Project 5: Branch Predictor and Pipeline Lab
Project Overview
| Attribute | Details |
|---|---|
| Difficulty | Advanced |
| Time Estimate | 1-2 weeks |
| Primary Language | C |
| Alternative Languages | C++, Rust, Zig |
| Knowledge Area | CPU Microarchitecture |
| Tools Required | perf, cpu topology tools, objdump |
| Primary Reference | “Computer Architecture: A Quantitative Approach” by Hennessy & Patterson |
Learning Objectives
By completing this project, you will be able to:
- Explain how branch prediction works including common predictor algorithms
- Measure branch misprediction rates using hardware performance counters
- Design workloads that defeat branch prediction to understand worst cases
- Calculate the performance impact of misprediction on pipeline throughput
- Apply branchless programming techniques for unpredictable branches
- Interpret CPI and IPC metrics in the context of pipeline stalls
Deep Theoretical Foundation
The Pipelining Problem
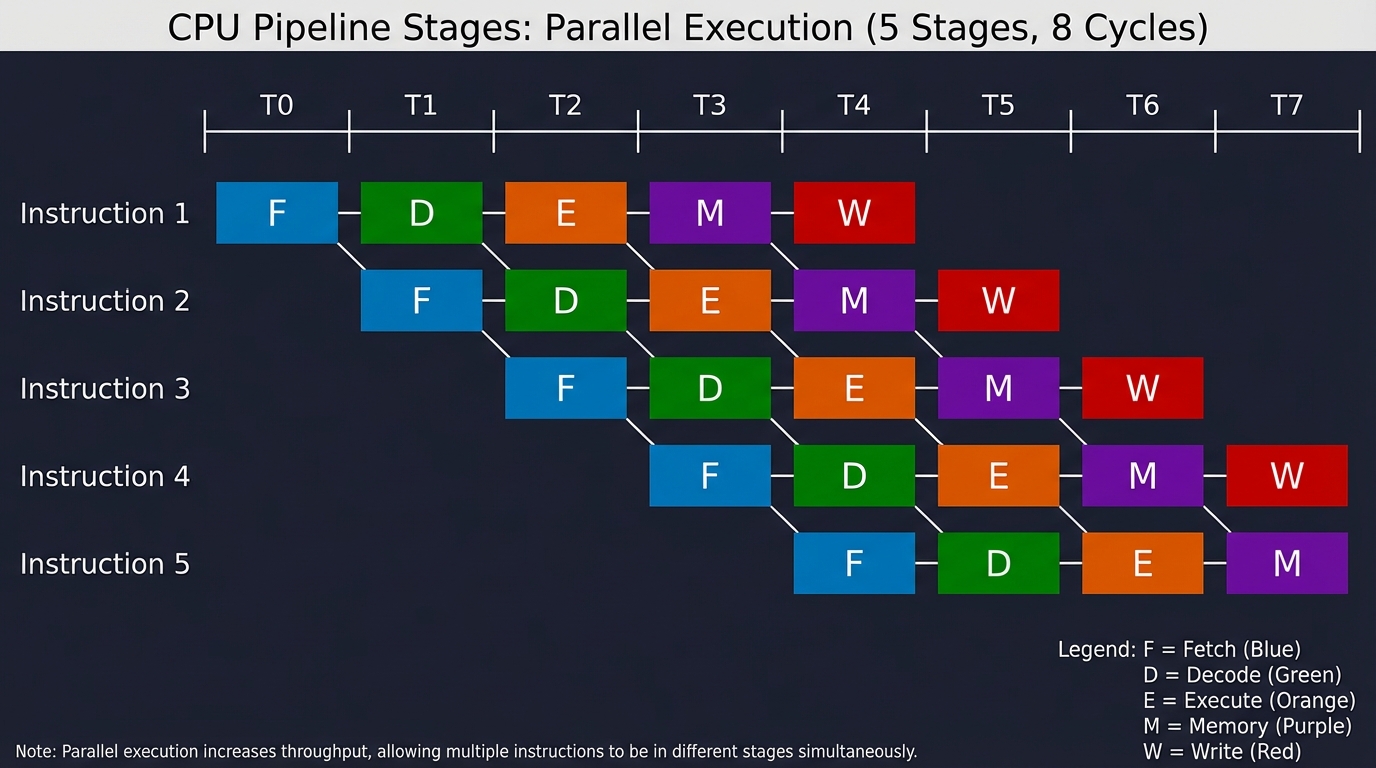
Modern CPUs execute instructions in stages: fetch, decode, execute, memory, writeback. Pipelining allows starting a new instruction every cycle, achieving 1+ instructions/cycle throughput.
