Project 6: Build a Distributed Task Processing System (Capstone)
Project Overview
| Attribute | Value |
|---|---|
| Difficulty | Expert |
| Time Estimate | 1 month+ |
| Main Language | Rust |
| Alternatives | Haskell, Scala, Go |
| Prerequisites | Completed 2+ previous projects, networking basics |
| Key FP Concepts | All FP concepts combined: purity, immutability, composition, isolation of effects |
Learning Objectives
By completing this project, you will:
- Apply all FP concepts at scale - See how purity, immutability, and composition work in distributed systems
- Understand why FP suits distributed computing - Pure functions enable safe retries and parallelism
- Build idempotent operations - Critical for handling failures in distributed systems
- Design composable pipelines - Complex workflows from simple operations
- Isolate effects systematically - Network, storage, time—all pushed to edges
- Implement DAG scheduling - Declarative workflow execution
The Core Question
“Why do distributed systems like Spark, Flink, and Temporal all embrace functional programming patterns? What makes purity and immutability essential at scale?”
Distributed systems face unique challenges:
- Partial failures: Some nodes fail, others don’t
- Network unreliability: Messages get lost, duplicated, reordered
- Concurrency: Many operations happening simultaneously
- State coordination: Keeping multiple machines in sync
FP principles solve these problems elegantly:
- Pure functions: Safe to retry (same result every time)
- Immutability: Safe to parallelize (no shared mutable state)
- Composition: Complex workflows from simple operations
- Explicit effects: Side effects are visible and controlled
Deep Theoretical Foundation
1. Why Purity Enables Distribution
Consider this impure function:
// IMPURE: Side effects, non-deterministic
fn process_order(order_id: String) {
let order = database.get_order(&order_id); // Side effect: DB read
let total = calculate_total(order);
database.update_order_total(&order_id, total); // Side effect: DB write
email_service.send_receipt(&order.email, total); // Side effect: Email
println!("Processed order {}", order_id); // Side effect: I/O
}
Problems in a distributed system:
- What if it fails halfway? Did the DB update? Did the email send?
- Can we retry? We might send duplicate emails!
- Can we run it on any worker? Depends on shared state
Now consider pure:
// PURE: No side effects, deterministic
fn calculate_order_total(order: &Order) -> Money {
order.items.iter()
.map(|item| item.price * item.quantity)
.sum()
}
// PURE: Returns a description of what to do, doesn't do it
fn create_order_workflow(order: Order) -> Vec<Effect> {
vec![
Effect::UpdateDatabase(order.id, calculate_order_total(&order)),
Effect::SendEmail(order.email.clone(), receipt_template(&order)),
]
}
Now:
- Retry safe: Calculate same result every time
- Parallelizable: No shared state to corrupt
- Testable: No mocks needed, just check the output
2. Idempotency: The Key to Reliability
An operation is idempotent if doing it multiple times has the same effect as doing it once.
// NOT idempotent: balance changes each time
fn withdraw(account: &mut Account, amount: Money) {
account.balance -= amount;
}
// Idempotent: Same request ID → same result
fn withdraw_idempotent(
ledger: &mut Ledger,
request_id: RequestId,
account_id: AccountId,
amount: Money
) -> Result<(), Error> {
// Check if already processed
if ledger.has_processed(&request_id) {
return Ok(()); // Already done, return success
}
// Process withdrawal
ledger.record_withdrawal(request_id, account_id, amount)?;
Ok(())
}
Why this matters: In distributed systems, messages can be delivered multiple times (at-least-once delivery). Idempotent operations make this safe.
