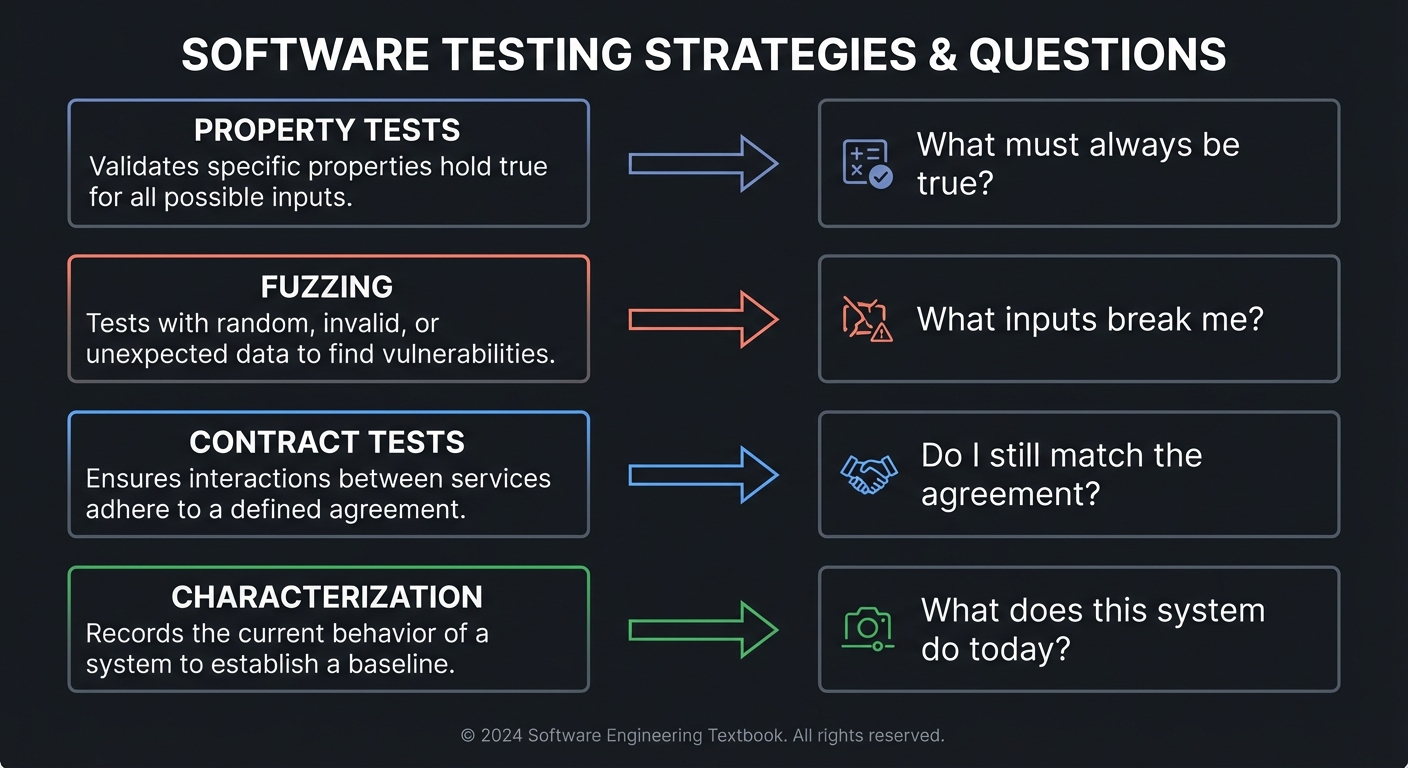
Testing is about evidence that behavior is stable and defensible under change.
3. Code Review as a Risk-Reduction Pipeline
Code review is not a gate; it is a risk filter that reduces uncertainty before production.
IDEA ─> DIFF ─> REVIEW ─> INTEGRATION ─> RELEASE
▲ │
│ └─ Catch: design risks, security, debt
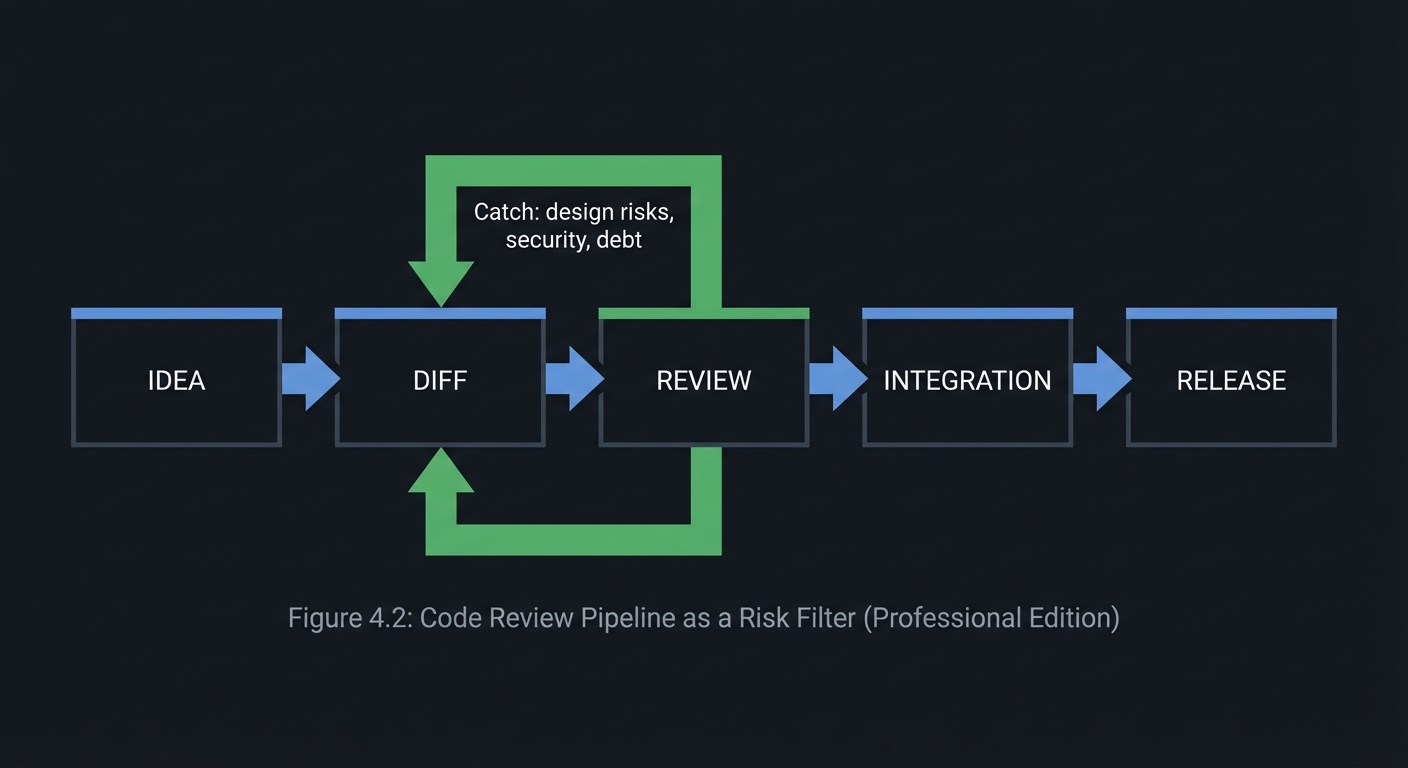
The point of review is to surface assumptions early and agree on tradeoffs.