Classic 5-Stage Pipeline:
Time → 1 2 3 4 5 6 7 8
Inst 1: [F] [D] [E] [M] [W]
Inst 2: [F] [D] [E] [M] [W]
Inst 3: [F] [D] [E] [M] [W]
Inst 4: [F] [D] [E] [M] [W]
Inst 5: [F] [D] [E] [M] [W]
After startup, one instruction completes every cycle
The Branch Problem: When the CPU fetches a branch instruction, it doesn’t know which instruction comes next until the branch is evaluated (cycle 3 in example). But by then, it’s already fetched 2 more instructions—which may be wrong.
What happens at a branch:
Time → 1 2 3 4 5 6 7 8
Branch: [F] [D] [E] → Branch resolved (taken)
Inst A: [F] [D] [X] ← WRONG PATH - must flush
Inst B: [F] [X] ← WRONG PATH - must flush
Target: [F] [D] [E] [M] [W] ← Correct path starts
Next: [F] [D] [E] [M] [W]
[X] = Wasted work (pipeline flush)
Modern CPUs have 15-20 pipeline stages, meaning a misprediction wastes 15-20 cycles of work.
How Branch Prediction Works
Static Prediction (Simple)
- Backward branches predicted taken (loops usually continue)
- Forward branches predicted not taken (error paths usually not taken)
- ~65-70% accuracy
Two-Level Adaptive Prediction (Modern)
CPUs maintain history of recent branches:
Branch History Table (BHT):
┌──────────────────────────────────────────────────────┐
│ Branch Address → History Pattern → Prediction │
├──────────────────────────────────────────────────────┤
│ 0x401234 → TTTTTTTN → Taken (strong) │
│ 0x401256 → TNTNTNTN → Not Taken │
│ 0x401278 → NNNNNNNN → Not Taken │
└──────────────────────────────────────────────────────┘
T = Taken, N = Not Taken (last 8 outcomes)
The predictor learns patterns. A branch that alternates TNTN can be predicted with 100% accuracy once the pattern is learned.
Branch Target Buffer (BTB)
For taken branches, the CPU also needs to know where to jump. The BTB caches recent branch targets:
BTB:
┌────────────────────────────────────────────────┐
│ Branch Address → Target Address │
├────────────────────────────────────────────────┤
│ 0x401234 → 0x401100 (loop start) │
│ 0x401256 → 0x405000 (function call) │
└────────────────────────────────────────────────┘
What Makes Branches Predictable
Highly Predictable (>99% accuracy):
// Loop control - always taken except last iteration
for (int i = 0; i < 1000; i++) { ... }
// 999 taken, 1 not taken = 99.9% predictable
// Data-dependent but sorted
for (int i = 0; i < n; i++) {
if (sorted_array[i] < threshold) { sum += 1; }
}
// First K iterations taken, rest not taken
// Predictor learns the pattern
Unpredictable (~50% accuracy):
// Random data
for (int i = 0; i < n; i++) {
if (random_array[i] & 1) { sum += 1; }
}
// Outcome depends on random bits - no pattern to learn
// Hash-dependent
for (key in keys) {
if (hash(key) % 2 == 0) { process(key); }
}
// Hash output is pseudorandom
The Cost of Misprediction
Direct Cost: Pipeline flush and refill = 15-20 cycles
Indirect Cost: Lost instruction-level parallelism (ILP)
Consider:
- CPU can execute 4+ instructions per cycle (superscalar)
- With perfect prediction, IPC = 2-4
- With 50% misprediction on frequent branches, IPC drops to <1
The Math:
Given:
- Branch every 5 instructions
- 50% misprediction rate
- 18-cycle misprediction penalty
Effective cycles per branch:
(0.50 × 1 cycle) + (0.50 × 18 cycles) = 9.5 cycles
For every 5 instructions:
5 instructions + 9.5 cycles = ~2.5 cycles/instruction
Result: IPC = 0.4 (vs theoretical 4.0)
Complete Project Specification
What You’re Building
An experimental toolkit called branch_lab that:
- Generates workloads with controlled branch patterns (sorted, random, alternating)