3. Task DAGs: Composing Workflows
Complex workflows are Directed Acyclic Graphs (DAGs) of tasks:
┌─────────┐ ┌─────────┐
│ Fetch A │────▶│Process A│──┐
└─────────┘ └─────────┘ │ ┌─────────┐
├───▶│ Combine │───▶ Result
┌─────────┐ ┌─────────┐ │ └─────────┘
│ Fetch B │────▶│Process B│──┘
└─────────┘ └─────────┘
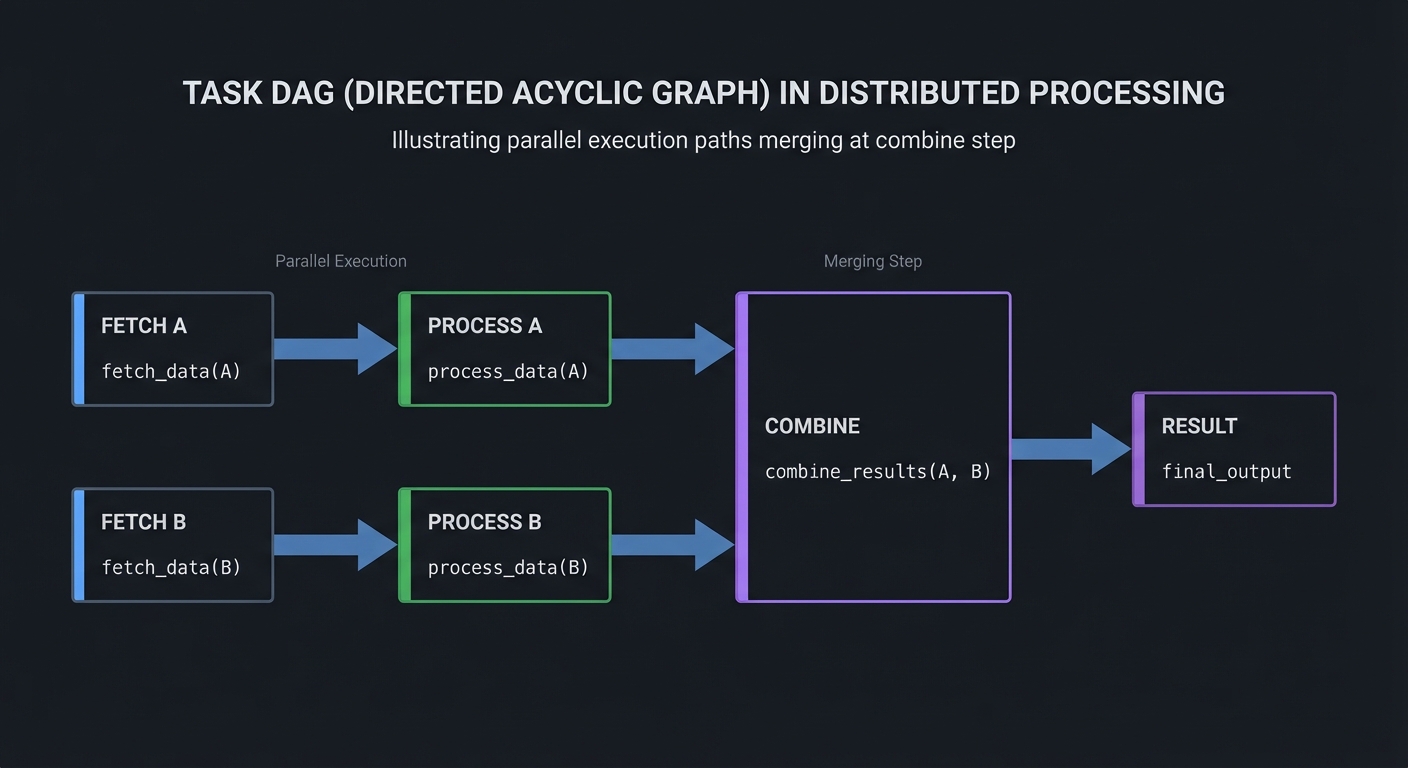
In FP terms, each task is a pure function:
// Tasks are pure functions
fn fetch_a(url: Url) -> DataA { ... }
fn fetch_b(url: Url) -> DataB { ... }
fn process_a(data: DataA) -> ProcessedA { ... }
fn process_b(data: DataB) -> ProcessedB { ... }
fn combine(a: ProcessedA, b: ProcessedB) -> Result { ... }
// Pipeline composition
let workflow = Pipeline::new()
.parallel(fetch_a, fetch_b)
.then_parallel(process_a, process_b)
.then(combine);
4. The Actor Model: Isolating State
Actors are independent units that:
- Have private state (no shared mutable state)
- Communicate via messages (immutable data)
- Process messages one at a time (no race conditions)
// Each worker is an actor
struct Worker {
id: WorkerId,
state: WorkerState, // Private, never shared
}
impl Worker {
fn handle_message(&mut self, msg: Message) -> Vec<Message> {
match msg {
Message::ExecuteTask(task) => {
let result = task.execute(); // Pure function
vec![Message::TaskComplete(task.id, result)]
}
Message::Shutdown => {
self.state = WorkerState::ShuttingDown;
vec![]
}
}
}
}
5. Serializing Pure Functions
To distribute functions, you need to serialize them. This works because pure functions are just data:
// A task is a serializable description
#[derive(Serialize, Deserialize)]
struct Task {
id: TaskId,
operation: Operation,
input: Value,
}
#[derive(Serialize, Deserialize)]
enum Operation {
Map { function_name: String },
Filter { predicate_name: String },
Reduce { reducer_name: String, initial: Value },
}
// Registry of known functions
fn get_function(name: &str) -> Box<dyn Fn(Value) -> Value> {
match name {
"parse_json" => Box::new(|v| parse_json(v)),
"to_uppercase" => Box::new(|v| to_uppercase(v)),
// ... more functions
}
}
6. Back-Pressure and Flow Control
Like lazy evaluation, distributed systems need to control the flow of data:
// Producer generates items lazily
struct Producer {
pending: VecDeque<Task>,
in_flight: HashMap<TaskId, Task>,
max_in_flight: usize,
}
impl Producer {
fn try_send(&mut self) -> Option<Task> {
// Back-pressure: don't send if too many in flight
if self.in_flight.len() >= self.max_in_flight {
return None;
}
if let Some(task) = self.pending.pop_front() {
self.in_flight.insert(task.id, task.clone());
Some(task)
} else {
None
}
}
fn handle_completion(&mut self, task_id: TaskId) {
self.in_flight.remove(&task_id);
}
}
Project Specification
What You’re Building
A distributed task processing system:
// Define a pipeline
let pipeline = Pipeline::new()
.map("parse_url", parse_url)
.filter("is_valid", |url| url.scheme() == "https")
.map("fetch", fetch_url)
.map("extract_links", extract_links)
.flatten()
.unique()
.collect();
// Submit to cluster
let job_id = client.submit(pipeline, input_data);
// Monitor progress
loop {
match client.status(job_id) {