4. Technical Debt as Interest-Bearing Risk
Technical debt is not a metaphor; it behaves like interest.
Debt Principal: shortcuts in code
Debt Interest: future change cost
Debt Default: inability to safely change

Managing debt means tracking it, pricing it, and choosing when to pay it down.
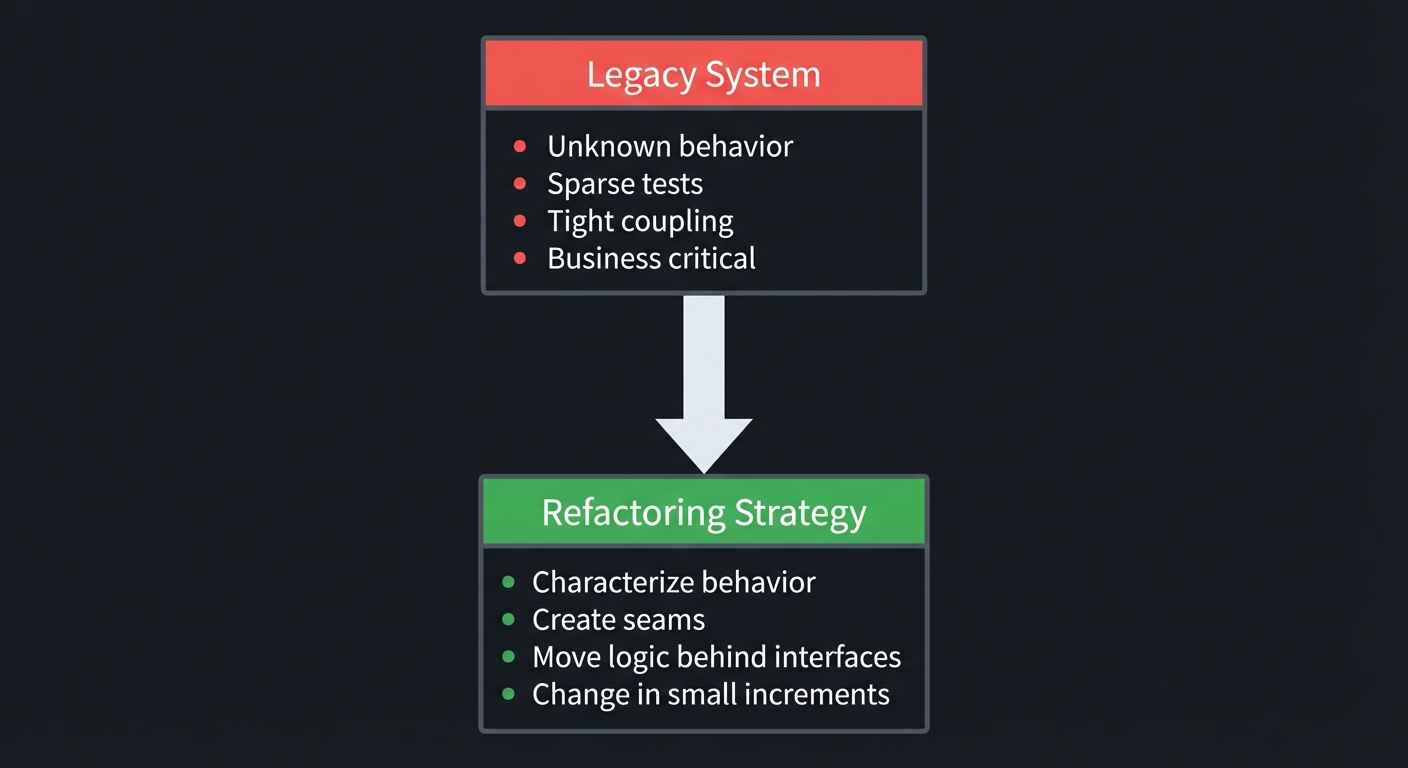
5. Legacy Refactoring as Controlled Change
Legacy systems are often high value and high risk.
Legacy System
┌───────────────────────────────┐
│ Unknown behavior │
│ Sparse tests │
│ Tight coupling │
│ Business critical │
└───────────────────────────────┘
│
▼
Refactoring Strategy
┌───────────────────────────────┐
│ Characterize behavior │
│ Create seams │
│ Move logic behind interfaces │
│ Change in small increments │
└───────────────────────────────┘
Concept Summary Table
| Concept Cluster | What You Need to Internalize |
|---|---|
| Invariants & Contracts | Systems are stable only if their invariants are enforced through evidence. |
| Advanced Testing | Property-based tests, fuzzing, and contracts answer different failure modes. |
| Code Review Workflows | Reviews are structured risk analysis, not just style feedback. |
| Technical Debt | Debt has principal and interest; unmanaged debt slows every future change. |
| Legacy Refactoring | Safe evolution depends on characterization tests and incremental change. |
Deep Dive Reading by Concept
This section maps each concept from above to specific book chapters for deeper understanding. Read these before or alongside the projects to build strong mental models.
Invariants & Contracts
| Concept | Book & Chapter |
|---|---|
| Design by contract mindset | “Code Complete” by Steve McConnell — Ch. 8: “Designing with Contracts” |
| API stability and compatibility | “Designing Data-Intensive Applications” by Martin Kleppmann — Ch. 4: “Encoding and Evolution” |
Advanced Testing
| Concept | Book & Chapter |
|---|---|
| Property-based thinking | “Property-Based Testing” by Fred Hebert — Ch. 1-3 |
| Test strategy and patterns | “xUnit Test Patterns” by Gerard Meszaros — Ch. 1-3 |
| Fuzzing mindset | “The Fuzzing Book” by Andreas Zeller et al. — Ch. 1-2 |
Code Review Workflows
| Concept | Book & Chapter |
|---|---|
| Review culture & efficiency | “Software Engineering at Google” by Winters, Manshreck, Wright — Ch. 9: “Code Review” |
| Human factors in reviews | “Accelerate” by Forsgren, Humble, Kim — Ch. 4: “Continuous Delivery” |
Technical Debt
| Concept | Book & Chapter |
|---|---|
| Debt valuation | “Technical Debt” by Kruchten, Nord, Ozkaya — Ch. 2: “The Technical Debt Metaphor” |
| Refactoring economics | “Refactoring” by Martin Fowler — Ch. 1: “Refactoring, a First Example” |
Legacy Refactoring
| Concept | Book & Chapter |
|---|---|
| Seams and characterization | “Working Effectively with Legacy Code” by Michael Feathers — Ch. 4-6 |
| Incremental change strategy | “The Pragmatic Programmer” by Hunt, Thomas — Ch. 3: “The Essence of Good Design” |
Essential Reading Order
For maximum comprehension, read in this order:
- Foundation (Week 1):
- Code Complete Ch. 8 (contracts, invariants)
- xUnit Test Patterns Ch. 1-3 (test strategy vocabulary)
- Testing Depth (Week 2):
- Property-Based Testing Ch. 1-3
- The Fuzzing Book Ch. 1-2
- Process & Evolution (Week 3):
- Software Engineering at Google Ch. 9
- Working Effectively with Legacy Code Ch. 4-6
Project List
Projects are ordered from foundational practices to advanced, system-level application.