- Measures branch misprediction rates and CPI using hardware counters
- Compares predictable vs unpredictable patterns quantitatively
- Demonstrates branchless alternatives and their performance characteristics
- Produces reports connecting branch behavior to throughput
Functional Requirements
branch_lab run --pattern <name> --size <n> --iters <n>
branch_lab compare --patterns <list> --size <n>
branch_lab branchless --pattern <name> --compare
branch_lab report --output <report.md>
Branch Patterns to Implement
- always_taken: Branch condition always true
- never_taken: Branch condition always false
- sorted: Threshold on sorted data (predictable transition)
- random_50: 50/50 random outcomes
- biased_90: 90% one way, 10% other
- alternating: Strict TNTNTN pattern
- period_4: TTNNTTNN repeating
Example Output
Branch Prediction Report
═══════════════════════════════════════════════════
Array size: 100,000,000 elements
Iterations: 10
CPU: Intel Core i7-12700K
Pattern Comparison:
───────────────────────────────────────────────────
Pattern Time CPI IPC Mispredict%
always_taken 124 ms 0.78 2.94 0.01%
sorted 127 ms 0.81 2.87 0.12%
biased_90 168 ms 1.02 2.12 8.7%
alternating 245 ms 1.34 1.54 0.8%
random_50 487 ms 2.94 0.89 48.3%
Performance Impact Analysis:
───────────────────────────────────────────────────
• random_50 is 3.9x slower than always_taken
• 48.3% misprediction rate costs 2.16 extra cycles/instruction
• Sorting the data would provide 3.8x speedup
Branchless Comparison (random_50 pattern):
───────────────────────────────────────────────────
Implementation Time Relative
branchy 487 ms 1.0x (baseline)
cmov 298 ms 1.6x faster
bitwise_mask 312 ms 1.5x faster
Branchless wins for unpredictable data!
Solution Architecture
Component Design
┌─────────────────────────────────────────────────────────────┐
│ CLI Interface │
│ Pattern selection, size configuration │
└──────────────────────────┬──────────────────────────────────┘
│
┌────────────────┼────────────────┐
│ │ │
▼ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Pattern │ │ Counter │ │ Branchless │
│ Generator │ │ Collector │ │ Variants │
│ │ │ (perf) │ │ │
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
└────────────────┼────────────────┘
│
▼
┌───────────────────────────────┐
│ Measurement Loop │
│ Run workload → Collect stats │
└───────────────┬───────────────┘
│
▼
┌───────────────────────────────┐
│ Analysis & Report │
│ Calculate CPI, compare │
└───────────────────────────────┘
Key Data Structures
// Branch pattern generator
typedef void (*pattern_generator_t)(int *data, size_t count, int threshold);
typedef struct {
const char *name;
pattern_generator_t generator;
float expected_mispredict_rate; // For validation
const char *description;
} pattern_t;
// Branch measurement result
typedef struct {
double wall_time_ms;
uint64_t instructions;
uint64_t cycles;
uint64_t branches;
uint64_t branch_misses;
double cpi; // cycles per instruction
double ipc; // instructions per cycle
double mispredict_rate;
} branch_result_t;
Workload Implementation
// The core branch-heavy workload
// This must NOT be optimized away by compiler
volatile int64_t benchmark_branchy(int *data, size_t n, int threshold) {
volatile int64_t sum = 0;
for (size_t i = 0; i < n; i++) {
if (data[i] < threshold) { // THE BRANCH
sum += data[i];
}
}
return sum;
}
// Branchless equivalent using conditional move
volatile int64_t benchmark_branchless(int *data, size_t n, int threshold) {
volatile int64_t sum = 0;
for (size_t i = 0; i < n; i++) {
int mask = -(data[i] < threshold); // -1 or 0
sum += data[i] & mask; // No branch!