Status::Running { progress } => println!("Progress: {}%", progress),
Status::Complete { result } => break result,
Status::Failed { error } => panic!("Job failed: {}", error),
}
}
System Architecture
┌─────────────────────────────────────────────────────────────────┐
│ CLIENT │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Pipeline Builder │ │ Job Submitter │ │
│ └─────────────────┘ └─────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│ submit(pipeline)
▼
┌─────────────────────────────────────────────────────────────────┐
│ COORDINATOR │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Job Manager │ │DAG Scheduler│ │Task Assigner│ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│ assign(task)
▼
┌─────────────────────────────────────────────────────────────────┐
│ WORKERS │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │Worker 1 │ │Worker 2 │ │Worker 3 │ │Worker 4 │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
└─────────────────────────────────────────────────────────────────┘
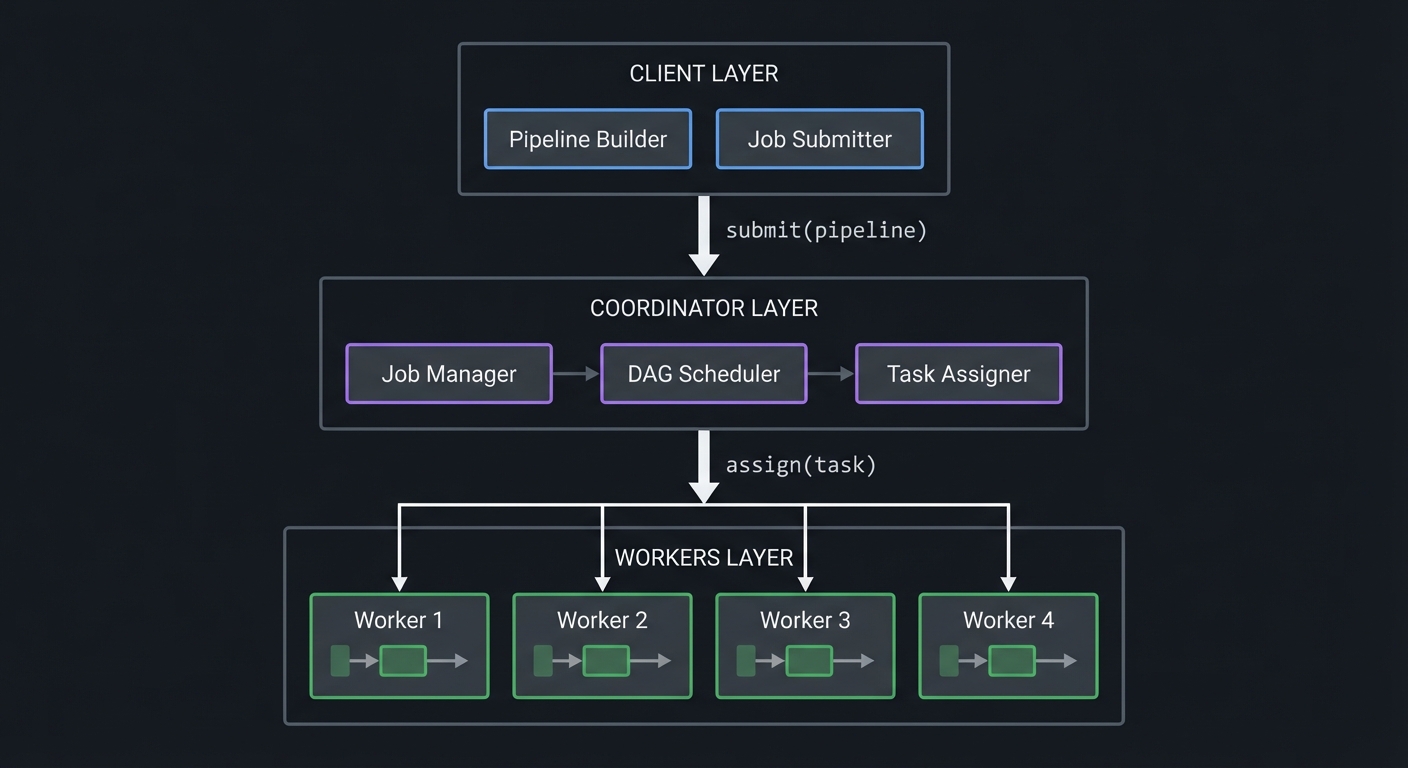
Core Components
| Component | Responsibility |
|---|---|
| Pipeline Builder | DSL for defining workflows |
| Serializer | Convert pipelines to sendable format |
| Coordinator | Manage jobs, schedule tasks |
| DAG Scheduler | Determine task execution order |
| Task Assigner | Match tasks to available workers |
| Worker | Execute tasks, report results |
| Result Collector | Aggregate results, handle failures |
Operations to Support
| Operation | Description | Type |
|---|---|---|
map(f) |
Apply f to each item | 1 → 1 |
filter(pred) |
Keep items where pred is true | 1 → 0 or 1 |
flatMap(f) |
Map then flatten | 1 → N |
reduce(init, f) |
Combine all items | N → 1 |
groupBy(key) |
Group by key function | N → Map<K, N> |
join(other) |
Combine with another dataset | N, M → N×M |
unique() |
Remove duplicates | N → ≤N |
sort() |
Order items | N → N |
take(n) |
First n items | N → min(n, N) |
Solution Architecture
Data Types
// Task identity
#[derive(Clone, Hash, Eq, PartialEq, Serialize, Deserialize)]
struct TaskId(Uuid);
#[derive(Clone, Hash, Eq, PartialEq, Serialize, Deserialize)]
struct JobId(Uuid);
// Task definition
#[derive(Clone, Serialize, Deserialize)]
struct Task {
id: TaskId,
job_id: JobId,
operation: Operation,
dependencies: Vec<TaskId>,
input: Option<Value>, // Direct input or from dependencies
attempt: u32,
max_attempts: u32,
}
// Supported operations
#[derive(Clone, Serialize, Deserialize)]
enum Operation {
Source { data: Vec<Value> },
Map { function: FunctionRef },
Filter { predicate: FunctionRef },
FlatMap { function: FunctionRef },
Reduce { initial: Value, reducer: FunctionRef },
GroupBy { key_fn: FunctionRef },
Join { other_task: TaskId },
Unique,
Sort { comparator: Option<FunctionRef> },
Take { n: usize },
Collect,
}
// Reference to a registered function
#[derive(Clone, Serialize, Deserialize)]
struct FunctionRef {
name: String,
// Could include serialized closure for more flexibility
}
// Task result
#[derive(Clone, Serialize, Deserialize)]
enum TaskResult {
Success { output: Value },
Failure { error: String, retriable: bool },