Project 1: Property-Based Invariant Lab
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: Python
- Alternative Programming Languages: Java, Scala, Rust
- Coolness Level: Level 3: Genuinely Clever
- Business Potential: 1. The “Resume Gold”
- Difficulty: Level 2: Intermediate
- Knowledge Area: Testing / Invariants
- Software or Tool: Property-based testing framework
- Main Book: “Property-Based Testing” by Fred Hebert
What you’ll build: A testing harness that generates data to validate invariants for a small but non-trivial domain model (e.g., shopping cart, ledger, or scheduler).
Why it teaches Software Engineering Practices: You will learn to express system behavior as invariants, turning vague expectations into executable evidence.
Core challenges you’ll face:
- Designing invariants that express correctness, not just examples
- Generating edge-case data that reflects real-world constraints
- Distinguishing between model bugs and test oracle bugs
Key Concepts
- Invariants: Code Complete Ch. 8 - McConnell
- Property-Based Strategy: Property-Based Testing Ch. 1-3 - Hebert
- Test Oracles: xUnit Test Patterns Ch. 3 - Meszaros
Difficulty: Intermediate Time estimate: 1-2 weeks Prerequisites: Basic unit testing, familiarity with data modeling, comfortable reading test output
Real World Outcome
You will have a test suite that runs hundreds to thousands of generated scenarios. You will see failing cases shrink to the smallest counterexample, showing exactly which invariant was violated.
Example Output:
$ run-tests --property-suite
Property: cart_total_matches_items ............................. OK (1,000 cases)
Property: no_negative_balances ................................. FAIL (shrunk 47 -> 1)
Minimal failing case:
account_start=0
operations=[withdraw 1]
Invariant violated: balance >= 0
The Core Question You’re Answering
“How can I prove behavior for all inputs instead of just the ones I happen to test?”
Before you write any code, sit with this question. Example-based testing builds confidence, but invariants build trust. This project forces you to think about what must always be true, not just what seems likely.
Concepts You Must Understand First
Stop and research these before coding:
- Invariant Design
- What is a state invariant vs an operation invariant?
- How do invariants differ from test cases?
- Book Reference: “Code Complete” Ch. 8 - McConnell
- Property-Based Testing
- What does it mean to generate arbitrary inputs?
- How does shrinking help you debug faster?
- Book Reference: “Property-Based Testing” Ch. 1-2 - Hebert
Questions to Guide Your Design
Before implementing, think through these:
- Model Boundaries
- What data must always be valid for this domain?
- Which operations could violate invariants?
- Generators
- How will you produce valid and invalid inputs?
- How will you ensure coverage of edge cases?
Thinking Exercise
Invariant Extraction
Before coding, write a minimal domain model in plain English and list its invariants:
Entity: Account
Operations: deposit(amount), withdraw(amount)
State: balance
Questions while analyzing:
- What conditions must always hold after any operation?
- What operations could break those conditions?
- How would you prove that a generated sequence keeps them intact?
The Interview Questions They’ll Ask
Prepare to answer these:
- “How do property-based tests differ from unit tests?”
- “What is a test oracle, and why is it hard to get right?”
- “How do you choose invariants for complex systems?”
- “What does shrinking mean and why is it valuable?”
- “How would you debug a failing property-based test?”
Hints in Layers
Hint 1: Starting Point Pick a domain model with at least two operations that can conflict.
Hint 2: Next Level Write invariants that are agnostic to the order of operations.
Hint 3: Technical Details Use generators that produce sequences, not just single inputs.
Hint 4: Tools/Debugging Use shrinking to reduce failing cases and log the minimal sequence.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Invariants | “Code Complete” by Steve McConnell | Ch. 8 |
| Property-based testing | “Property-Based Testing” by Fred Hebert | Ch. 1-3 |
| Test oracles | “xUnit Test Patterns” by Gerard Meszaros | Ch. 3 |
Implementation Hints Focus on defining invariants in plain language first, then translate them into properties. Keep your model small but realistic, and allow sequences of operations so you can see order-dependent failures.
Learning milestones:
- You can write properties that explain system rules
- You can debug a failing property and find the root invariant violation
- You trust generated tests more than hand-picked examples
Project 2: Fuzzing the Parser
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: C
- Alternative Programming Languages: Rust, Go, Java
- Coolness Level: Level 4: Hardcore Tech Flex
- Business Potential: 3. The “Service & Support” Model
- Difficulty: Level 3: Advanced
- Knowledge Area: Testing / Fuzzing
- Software or Tool: Fuzzer + sanitizer toolchain
- Main Book: “The Fuzzing Book” by Andreas Zeller et al.
What you’ll build: A fuzzing harness for a small file or message parser (JSON subset, config format, or protocol header parser).
Why it teaches Software Engineering Practices: Fuzzing exposes the hidden assumptions and brittle edges that conventional tests never find.
Core challenges you’ll face:
- Creating meaningful input mutations without invalidating structure
- Detecting crashes, hangs, and memory safety violations
- Prioritizing fixes based on failure impact
Key Concepts
- Fuzzing Fundamentals: The Fuzzing Book Ch. 1-2 - Zeller et al.
- Parsing Robustness: Code Complete Ch. 22 - McConnell
- Input Validation: Writing Solid Code Ch. 3 - Maguire
Difficulty: Advanced Time estimate: 1-2 weeks Prerequisites: Basic parsing knowledge, comfort with debugging crashes, understanding of runtime checks
Real World Outcome
You will have a fuzzer that continuously feeds your parser mutated inputs and reports the exact cases that crash or hang it. You will see a queue of failing inputs and a small corpus of interesting test cases.
Example Output:
$ run-fuzzer --target parser
Runs: 120000 Crashes: 2 Hangs: 1
Latest crash input saved to: corpus/crash_002
Minimized input size: 12 bytes
The Core Question You’re Answering
“What inputs can make my software misbehave that I never thought to test?”
Before you write any code, sit with this question. If you can’t predict every input, you must design for surprise.
Concepts You Must Understand First
Stop and research these before coding:
- Parser Failure Modes
- What is a malformed input vs an unexpected input?
- How do parsers typically fail (crash, hang, wrong output)?
- Book Reference: “The Fuzzing Book” Ch. 1 - Zeller et al.
- Input Validation
- Where should validation live: at the edges or in the core?
- What is the risk of over-trusting structure?
- Book Reference: “Writing Solid Code” Ch. 3 - Maguire
Questions to Guide Your Design
Before implementing, think through these:
- Corpus Strategy
- What minimal valid inputs will you seed?
- How will you ensure coverage of distinct parser paths?
- Failure Classification
- How will you separate crashes from timeouts?
- What constitutes a high-severity failure?
Thinking Exercise
Failure Surface Mapping
Before coding, draw a parser pipeline and mark where errors can occur:
INPUT -> TOKENIZE -> PARSE -> VALIDATE -> OUTPUT
Questions while analyzing:
- Where could malformed input create infinite loops?
- Which stage is most fragile under mutation?
- How would you detect silent corruption?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is fuzzing and when is it more useful than unit tests?”
- “How do you minimize a crashing input?”