}
return sum;
}
Pattern Generators
// Sorted data - highly predictable
void generate_sorted(int *data, size_t count, int threshold) {
for (size_t i = 0; i < count; i++) {
data[i] = i; // Sorted ascending
}
}
// Random data - unpredictable
void generate_random(int *data, size_t count, int threshold) {
for (size_t i = 0; i < count; i++) {
data[i] = rand();
}
}
// Biased random (90% below threshold)
void generate_biased_90(int *data, size_t count, int threshold) {
for (size_t i = 0; i < count; i++) {
if (rand() % 10 < 9) {
data[i] = rand() % threshold; // Below threshold
} else {
data[i] = threshold + rand(); // Above threshold
}
}
}
// Alternating TNTN pattern
void generate_alternating(int *data, size_t count, int threshold) {
for (size_t i = 0; i < count; i++) {
data[i] = (i % 2) ? threshold + 1 : 0;
}
}
Phased Implementation Guide
Phase 1: Basic Branch Benchmark (Days 1-3)
Goal: Measure branch misprediction for sorted vs random data.
Steps:
- Create array with configurable data pattern
- Implement the branchy workload with threshold comparison
- Use
perf statto measure branch-misses - Compare sorted (predictable) vs random (unpredictable)
Validation: Random should have ~50% misprediction, sorted ~0%.
Phase 2: Hardware Counter Integration (Days 4-6)
Goal: Use perf_event_open for detailed branch metrics.
Steps:
- Configure counters for:
PERF_COUNT_HW_BRANCH_INSTRUCTIONSPERF_COUNT_HW_BRANCH_MISSESPERF_COUNT_HW_CPU_CYCLESPERF_COUNT_HW_INSTRUCTIONS
- Calculate CPI and IPC
- Verify counter accuracy against perf stat
Validation: CPI should increase with misprediction rate.
Phase 3: Branchless Alternatives (Days 7-9)
Goal: Implement and compare branchless versions.
Steps:
- Implement CMOV-based branchless version
- Implement bitwise mask version
- Verify correctness (same results)
- Compare performance for each pattern
Validation: Branchless should win for random data.
Phase 4: Pattern Library (Days 10-11)
Goal: Comprehensive pattern coverage.
Steps:
- Implement all listed patterns
- Add expected misprediction rate annotations
- Create comparison framework
- Generate pattern analysis report
Validation: Measured rates match expectations (±5%).
Phase 5: Assembly Verification (Days 12-14)
Goal: Verify compiler generates expected code.
Steps:
- Use objdump to inspect generated assembly
- Verify branchy version has conditional jumps
- Verify branchless version has CMOV
- Document optimization flags that change behavior
Validation: Assembly matches intent.
Testing Strategy
Micro-Benchmarks
- Always-taken: Should have ~0% misprediction
- Always-not-taken: Should have ~0% misprediction
- Alternating: Should have 0-2% (modern predictors learn patterns)
- Random 50/50: Should have 45-50% misprediction
Cross-Validation
- Compare with perf stat: Counters should match
- Vary array size: Results should be consistent
- Multiple runs: Low variance expected
Compiler Verification
- Check for auto-vectorization: May bypass branches entirely
- Verify no dead-code elimination: Results must be used
- Test multiple optimization levels: -O0, -O1, -O2, -O3
Common Pitfalls and Debugging
Pitfall 1: Compiler Optimizes Away the Branch
Symptom: Branchy and branchless have identical performance.
Cause: Compiler auto-vectorized or used CMOV automatically.
Solution:
# Compile with specific flags to preserve branches
gcc -O2 -fno-if-conversion -fno-tree-vectorize branch_lab.c
# Verify assembly has jcc (conditional jump)
objdump -d branch_lab | grep -E 'j(e|ne|l|le|g|ge)'
Pitfall 2: Data Not Actually Random
Symptom: “Random” pattern shows low misprediction.