}
// Worker state
struct WorkerState {
id: WorkerId,
current_task: Option<TaskId>,
last_heartbeat: Instant,
capabilities: WorkerCapabilities,
}
Pipeline Builder DSL
struct Pipeline {
tasks: Vec<Task>,
last_task: Option<TaskId>,
}
impl Pipeline {
fn new() -> Self {
Pipeline { tasks: vec![], last_task: None }
}
fn source(mut self, data: Vec<Value>) -> Self {
let task = Task::new(Operation::Source { data });
self.last_task = Some(task.id.clone());
self.tasks.push(task);
self
}
fn map(mut self, name: &str, _f: fn(Value) -> Value) -> Self {
let deps = self.last_task.iter().cloned().collect();
let task = Task::new_with_deps(
Operation::Map { function: FunctionRef::new(name) },
deps
);
self.last_task = Some(task.id.clone());
self.tasks.push(task);
self
}
fn filter(mut self, name: &str, _pred: fn(&Value) -> bool) -> Self {
let deps = self.last_task.iter().cloned().collect();
let task = Task::new_with_deps(
Operation::Filter { predicate: FunctionRef::new(name) },
deps
);
self.last_task = Some(task.id.clone());
self.tasks.push(task);
self
}
// ... more operations
fn parallel<F1, F2>(self, p1: F1, p2: F2) -> ParallelPipeline
where
F1: FnOnce(Pipeline) -> Pipeline,
F2: FnOnce(Pipeline) -> Pipeline,
{
let left = p1(Pipeline::new());
let right = p2(Pipeline::new());
ParallelPipeline::new(left, right)
}
}
Coordinator
struct Coordinator {
jobs: HashMap<JobId, Job>,
pending_tasks: VecDeque<TaskId>,
running_tasks: HashMap<TaskId, WorkerId>,
completed_tasks: HashMap<TaskId, TaskResult>,
workers: HashMap<WorkerId, WorkerState>,
}
impl Coordinator {
fn submit_job(&mut self, pipeline: Pipeline) -> JobId {
let job_id = JobId::new();
let tasks = pipeline.build(job_id.clone());
// Topological sort to determine execution order
let order = topological_sort(&tasks);
// Queue tasks that have no dependencies
for task_id in order {
let task = tasks.get(&task_id).unwrap();
if task.dependencies.is_empty() {
self.pending_tasks.push_back(task_id);
}
}
self.jobs.insert(job_id.clone(), Job::new(tasks));
job_id
}
fn assign_task(&mut self, worker_id: WorkerId) -> Option<Task> {
// Find a pending task
let task_id = self.pending_tasks.pop_front()?;
let job = self.jobs.values()
.find(|j| j.tasks.contains_key(&task_id))?;
let task = job.tasks.get(&task_id)?.clone();
// Mark as running
self.running_tasks.insert(task_id, worker_id);
Some(task)
}
fn handle_task_complete(&mut self, task_id: TaskId, result: TaskResult) {
// Remove from running
self.running_tasks.remove(&task_id);
// Store result
self.completed_tasks.insert(task_id.clone(), result.clone());
if let TaskResult::Success { .. } = result {
// Check if any tasks are now unblocked
for job in self.jobs.values() {
for (id, task) in &job.tasks {
if task.dependencies.contains(&task_id) {
let all_deps_done = task.dependencies.iter()
.all(|d| self.completed_tasks.contains_key(d));
if all_deps_done {
self.pending_tasks.push_back(id.clone());
}
}
}
}
}
}
fn handle_task_failure(&mut self, task_id: TaskId, error: String) {
// Get the task
let task = self.find_task(&task_id);
if task.attempt < task.max_attempts {
// Retry
let mut retry_task = task.clone();