- “What is coverage-guided fuzzing?”
- “How do you triage fuzzing findings?”
- “What is the difference between a hang and a crash?”
Hints in Layers
Hint 1: Starting Point Choose a parser with a strict grammar and a small valid sample.
Hint 2: Next Level Add mutations that preserve structure, not just random bytes.
Hint 3: Technical Details Track crash inputs and reduce them to minimal reproductions.
Hint 4: Tools/Debugging Use sanitizers or crash logs to identify failure class quickly.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Fuzzing basics | “The Fuzzing Book” by Zeller et al. | Ch. 1-2 |
| Defensive coding | “Writing Solid Code” by Steve Maguire | Ch. 3 |
| Parsing robustness | “Code Complete” by Steve McConnell | Ch. 22 |
Implementation Hints Start with a known-good corpus, then add mutations that target delimiters, lengths, and nesting. Treat every crash as a contract failure and write a regression test for it.
Learning milestones:
- You generate inputs that break your parser in new ways
- You classify failures and prioritize fixes
- You build a process for preventing regressions
Project 3: Consumer-Driven Contract Suite
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: JavaScript
- Alternative Programming Languages: Java, Go, Python
- Coolness Level: Level 3: Genuinely Clever
- Business Potential: 4. The “Open Core” Infrastructure
- Difficulty: Level 3: Advanced
- Knowledge Area: Testing / Contracts
- Software or Tool: Contract testing framework
- Main Book: “Software Engineering at Google” by Winters, Manshreck, Wright
What you’ll build: A consumer-driven contract testing setup for a small API provider/consumer pair.
Why it teaches Software Engineering Practices: It forces you to formalize cross-team expectations and detect breaking changes before integration.
Core challenges you’ll face:
- Writing contracts that are stable yet meaningful
- Managing contract versions and compatibility
- Integrating contract verification into CI
Key Concepts
- Contract Testing: Software Engineering at Google Ch. 9 - Winters et al.
- API Evolution: Designing Data-Intensive Applications Ch. 4 - Kleppmann
- Test Strategy: xUnit Test Patterns Ch. 2 - Meszaros
Difficulty: Advanced Time estimate: 1-2 weeks Prerequisites: Basic API design, familiarity with CI pipelines, testing fundamentals
Real World Outcome
You will have a contract test report that shows whether the provider still satisfies all consumer expectations, with a clear pass/fail status for each contract.
Example Output:
$ run-contracts --provider inventory-api
Contract: catalog-list ............ PASS
Contract: item-details ............ PASS
Contract: price-calculation ....... FAIL
Reason: missing field "currency"
The Core Question You’re Answering
“How do teams evolve APIs without breaking each other?”
Before you write any code, sit with this question. Contract tests turn implicit assumptions into explicit, enforceable agreements.
Concepts You Must Understand First
Stop and research these before coding:
- API Compatibility
- What constitutes a breaking change?
- How do optional fields affect contracts?
- Book Reference: “Designing Data-Intensive Applications” Ch. 4 - Kleppmann
- Test Isolation
- Why do provider and consumer tests run separately?
- How can you avoid environment coupling?
- Book Reference: “xUnit Test Patterns” Ch. 2 - Meszaros
Questions to Guide Your Design
Before implementing, think through these:
- Contract Granularity
- Which endpoints are most critical to lock down?
- Which fields are essential vs optional?
- Version Strategy
- How will you evolve contracts over time?
- How will you archive old contracts?
Thinking Exercise
Contract Framing
Before coding, list one API endpoint and draft its contract in natural language:
Endpoint: GET /items/{id}
Contract: Always returns id, name, price, and currency
Questions while analyzing:
- Which fields are mandatory for the consumer to function?
- What are valid and invalid response shapes?
- How would you detect a breaking change?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is the difference between contract tests and integration tests?”
- “How do you handle backward compatibility in APIs?”
- “What happens when a contract fails in CI?”
- “How do you version contracts?”
- “Why are consumer-driven contracts valuable?”
Hints in Layers
Hint 1: Starting Point Start with one consumer and one critical endpoint.
Hint 2: Next Level Write contracts that describe shape and required fields.
Hint 3: Technical Details Add CI gates so provider builds verify all active contracts.
Hint 4: Tools/Debugging Track contract failures as compatibility regressions, not test flakiness.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Code review and contracts | “Software Engineering at Google” by Winters et al. | Ch. 9 |
| API evolution | “Designing Data-Intensive Applications” by Kleppmann | Ch. 4 |
| Test structure | “xUnit Test Patterns” by Meszaros | Ch. 2 |
Implementation Hints Focus on agreements that matter most to consumers, then expand. Keep contracts stable and document why fields exist so changes are deliberate.
Learning milestones:
- You can define and verify a contract end-to-end
- You can detect breaking changes before integration
- You understand compatibility tradeoffs in API evolution
Project 4: Mutation Testing Quality Gate
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: Java
- Alternative Programming Languages: Python, JavaScript, C#
- Coolness Level: Level 3: Genuinely Clever
- Business Potential: 2. The “Micro-SaaS / Pro Tool”
- Difficulty: Level 3: Advanced
- Knowledge Area: Testing / Quality Metrics
- Software or Tool: Mutation testing tool
- Main Book: “xUnit Test Patterns” by Gerard Meszaros
What you’ll build: A mutation testing pipeline that scores how effective a test suite is at detecting real faults.
Why it teaches Software Engineering Practices: It exposes the gap between code coverage and actual defect detection.
Core challenges you’ll face:
- Selecting mutation operators that reflect real bugs
- Interpreting mutation scores without gaming
- Integrating mutation results into team workflows
Key Concepts
- Test effectiveness: xUnit Test Patterns Ch. 1 - Meszaros
- Coverage limitations: Code Complete Ch. 22 - McConnell
- Quality gates: Accelerate Ch. 4 - Forsgren et al.
Difficulty: Advanced Time estimate: 1-2 weeks Prerequisites: Existing test suite, CI familiarity, comfort with test failures
Real World Outcome
You will have a mutation report showing which parts of your code are tested well and which are not, with a numeric score and list of surviving mutants.
Example Output:
$ run-mutation-tests
Mutation score: 62%
Surviving mutants:
- changed == to != in PricingRules
- removed null check in UserService
The Core Question You’re Answering
“Do my tests actually catch bugs, or do they just give me coverage numbers?”
Before you write any code, sit with this question. Mutation testing forces you to prove that tests detect faults, not just lines executed.
Concepts You Must Understand First
Stop and research these before coding:
- Test Effectiveness
- What is the difference between coverage and confidence?
- Why do some tests pass even when logic is wrong?
- Book Reference: “xUnit Test Patterns” Ch. 1 - Meszaros
- Mutation Operators
- Which kinds of faults are realistic for your domain?
- How do you avoid trivial or meaningless mutants?
- Book Reference: “Code Complete” Ch. 22 - McConnell
Questions to Guide Your Design
Before implementing, think through these:
- Scope
- Which modules are critical enough to mutate first?
- How will you keep mutation runtime reasonable?
- Actionability
- How will developers interpret and respond to low scores?
- What is your threshold for a failing gate?
Thinking Exercise
Fault Imagination
Before coding, list three realistic bugs for a core module:
Module: PricingRules
Potential faults: wrong comparison, missing boundary check, incorrect default
Questions while analyzing:
- Would your current tests detect each fault?