Cause: Pseudo-random generator has predictable patterns.
Solution:
// Use multiple sources of randomness
#include <time.h>
srand(time(NULL) ^ getpid());
// Or use /dev/urandom for true randomness
int fd = open("/dev/urandom", O_RDONLY);
read(fd, data, count * sizeof(int));
Pitfall 3: Cache Effects Masking Branch Effects
Symptom: Random access is slow but not due to branches.
Cause: Random data access pattern causes cache misses.
Solution: Ensure sequential memory access regardless of branch outcome:
// Good: Sequential access, only branch varies
for (i = 0; i < n; i++) {
if (data[i] < threshold) sum += data[i];
}
// Bad: Random access through pointers
for (i = 0; i < n; i++) {
if (ptrs[i]->value < threshold) sum += ptrs[i]->value;
}
Pitfall 4: Warmup Effects
Symptom: First run shows different misprediction rate.
Cause: Branch predictor tables cold on first run.
Solution: Always include warmup runs:
// Warmup - run workload but discard results
for (int warm = 0; warm < 5; warm++) {
benchmark_branchy(data, n, threshold);
}
// Measured runs
for (int run = 0; run < 10; run++) {
start_counters();
benchmark_branchy(data, n, threshold);
stop_counters();
}
Extensions and Challenges
Extension 1: Branch Predictor Capacity Test
Determine the size of the branch history table:
- Create program with N unique branches
- Increase N until misprediction rate jumps
- That’s approximately the BTB capacity
Extension 2: Indirect Branch Study
Measure the impact of indirect branches (function pointers, virtual calls):
typedef int (*op_t)(int);
op_t operations[N]; // Array of function pointers
for (int i = 0; i < n; i++) {
result = operations[i % N](data[i]); // Indirect call
}
Vary N to test indirect branch predictor capacity.
Extension 3: Speculative Execution Effects
Explore how speculative execution affects branch prediction:
- Transient execution paths
- Speculation barriers (lfence)
- Performance impact of mitigations (Spectre)
Challenge: Optimal Threshold Finding
Given unsorted data and a threshold-based filter:
- Is it faster to sort first, then filter?
- At what selectivity (% passing filter) does sorting help?
- Implement auto-tuning that chooses optimal strategy
Real-World Connections
Where Branch Prediction Matters
- Parsers: Tokenizers with many character-type checks
- Databases: Query predicate evaluation
- Compression: Huffman decoding with variable-length codes
- Networking: Packet parsing and protocol handling
Industry Techniques
- Profile-guided optimization (PGO): Compiler uses runtime data to optimize branch layout
- __builtin_expect: Hint to compiler about likely branch direction
- Branch-free data structures: B-trees designed to minimize branches
Famous Examples
- Sorting networks: Branchless sorting for small arrays
- Binary search on sorted array: Classic example of unpredictable branches
- std::partition: STL implementation uses branchless comparisons
Self-Assessment Checklist
Before considering this project complete, verify:
- You can explain why branch misprediction is expensive
- You measured ~50% misprediction for random data
- You demonstrated branchless is faster for unpredictable patterns
- You understand the CPI impact of misprediction
- You verified assembly code matches your intent
- You can explain when branchless is and isn’t appropriate
- Your measurements are consistent across runs
Resources
Essential Reading
- “Computer Architecture: A Quantitative Approach” by Hennessy & Patterson, Chapter 3
- “Performance Analysis and Tuning on Modern CPUs” by Denis Bakhvalov
- “What Every Programmer Should Know About Memory” by Drepper
Reference Documentation
- Intel 64 and IA-32 Optimization Reference Manual
- AMD64 Architecture Programmer’s Manual
- Agner Fog’s microarchitecture guides
Tools
- perf stat: Branch counter measurement
- objdump: Assembly inspection
- Intel VTune: Branch analysis
- likwid: Performance counter suite
Classic Papers
- “Two-Level Adaptive Training Branch Prediction” (Yeh & Patt)
- “Dynamic Branch Prediction with Perceptrons” (Jiménez & Lin)