retry_task.attempt += 1;
self.pending_tasks.push_back(task_id);
} else {
// Mark job as failed
self.fail_job(task.job_id.clone(), error);
}
}
}
Worker
struct Worker {
id: WorkerId,
coordinator_addr: SocketAddr,
function_registry: FunctionRegistry,
}
impl Worker {
async fn run(&self) {
loop {
// Request task from coordinator
let task = self.request_task().await;
if let Some(task) = task {
let result = self.execute_task(&task);
self.report_result(task.id, result).await;
} else {
// No tasks available, wait
tokio::time::sleep(Duration::from_millis(100)).await;
}
}
}
fn execute_task(&self, task: &Task) -> TaskResult {
// Get input data
let input = match &task.input {
Some(v) => v.clone(),
None => return TaskResult::Failure {
error: "No input provided".to_string(),
retriable: false,
},
};
// Execute operation
let result = match &task.operation {
Operation::Map { function } => {
let f = self.function_registry.get(&function.name)?;
match input {
Value::Array(items) => {
Value::Array(items.into_iter().map(f).collect())
}
item => f(item),
}
}
Operation::Filter { predicate } => {
let p = self.function_registry.get_predicate(&predicate.name)?;
match input {
Value::Array(items) => {
Value::Array(items.into_iter().filter(p).collect())
}
item => if p(&item) { item } else { Value::Null },
}
}
Operation::Reduce { initial, reducer } => {
let r = self.function_registry.get_reducer(&reducer.name)?;
match input {
Value::Array(items) => {
items.into_iter().fold(initial.clone(), r)
}
_ => return TaskResult::Failure {
error: "Reduce requires array input".to_string(),
retriable: false,
},
}
}
// ... other operations
};
TaskResult::Success { output: result }
}
}
Function Registry
struct FunctionRegistry {
mappers: HashMap<String, Box<dyn Fn(Value) -> Value + Send + Sync>>,
predicates: HashMap<String, Box<dyn Fn(&Value) -> bool + Send + Sync>>,
reducers: HashMap<String, Box<dyn Fn(Value, Value) -> Value + Send + Sync>>,
}
impl FunctionRegistry {
fn new() -> Self {
let mut registry = FunctionRegistry::default();
// Register built-in functions
registry.register_mapper("to_uppercase", |v| {
match v {
Value::String(s) => Value::String(s.to_uppercase()),
other => other,
}
});
registry.register_mapper("parse_int", |v| {
match v {
Value::String(s) => s.parse::<i64>()
.map(Value::from)
.unwrap_or(Value::Null),
other => other,
}
});
registry.register_predicate("is_positive", |v| {
match v {
Value::Number(n) => n.as_f64().map(|f| f > 0.0).unwrap_or(false),
_ => false,
}
});
registry.register_reducer("sum", |acc, item| {
let a = acc.as_f64().unwrap_or(0.0);
let b = item.as_f64().unwrap_or(0.0);
Value::from(a + b)
});
registry
}
}
Implementation Guide
Phase 1: Local Pipeline (Week 1)
Goal: Build the pipeline DSL that works locally.
// Work locally first, no networking
fn main() {
let data = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let result = Pipeline::new()
.source(data)
.map("double", |x| x * 2)
.filter("is_even", |x| x % 2 == 0)
.reduce(0, "sum", |acc, x| acc + x)
.execute();
println!("Result: {:?}", result); // 90
}
Phase 2: Task Serialization (Week 1-2)
Goal: Make pipelines serializable.