- If not, what assertion would reveal it?
- Is the missing test about logic or data variety?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is mutation testing and why use it?”
- “Why is line coverage not enough?”
- “How do you choose mutation operators?”
- “What does a low mutation score actually mean?”
- “How do you avoid flakiness in mutation testing?”
Hints in Layers
Hint 1: Starting Point Pick a small but important module with an existing test suite.
Hint 2: Next Level Interpret the first report as a diagnostic, not a failure.
Hint 3: Technical Details Focus on surviving mutants that represent meaningful logic changes.
Hint 4: Tools/Debugging Use mutation results to prioritize missing tests, not to chase 100%.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Test effectiveness | “xUnit Test Patterns” by Meszaros | Ch. 1 |
| Coverage limits | “Code Complete” by McConnell | Ch. 22 |
| Quality gates | “Accelerate” by Forsgren et al. | Ch. 4 |
Implementation Hints Aim for actionable insights: record which mutants survive and why. Use the report to drive discussions about test depth, not just metrics.
Learning milestones:
- You can interpret mutation reports meaningfully
- You identify tests that give false confidence
- You create a feedback loop for test quality
Project 5: Code Review Risk Radar
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: Python
- Alternative Programming Languages: JavaScript, Go, Ruby
- Coolness Level: Level 3: Genuinely Clever
- Business Potential: 2. The “Micro-SaaS / Pro Tool”
- Difficulty: Level 2: Intermediate
- Knowledge Area: Code Review / Workflow
- Software or Tool: Git hosting API
- Main Book: “Software Engineering at Google” by Winters, Manshreck, Wright
What you’ll build: A review workflow assistant that summarizes risks for a pull request (size, test coverage changes, ownership, and hotspots).
Why it teaches Software Engineering Practices: It formalizes review as a risk assessment process rather than subjective feedback.
Core challenges you’ll face:
- Defining measurable review risk signals
- Balancing automation with human judgment
- Integrating with existing review workflows
Key Concepts
- Code Review Culture: Software Engineering at Google Ch. 9 - Winters et al.
- Risk Management: Accelerate Ch. 4 - Forsgren et al.
- Change Size: Code Complete Ch. 24 - McConnell
Difficulty: Intermediate Time estimate: 1-2 weeks Prerequisites: Git fundamentals, basic API usage, understanding of PR workflows
Real World Outcome
You will have a report generated for each pull request that highlights risk factors and suggests review focus areas.
Example Output:
$ review-radar --pr 1842
Risk Score: 7/10
Signals:
- Large change size (1,240 lines)
- Touches 4 high-churn files
- Tests changed: no
- Ownership: 1 reviewer with domain knowledge
Suggested focus: API compatibility, rollback strategy
The Core Question You’re Answering
“How do we make code review consistent and focused on real risk?”
Before you write any code, sit with this question. Reviews fail when they are vague, unfocused, or overloaded.
Concepts You Must Understand First
Stop and research these before coding:
- Review Objectives
- What should reviews actually optimize for?
- What kinds of defects are reviews best at catching?
- Book Reference: “Software Engineering at Google” Ch. 9 - Winters et al.
- Risk Signals
- What metrics predict higher defect rates?
- How does change size affect review quality?
- Book Reference: “Code Complete” Ch. 24 - McConnell
Questions to Guide Your Design
Before implementing, think through these:
- Signal Quality
- Which signals are evidence, and which are noise?
- How will you avoid false alarms?
- Human Workflow
- How will this fit into existing PR review habits?
- How will you make the report actionable?
Thinking Exercise
Review Heat Map
Before coding, analyze three recent PRs and label risk factors:
PR A: 150 lines, tests added, single module
PR B: 2,000 lines, no tests, cross-cutting changes
PR C: 50 lines, config-only change
Questions while analyzing:
- Which PR needs the deepest review, and why?
- What signals best explain that need?
- How would you express that risk numerically?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is the purpose of code review besides catching bugs?”
- “How does change size affect review quality?”
- “What review signals indicate higher risk?”
- “How do you prevent review fatigue?”
- “What should be automated vs manual in reviews?”
Hints in Layers
Hint 1: Starting Point Start with simple signals: change size, test changes, ownership.
Hint 2: Next Level Add historical churn data to highlight hotspots.
Hint 3: Technical Details Compute a risk score that is interpretable, not just numeric.
Hint 4: Tools/Debugging Compare your score to known incidents to see if it matches intuition.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Code review | “Software Engineering at Google” by Winters et al. | Ch. 9 |
| Risk signals | “Code Complete” by McConnell | Ch. 24 |
| Delivery performance | “Accelerate” by Forsgren et al. | Ch. 4 |
Implementation Hints Keep the output actionable. A reviewer should see where to focus, not just a wall of metrics.
Learning milestones:
- You can quantify review risk consistently
- You can align review focus to measurable signals
- You treat review as a structured risk filter
Project 6: Technical Debt Interest Ledger
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: Python
- Alternative Programming Languages: Java, Go, JavaScript
- Coolness Level: Level 2: Practical but Forgettable
- Business Potential: 3. The “Service & Support” Model
- Difficulty: Level 2: Intermediate
- Knowledge Area: Technical Debt / Metrics
- Software or Tool: Issue tracker + static analysis
- Main Book: “Technical Debt” by Kruchten, Nord, Ozkaya
What you’ll build: A debt registry that tracks debt items, ownership, impact, and estimated interest cost over time.
Why it teaches Software Engineering Practices: It turns vague debt conversations into quantified decisions with clear tradeoffs.
Core challenges you’ll face:
- Defining debt categories that reflect real pain
- Estimating interest in measurable terms
- Creating a workflow that encourages repayment
Key Concepts
- Debt Valuation: Technical Debt Ch. 2 - Kruchten et al.
- Refactoring Economics: Refactoring Ch. 1 - Fowler
- Sustainable Delivery: Accelerate Ch. 4 - Forsgren et al.
Difficulty: Intermediate Time estimate: 1-2 weeks Prerequisites: Familiarity with issue tracking, basic metrics thinking
Real World Outcome
You will have a living debt ledger that shows current debt, cost of delay, and priority order.
Example Output:
$ debt-ledger report
Debt Items: 14
High Interest:
- D-003: Hardcoded pricing rules (interest: 5 hrs/week)
- D-009: Legacy auth module (interest: 3 hrs/week)
The Core Question You’re Answering
“How do we make technical debt visible and decision-ready?”
Before you write any code, sit with this question. Debt unmanaged becomes invisible until it blocks change.
Concepts You Must Understand First
Stop and research these before coding:
- Debt Types
- What is design debt vs code debt?
- How does debt differ from defects?
- Book Reference: “Technical Debt” Ch. 2 - Kruchten et al.
- Cost of Delay
- How do you measure interest in practical terms?
- What signals indicate accelerating debt cost?
- Book Reference: “Refactoring” Ch. 1 - Fowler
Questions to Guide Your Design
Before implementing, think through these:
- Measurement
- What metrics reflect time lost due to debt?
- How will you quantify impact across teams?
- Workflow
- How will debt be created, reviewed, and retired?
- How will you prevent the ledger from going stale?