// Serialize pipeline to send over network
let pipeline = Pipeline::new()
.source(data)
.map("parse_json", parse_json);
let serialized = serde_json::to_string(&pipeline.to_tasks())?;
let deserialized: Vec<Task> = serde_json::from_str(&serialized)?;
Phase 3: Single Worker (Week 2)
Goal: Execute tasks from a queue.
// Simple task queue
struct TaskQueue {
tasks: VecDeque<Task>,
}
impl TaskQueue {
fn submit(&mut self, task: Task) {
self.tasks.push_back(task);
}
fn next(&mut self) -> Option<Task> {
self.tasks.pop_front()
}
}
// Worker loop
fn worker_loop(queue: &mut TaskQueue, registry: &FunctionRegistry) {
while let Some(task) = queue.next() {
let result = execute_task(&task, registry);
println!("Task {} completed: {:?}", task.id, result);
}
}
Phase 4: DAG Scheduler (Week 2-3)
Goal: Handle task dependencies correctly.
fn topological_sort(tasks: &HashMap<TaskId, Task>) -> Vec<TaskId> {
let mut result = Vec::new();
let mut visited = HashSet::new();
let mut visiting = HashSet::new();
fn visit(
task_id: &TaskId,
tasks: &HashMap<TaskId, Task>,
visited: &mut HashSet<TaskId>,
visiting: &mut HashSet<TaskId>,
result: &mut Vec<TaskId>,
) -> Result<(), String> {
if visited.contains(task_id) {
return Ok(());
}
if visiting.contains(task_id) {
return Err("Cycle detected".to_string());
}
visiting.insert(task_id.clone());
if let Some(task) = tasks.get(task_id) {
for dep in &task.dependencies {
visit(dep, tasks, visited, visiting, result)?;
}
}
visiting.remove(task_id);
visited.insert(task_id.clone());
result.push(task_id.clone());
Ok(())
}
for task_id in tasks.keys() {
visit(task_id, tasks, &mut visited, &mut visiting, &mut result).unwrap();
}
result
}
Phase 5: Network Communication (Week 3)
Goal: Coordinator and workers communicate over network.
// Use tokio for async networking
use tokio::net::{TcpListener, TcpStream};
use tokio::io::{AsyncReadExt, AsyncWriteExt};
// Message protocol
#[derive(Serialize, Deserialize)]
enum Message {
RequestTask { worker_id: WorkerId },
AssignTask { task: Task },
TaskComplete { task_id: TaskId, result: TaskResult },
Heartbeat { worker_id: WorkerId },
NoTasksAvailable,
}
// Coordinator server
async fn coordinator_server(coordinator: Arc<Mutex<Coordinator>>) {
let listener = TcpListener::bind("0.0.0.0:8080").await?;
loop {
let (socket, _) = listener.accept().await?;
let coordinator = coordinator.clone();
tokio::spawn(async move {
handle_connection(socket, coordinator).await;
});
}
}
// Worker client
async fn worker_client(worker: &Worker) {
loop {
let mut stream = TcpStream::connect(&worker.coordinator_addr).await?;
// Request task
let msg = Message::RequestTask { worker_id: worker.id.clone() };
send_message(&mut stream, &msg).await?;
// Receive task
let response: Message = receive_message(&mut stream).await?;
match response {
Message::AssignTask { task } => {
let result = worker.execute_task(&task);
// Report result
let msg = Message::TaskComplete { task_id: task.id, result };
send_message(&mut stream, &msg).await?;
}
Message::NoTasksAvailable => {
tokio::time::sleep(Duration::from_millis(100)).await;
}
_ => {}
}
}
}
Phase 6: Failure Handling (Week 3-4)
Goal: Handle worker failures, task retries.
impl Coordinator {
fn check_timeouts(&mut self) {
let now = Instant::now();
let timeout = Duration::from_secs(30);
// Check for timed-out workers
let dead_workers: Vec<WorkerId> = self.workers.iter()
.filter(|(_, state)| now - state.last_heartbeat > timeout)
.map(|(id, _)| id.clone())
.collect();
for worker_id in dead_workers {
// Re-queue tasks from dead worker
let tasks_to_requeue: Vec<TaskId> = self.running_tasks.iter()
.filter(|(_, w)| *w == &worker_id)
.map(|(t, _)| t.clone())
.collect();
for task_id in tasks_to_requeue {
self.running_tasks.remove(&task_id);
self.pending_tasks.push_front(task_id);
}
self.workers.remove(&worker_id);
}
}
fn retry_task(&mut self, task: &Task) {
if task.attempt < task.max_attempts {
let mut retry = task.clone();
retry.attempt += 1;
self.pending_tasks.push_back(retry.id.clone());
} else {
self.fail_job(task.job_id.clone(), "Max retries exceeded".to_string());
}
}
}
Phase 7: Result Collection (Week 4)
Goal: Aggregate results from all tasks.
impl Coordinator {
fn collect_results(&self, job_id: &JobId) -> Option<Value> {
let job = self.jobs.get(job_id)?;
// Find the final task (no other task depends on it)
let final_task_id = job.tasks.iter()
.find(|(id, _)| !job.tasks.values().any(|t| t.dependencies.contains(id)))
.map(|(id, _)| id)?;
// Get its result
self.completed_tasks.get(final_task_id)
.and_then(|r| match r {
TaskResult::Success { output } => Some(output.clone()),
_ => None,
})
}
}
Phase 8: Back-Pressure (Week 4)
Goal: Don’t overwhelm workers.
impl Coordinator {
fn should_accept_task(&self, worker_id: &WorkerId) -> bool {
let worker = self.workers.get(worker_id)?;
// Check worker capacity
let current_load = self.running_tasks.values()
.filter(|w| *w == worker_id)
.count();
current_load < worker.capabilities.max_concurrent_tasks
}
fn assign_with_backpressure(&mut self, worker_id: WorkerId) -> Option<Task> {
if !self.should_accept_task(&worker_id) {
return None;
}
self.assign_task(worker_id)
}
}
Testing Strategy
Unit Tests
#[cfg(test)]
mod tests {
#[test]
fn test_pipeline_map() {
let result = Pipeline::new()
.source(vec![1, 2, 3])
.map("double", |x| x * 2)
.execute_local();
assert_eq!(result, vec![2, 4, 6]);
}
#[test]
fn test_pipeline_filter() {
let result = Pipeline::new()
.source(vec![1, 2, 3, 4, 5])
.filter("is_even", |x| x % 2 == 0)
.execute_local();
assert_eq!(result, vec![2, 4]);
}
#[test]
fn test_topological_sort() {
// A -> B -> C
let mut tasks = HashMap::new();
tasks.insert(TaskId("A"), Task { dependencies: vec![], .. });
tasks.insert(TaskId("B"), Task { dependencies: vec![TaskId("A")], .. });
tasks.insert(TaskId("C"), Task { dependencies: vec![TaskId("B")], .. });
let order = topological_sort(&tasks);
assert_eq!(order, vec![TaskId("A"), TaskId("B"), TaskId("C")]);
}
#[test]
fn test_idempotent_task_execution() {
let task = Task::new(Operation::Map { function: FunctionRef::new("double") });
let result1 = execute_task(&task, &input);
let result2 = execute_task(&task, &input);
assert_eq!(result1, result2); // Same input → same output
}
}
Integration Tests
#[tokio::test]
async fn test_distributed_execution() {
// Start coordinator
let coordinator = spawn_coordinator();
// Start workers
let workers = vec![
spawn_worker("worker1"),
spawn_worker("worker2"),
];
// Submit job
let client = Client::connect(coordinator.address());
let job_id = client.submit(
Pipeline::new()
.source(vec![1, 2, 3, 4, 5])
.map("double", |x| x * 2)
).await?;
// Wait for completion
let result = client.wait_for(job_id).await?;
assert_eq!(result, vec![2, 4, 6, 8, 10]);
}
#[tokio::test]
async fn test_worker_failure_recovery() {
let coordinator = spawn_coordinator();
let worker1 = spawn_worker("worker1");
// Submit long-running job
let job_id = client.submit(long_pipeline).await?;
// Kill worker mid-execution
worker1.kill();
// Start replacement worker
let worker2 = spawn_worker("worker2");
// Job should still complete
let result = client.wait_for(job_id).await?;
assert!(result.is_ok());
}
Chaos Tests
#[tokio::test]
async fn test_network_partition() {
// Simulate network issues
let network = SimulatedNetwork::new();
network.set_latency(Duration::from_millis(100));
network.set_packet_loss(0.1);
let coordinator = spawn_coordinator_with_network(&network);
let workers = spawn_workers_with_network(&network, 3);
let result = client.submit_and_wait(pipeline).await;
// Should eventually succeed despite network issues
assert!(result.is_ok());
}
Common Pitfalls and Debugging
Pitfall 1: Non-Deterministic Functions
Symptom: Different results on retries
// WRONG: Uses current time
fn tag_with_timestamp(item: Value) -> Value {
json!({
"data": item,
"timestamp": SystemTime::now() // Non-deterministic!
})
}
// RIGHT: Timestamp provided externally
fn tag_with_timestamp(item: Value, timestamp: DateTime) -> Value {
json!({
"data": item,
"timestamp": timestamp // Deterministic
})
}
Pitfall 2: Stateful Functions
Symptom: Different workers produce different results
// WRONG: Maintains state across calls
static mut COUNTER: i32 = 0;
fn increment_and_tag(item: Value) -> Value {
unsafe { COUNTER += 1; }
json!({ "id": COUNTER, "data": item }) // State leaks!
}
// RIGHT: Pure function
fn tag_with_hash(item: Value) -> Value {
let id = hash(&item); // Deterministic
json!({ "id": id, "data": item })
}
Pitfall 3: Missing Idempotency Keys
Symptom: Duplicate operations on retry
// WRONG: No idempotency
fn process_payment(amount: Money) {
charge_credit_card(amount); // Might charge twice!