Thinking Exercise
Debt Pricing
Before coding, take one known debt and estimate its interest:
Debt: Duplicate business logic in pricing
Interest: 2 extra hours for every new pricing change
Questions while analyzing:
- How often does this area change?
- What is the observable cost of each change?
- How would you justify prioritizing repayment?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is technical debt and how do you measure it?”
- “What is the difference between debt and bugs?”
- “How do you prioritize debt repayment?”
- “How can teams avoid accumulating unbounded debt?”
- “What metrics indicate debt is hurting velocity?”
Hints in Layers
Hint 1: Starting Point Start with a small list of known debt items and owners.
Hint 2: Next Level Attach a concrete cost to each item, even if rough.
Hint 3: Technical Details Group debt by system boundaries so ownership is clear.
Hint 4: Tools/Debugging Track resolved debt to prove the ledger reduces real pain.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Debt valuation | “Technical Debt” by Kruchten et al. | Ch. 2 |
| Refactoring economics | “Refactoring” by Fowler | Ch. 1 |
| Delivery metrics | “Accelerate” by Forsgren et al. | Ch. 4 |
Implementation Hints Keep the ledger lightweight and visible. It must be used in planning, not filed away.
Learning milestones:
- You can articulate debt in concrete cost terms
- You can prioritize debt based on impact
- You can show reduced change friction after repayment
Project 7: Golden Master for Legacy Behavior
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: Python
- Alternative Programming Languages: Java, C#, Go
- Coolness Level: Level 2: Practical but Forgettable
- Business Potential: 3. The “Service & Support” Model
- Difficulty: Level 3: Advanced
- Knowledge Area: Legacy Refactoring
- Software or Tool: Snapshot testing tool
- Main Book: “Working Effectively with Legacy Code” by Michael Feathers
What you’ll build: A characterization test harness that captures current system behavior as a “golden master” before refactoring.
Why it teaches Software Engineering Practices: It teaches how to make safe changes when the only truth you have is current behavior.
Core challenges you’ll face:
- Choosing input scenarios that represent real usage
- Handling non-deterministic outputs
- Maintaining snapshots without masking defects
Key Concepts
- Characterization Tests: Working Effectively with Legacy Code Ch. 4 - Feathers
- Snapshot Strategy: xUnit Test Patterns Ch. 7 - Meszaros
- Refactoring Safety: Refactoring Ch. 1 - Fowler
Difficulty: Advanced Time estimate: 1-2 weeks Prerequisites: Existing legacy system, ability to run it in a test environment
Real World Outcome
You will have a suite of snapshot tests that capture current behavior, with diff outputs when behavior changes.
Example Output:
$ run-characterization-tests
Scenario: pricing-basic ............ PASS
Scenario: pricing-discount ......... FAIL
Diff:
- total: 109.99
+ total: 104.99
The Core Question You’re Answering
“How can I change a system safely when I do not fully understand it?”
Before you write any code, sit with this question. Legacy refactoring starts with seeing the system clearly, not rewriting it blindly.
Concepts You Must Understand First
Stop and research these before coding:
- Characterization Testing
- What makes a test a characterization test?
- Why is “current behavior” the baseline?
- Book Reference: “Working Effectively with Legacy Code” Ch. 4 - Feathers
- Test Determinism
- How do you isolate time, randomness, or external dependencies?
- How do you avoid brittle snapshots?
- Book Reference: “xUnit Test Patterns” Ch. 7 - Meszaros
Questions to Guide Your Design
Before implementing, think through these:
- Scenario Selection
- What are the most critical workflows to capture?
- Which edge cases are most likely to break?
- Snapshot Discipline
- What counts as a meaningful difference?
- How will you review and approve changes?
Thinking Exercise
Behavior Inventory
Before coding, list five behaviors the system must preserve:
Behavior: discount applies only to premium accounts
Behavior: tax is rounded to two decimals
Questions while analyzing:
- Which behavior is implicit but critical?
- Which behavior is business-defined vs accidental?
- How can you observe this behavior clearly?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is a characterization test?”
- “How do you refactor without breaking legacy behavior?”
- “How do you handle non-deterministic outputs?”
- “What makes a snapshot test brittle?”
- “When should you update a golden master?”
Hints in Layers
Hint 1: Starting Point Choose a workflow you can run repeatedly with stable output.
Hint 2: Next Level Add multiple scenarios to cover boundary cases.
Hint 3: Technical Details Normalize outputs to remove timestamps or random IDs.
Hint 4: Tools/Debugging Use diffs to highlight behavior changes and require explicit approval.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Legacy safety | “Working Effectively with Legacy Code” by Feathers | Ch. 4-6 |
| Snapshot testing | “xUnit Test Patterns” by Meszaros | Ch. 7 |
| Refactoring basics | “Refactoring” by Fowler | Ch. 1 |
Implementation Hints Start with a single deterministic scenario. Build confidence by capturing output shape, then expand to edge cases.
Learning milestones:
- You can freeze legacy behavior into tests
- You can refactor with confidence using snapshots
- You can separate accidental behavior from intentional behavior
Project 8: Strangler Fig Refactor Simulator
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: Java
- Alternative Programming Languages: C#, Go, Python
- Coolness Level: Level 3: Genuinely Clever
- Business Potential: 4. The “Open Core” Infrastructure
- Difficulty: Level 3: Advanced
- Knowledge Area: Legacy Refactoring / Architecture
- Software or Tool: Reverse proxy or routing layer
- Main Book: “Working Effectively with Legacy Code” by Michael Feathers
What you’ll build: A small routing layer that splits traffic between a legacy system and a new subsystem, enabling gradual migration.
Why it teaches Software Engineering Practices: It shows how to refactor safely without big-bang rewrites.
Core challenges you’ll face:
- Designing seams that minimize coupling
- Ensuring behavior parity between old and new
- Handling rollback and dual-run strategies
Key Concepts
- Seams and Isolation: Working Effectively with Legacy Code Ch. 5 - Feathers
- Incremental Refactoring: Refactoring Ch. 1 - Fowler
- Change Safety Nets: Release It! Ch. 2 - Nygard
Difficulty: Advanced Time estimate: 1-2 weeks Prerequisites: Basic networking or routing knowledge, familiarity with system boundaries
Real World Outcome
You will have a routing layer that can direct a percentage of requests to the new implementation while preserving fallback to legacy.
Example Output:
$ route-status
Legacy: 80%
New: 20%
Errors (new): 0.4%
Rollback threshold: 1.0%
The Core Question You’re Answering
“How do you replace a legacy system without stopping the world?”
Before you write any code, sit with this question. Safe migration is about controlled traffic and reversible decisions.
Concepts You Must Understand First
Stop and research these before coding:
- Seams and Isolation
- What is a seam in code or architecture?
- How do seams reduce refactor risk?
- Book Reference: “Working Effectively with Legacy Code” Ch. 5 - Feathers
- Rollback Strategy
- What makes a change reversible?
- How do you define rollback thresholds?
- Book Reference: “Release It!” Ch. 2 - Nygard
Questions to Guide Your Design
Before implementing, think through these:
- Routing Policy
- What logic determines which system handles a request?
- How will you measure correctness?
- Observability
- What signals will tell you the new system is safe?
- How will you compare outputs between old and new?
Thinking Exercise
Migration Map
Before coding, draw the call flow:
Client -> Router -> Legacy OR New -> Response
Questions while analyzing:
- Where will you insert the routing seam?
- How will you keep old and new in sync?
- What happens if new returns an error?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is the strangler fig pattern?”
- “How do you migrate safely with minimal downtime?”
- “How do you validate behavior parity?”
- “What is a rollback threshold and how is it chosen?”
- “How do you manage partial migrations?”
Hints in Layers
Hint 1: Starting Point Start by routing a small, safe subset of traffic.
Hint 2: Next Level Compare outputs between old and new before switching fully.
Hint 3: Technical Details Add metrics to track error rates by route.
Hint 4: Tools/Debugging Design rollback to be immediate and low-risk.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Legacy seams | “Working Effectively with Legacy Code” by Feathers | Ch. 5 |
| Refactoring strategy | “Refactoring” by Fowler | Ch. 1 |
| Resilience | “Release It!” by Michael Nygard | Ch. 2 |
Implementation Hints Keep routing logic simple and observable. Start with low-risk traffic and increase gradually as confidence grows.
Learning milestones:
- You can isolate legacy behavior behind a seam
- You can route traffic safely between systems
- You can roll back changes confidently
Project 9: Reviewable Change Playbook
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: Markdown
- Alternative Programming Languages: N/A
- Coolness Level: Level 1: Pure Corporate Snoozefest
- Business Potential: 3. The “Service & Support” Model
- Difficulty: Level 1: Beginner
- Knowledge Area: Code Review / Process
- Software or Tool: Documentation and checklist tool
- Main Book: “Software Engineering at Google” by Winters, Manshreck, Wright
What you’ll build: A code review playbook with checklists, severity levels, and example review comments.
Why it teaches Software Engineering Practices: It forces you to define what “good review” means and makes expectations explicit.
Core challenges you’ll face:
- Distilling review goals into clear checklists
- Balancing thoroughness with reviewer time
- Defining severity levels consistently
Key Concepts
- Review Standards: Software Engineering at Google Ch. 9 - Winters et al.
- Quality Culture: Code Complete Ch. 24 - McConnell
- Process Design: The Pragmatic Programmer Ch. 3 - Hunt, Thomas
Difficulty: Beginner Time estimate: Weekend Prerequisites: Familiarity with pull requests and review workflows
Real World Outcome
You will have a practical document used during reviews, with checklists and example questions that reviewers can follow.
Example Output:
$ open review-playbook.md
Sections:
- Functional correctness checklist
- Security and privacy checklist
- Performance and scalability checklist
- Rollback and observability checklist
The Core Question You’re Answering
“What does good code review look like in practice?”
Before you write any code, sit with this question. A playbook turns personal preference into shared standards.
Concepts You Must Understand First
Stop and research these before coding:
- Review Goals
- What risks should review catch?
- What should not be caught in review (automated checks)?
- Book Reference: “Software Engineering at Google” Ch. 9 - Winters et al.
- Checklist Design
- How do checklists reduce cognitive load?
- How do you avoid checklists that are too long?
- Book Reference: “Code Complete” Ch. 24 - McConnell
Questions to Guide Your Design
Before implementing, think through these:
- Scope
- What qualifies as a “high-risk” change?
- Which review questions map to which risks?
- Adoption
- How will you make this easy to use?
- How will you keep it updated?
Thinking Exercise
Review Simulation
Before coding, review a recent change and categorize feedback:
Feedback: missing tests -> correctness risk
Feedback: naming inconsistency -> readability risk
Questions while analyzing:
- Which feedback prevented a real defect?
- Which feedback was style-only noise?
- How would a checklist help?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is the goal of code review?”
- “What types of issues are best caught in review?”
- “How do you avoid review bottlenecks?”
- “What makes a review checklist effective?”
- “How do you handle disagreements in review?”
Hints in Layers
Hint 1: Starting Point Start with a short checklist: correctness, tests, rollback.
Hint 2: Next Level Add severity levels so reviewers can prioritize feedback.
Hint 3: Technical Details Include example comments to model tone and focus.
Hint 4: Tools/Debugging Track adoption by asking reviewers to reference checklist items.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Review standards | “Software Engineering at Google” by Winters et al. | Ch. 9 |
| Quality control | “Code Complete” by McConnell | Ch. 24 |
| Process pragmatism | “The Pragmatic Programmer” by Hunt, Thomas | Ch. 3 |
Implementation Hints Keep the playbook short and visible. It should guide conversations, not create bureaucracy.
Learning milestones:
- You can define review goals clearly
- You can categorize feedback by risk level
- You can create a review culture baseline
Project 10: Legacy Refactor Readiness Audit
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: Python
- Alternative Programming Languages: Java, Go, Ruby
- Coolness Level: Level 2: Practical but Forgettable
- Business Potential: 3. The “Service & Support” Model
- Difficulty: Level 2: Intermediate
- Knowledge Area: Legacy Refactoring / Assessment
- Software or Tool: Static analysis + documentation
- Main Book: “Working Effectively with Legacy Code” by Michael Feathers
What you’ll build: A readiness audit checklist and report that scores a legacy system on refactoring risk and changeability.
Why it teaches Software Engineering Practices: It teaches you to evaluate change risk before touching the system.
Core challenges you’ll face:
- Defining measurable readiness criteria
- Balancing technical and organizational factors
- Producing actionable recommendations
Key Concepts
- Changeability Assessment: Working Effectively with Legacy Code Ch. 3 - Feathers
- Dependency Risk: Code Complete Ch. 19 - McConnell
- Delivery Constraints: Accelerate Ch. 4 - Forsgren et al.
Difficulty: Intermediate Time estimate: Weekend Prerequisites: Familiarity with codebase structure, basic static analysis skills
Real World Outcome
You will have a report that scores a system across dimensions like test coverage, coupling, and deployment risk, with a priority list of improvements.
Example Output:
$ legacy-audit report
Risk Score: 8/10
Key Findings:
- No automated tests in billing module
- 6 cyclic dependencies across core packages
- Deployment requires manual steps
Recommendations:
1) Create characterization tests for billing
2) Break cycle between Order and Pricing modules
3) Automate deployment pipeline
The Core Question You’re Answering
“Is this system ready to be refactored safely?”
Before you write any code, sit with this question. Refactoring without readiness is gambling.
Concepts You Must Understand First
Stop and research these before coding:
- Changeability
- What makes a system hard to change?
- How do dependencies create risk?
- Book Reference: “Working Effectively with Legacy Code” Ch. 3 - Feathers
- Risk Scoring
- What factors correlate with refactor failures?
- How do you weight tests vs coupling vs deployment risk?
- Book Reference: “Code Complete” Ch. 19 - McConnell
Questions to Guide Your Design
Before implementing, think through these:
- Scoring Model
- What criteria matter most for safe refactoring?
- How will you keep scoring consistent across systems?
- Recommendations
- How will you convert scores into actionable steps?
- How will you track improvement over time?
Thinking Exercise
Risk Inventory
Before coding, list three sources of refactor risk:
Risk: no tests in critical module
Risk: high coupling between layers
Risk: manual deployment steps
Questions while analyzing:
- Which risk makes change most dangerous?
- Which risk can be reduced quickly?
- How would you prove improvement?
The Interview Questions They’ll Ask
Prepare to answer these:
- “How do you assess whether a system is ready to refactor?”
- “What factors make refactoring risky?”
- “How do you reduce refactor risk before changing code?”
- “How do you prioritize refactoring work?”
- “What metrics show refactor readiness improving?”
Hints in Layers
Hint 1: Starting Point Start with a checklist of tests, coupling, and deployment risk.
Hint 2: Next Level Add weights to score the most dangerous factors higher.
Hint 3: Technical Details Track improvements over time to show readiness growth.
Hint 4: Tools/Debugging Validate your scores against past incidents or failures.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Legacy changeability | “Working Effectively with Legacy Code” by Feathers | Ch. 3 |
| Dependency risk | “Code Complete” by McConnell | Ch. 19 |
| Delivery metrics | “Accelerate” by Forsgren et al. | Ch. 4 |
Implementation Hints Make the audit results visible and reviewable. The goal is to create a shared understanding of risk, not a perfect score.
Learning milestones:
- You can quantify refactor readiness
- You can identify the highest risk constraints
- You can track readiness improvement over time
Project Comparison Table
| Project | Difficulty | Time | Depth of Understanding | Fun Factor |
|---|---|---|---|---|
| Property-Based Invariant Lab | Intermediate | 1-2 weeks | High | Medium |
| Fuzzing the Parser | Advanced | 1-2 weeks | High | High |
| Consumer-Driven Contract Suite | Advanced | 1-2 weeks | High | Medium |
| Mutation Testing Quality Gate | Advanced | 1-2 weeks | Medium | Medium |
| Code Review Risk Radar | Intermediate | 1-2 weeks | Medium | Medium |
| Technical Debt Interest Ledger | Intermediate | 1-2 weeks | Medium | Low |
| Golden Master for Legacy Behavior | Advanced | 1-2 weeks | High | Medium |
| Strangler Fig Refactor Simulator | Advanced | 1-2 weeks | High | High |
| Reviewable Change Playbook | Beginner | Weekend | Medium | Low |
| Legacy Refactor Readiness Audit | Intermediate | Weekend | Medium | Low |
Recommendation
Start with Project 1: Property-Based Invariant Lab because it trains you to think in invariants, the core mental model behind all the other practices. Then move to Project 7: Golden Master for Legacy Behavior to learn safe change in uncertain systems. After that, choose either Project 2: Fuzzing the Parser for robustness depth or Project 3: Consumer-Driven Contract Suite for cross-team reliability.
Final Overall Project: Practice-Driven Legacy Modernization
- File: SOFTWARE_ENGINEERING_PRACTICES_PROJECTS.md
- Main Programming Language: Python
- Alternative Programming Languages: Java, Go, C#
- Coolness Level: Level 4: Hardcore Tech Flex
- Business Potential: 4. The “Open Core” Infrastructure
- Difficulty: Level 4: Expert
- Knowledge Area: End-to-End Engineering Practices
- Software or Tool: CI/CD pipeline + testing toolchain
- Main Book: “Working Effectively with Legacy Code” by Michael Feathers
What you’ll build: A full modernization effort for a legacy service: add characterization tests, introduce property-based tests for key invariants, add a contract suite for consumers, build a review risk report, and migrate with a strangler layer.
Why it teaches Software Engineering Practices: It forces you to apply every practice in a single, coherent change program.
Core challenges you’ll face:
- Coordinating multiple testing strategies without overlap
- Balancing immediate delivery with debt paydown
- Managing risk across incremental releases
Key Concepts
- Legacy refactoring: Working Effectively with Legacy Code Ch. 4-6 - Feathers
- Refactoring discipline: Refactoring Ch. 1 - Fowler
- Delivery risk: Accelerate Ch. 4 - Forsgren et al.
Difficulty: Expert Time estimate: 1 month+ Prerequisites: Completion of at least three projects above, CI/CD familiarity, comfort with test strategy design
Real World Outcome
You will deliver a legacy system that can be changed safely, with evidence-based tests and a clear migration path. You will have dashboards for test status, contract compliance, review risk, and debt tracking.
Example Output:
$ modernization-status
Contracts: PASS
Property tests: PASS
Fuzzing: 0 crashes
Debt items resolved: 5
Traffic split: Legacy 40% / New 60%
The Core Question You’re Answering
“How do I evolve a critical system without slowing the business or risking outages?”
Before you start, sit with this question. This is the essence of software engineering practice: safe change at speed.
Concepts You Must Understand First
Stop and research these before coding:
- Practice Integration
- How do multiple test layers complement each other?
- What is the right order of adoption?
- Book Reference: “Working Effectively with Legacy Code” Ch. 4-6 - Feathers
- Risk Management
- How do you balance delivery with refactoring?
- What makes a migration reversible?
- Book Reference: “Release It!” Ch. 2 - Nygard
Questions to Guide Your Design
Before implementing, think through these:
- Roadmap
- Which practices must be in place before refactoring?
- How will you stage risk reduction?
- Measurement
- What evidence shows safety improving over time?
- How will you communicate this to stakeholders?
Thinking Exercise
Practice Layering
Before coding, design your adoption sequence:
Step 1: Characterization tests
Step 2: Property-based invariants
Step 3: Contract suite
Step 4: Strangler routing
Questions while analyzing:
- Which step reduces risk the most early on?
- Which dependencies must be in place first?
- How will you prove each step is working?
The Interview Questions They’ll Ask
Prepare to answer these:
- “How do you modernize a legacy system safely?”
- “How do you decide which testing strategies to use?”
- “What is the strangler fig pattern and why use it?”
- “How do you quantify technical debt impact?”
- “How do you manage risk across incremental releases?”
Hints in Layers
Hint 1: Starting Point Begin with characterization tests to freeze behavior.
Hint 2: Next Level Add property-based tests for core invariants.
Hint 3: Technical Details Introduce contracts for API consumers before changing endpoints.
Hint 4: Tools/Debugging Keep a rollback plan at every stage of migration.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Legacy refactoring | “Working Effectively with Legacy Code” by Feathers | Ch. 4-6 |
| Refactoring discipline | “Refactoring” by Fowler | Ch. 1 |
| Release safety | “Release It!” by Nygard | Ch. 2 |
Implementation Hints Focus on sequencing and evidence. Do not rewrite; isolate, measure, and migrate.
Learning milestones:
- You can establish safety nets before change
- You can migrate incrementally with clear rollback
- You can deliver new functionality without regression risk
Summary
| Project | Focus | Outcome |
|---|---|---|
| Property-Based Invariant Lab | Invariants | Evidence of correctness across inputs |
| Fuzzing the Parser | Robustness | Discovered hidden crash cases |
| Consumer-Driven Contract Suite | Compatibility | Prevented breaking API changes |
| Mutation Testing Quality Gate | Test depth | Measured real test effectiveness |
| Code Review Risk Radar | Workflow | Review focus on high-risk changes |
| Technical Debt Interest Ledger | Debt management | Quantified cost of delay |
| Golden Master for Legacy Behavior | Legacy safety | Frozen behavior before refactor |
| Strangler Fig Refactor Simulator | Migration | Safe incremental replacement |
| Reviewable Change Playbook | Process | Shared standards for review quality |
| Legacy Refactor Readiness Audit | Assessment | Measured system changeability |