}
// RIGHT: With idempotency key
fn process_payment(request_id: RequestId, amount: Money) {
if already_processed(&request_id) {
return; // Already done
}
charge_credit_card(amount);
mark_processed(request_id);
}
Pitfall 4: Deadlock in DAG
Symptom: Tasks never complete
// Check for cycles before scheduling
fn validate_dag(tasks: &HashMap<TaskId, Task>) -> Result<(), String> {
// Use cycle detection in topological sort
topological_sort(tasks).map(|_| ())
}
Extensions and Challenges
Challenge 1: Data Locality
Schedule tasks where their data already resides:
impl Coordinator {
fn assign_with_locality(&mut self, worker_id: WorkerId) -> Option<Task> {
// Prefer tasks whose input data is on this worker
let worker = self.workers.get(&worker_id)?;
let local_task = self.pending_tasks.iter()
.find(|t| {
self.data_locations.get(&t.input_id)
.map(|loc| loc == &worker_id)
.unwrap_or(false)
});
if let Some(task_id) = local_task {
self.pending_tasks.retain(|t| t != task_id);
// ... assign task
} else {
self.assign_task(worker_id) // Fall back to any task
}
}
}
Challenge 2: Checkpointing
Save progress for long-running jobs:
impl Coordinator {
fn checkpoint(&self, job_id: &JobId) -> Checkpoint {
Checkpoint {
job_id: job_id.clone(),
completed_tasks: self.completed_tasks.clone(),
timestamp: SystemTime::now(),
}
}
fn restore_from_checkpoint(&mut self, checkpoint: Checkpoint) {
for (task_id, result) in checkpoint.completed_tasks {
self.completed_tasks.insert(task_id, result);
}
// Re-queue tasks that weren't completed
// ...
}
}
Challenge 3: Speculative Execution
Run slow tasks on multiple workers:
impl Coordinator {
fn check_for_slow_tasks(&mut self) {
let now = Instant::now();
let threshold = Duration::from_secs(60);
for (task_id, start_time) in &self.task_start_times {
if now - *start_time > threshold {
// Start speculative copy
if let Some(task) = self.find_task(task_id) {
self.pending_tasks.push_back(task.id.clone());
}
}
}
}
}
Challenge 4: Web UI
Build a dashboard showing job progress:
// REST API for UI
#[get("/jobs")]
async fn list_jobs(coordinator: &State<Coordinator>) -> Json<Vec<JobStatus>> {
let jobs = coordinator.lock().unwrap()
.jobs.values()
.map(|j| JobStatus {
id: j.id.clone(),
status: j.status(),
progress: j.progress(),
tasks_complete: j.completed_count(),
tasks_total: j.total_count(),
})
.collect();
Json(jobs)
}
Real-World Connections
Similar Systems
| System | Language | Key Innovation |
|---|---|---|
| Apache Spark | Scala | RDDs (Resilient Distributed Datasets) |
| Apache Flink | Java | Stream processing with exactly-once |
| Dask | Python | Pythonic parallel computing |
| Ray | Python | Distributed actors and tasks |
| Temporal | Go | Durable execution workflows |
| Cadence | Go | Workflow orchestration |
FP in Production Distributed Systems
- Spark’s RDD API: Pure transformations on immutable datasets
- Kafka Streams: Stateless stream transformations
- Event Sourcing: Append-only events, derived state
- Idempotent APIs: Retry-safe operations
Resources
Essential Reading
| Topic | Resource |
|---|---|
| Distributed systems | Designing Data-Intensive Applications Ch. 8-9 |
| Idempotency | Release It! 2nd Ed. Ch. 5 |
| Actors | Programming Rust 2nd Ed. Ch. 19 |
| Workflows | Building Microservices 2nd Ed. Ch. 6 |
Papers
- “MapReduce: Simplified Data Processing on Large Clusters” (Google)
- “Resilient Distributed Datasets” (Spark paper)
- “Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks” (Microsoft)
Self-Assessment Checklist
Core Pipeline
- Pipeline DSL works locally
- Operations: map, filter, flatMap, reduce
- Tasks are serializable
Distribution
- Coordinator manages job lifecycle
- Workers execute tasks and report results
- Network communication works
Reliability
- Task retries on failure
- Worker failure detection
- DAG scheduling respects dependencies
- Idempotent operations
Performance
- Back-pressure limits task queuing
- Parallelism across workers
- Progress tracking
Interview Questions
- “Why does FP suit distributed computing?”
- Expected: Pure functions are safe to retry and parallelize
- “What is idempotency and why does it matter?”
- Expected: Same operation multiple times = same result; essential for retries
- “How do you handle partial failures?”
- Expected: Retry with idempotency, checkpoint progress, dead letter queues
- “What’s the difference between at-least-once and exactly-once delivery?”
- Expected: At-least-once may duplicate; exactly-once needs idempotency or transactions
- “How would you scale this system to 1000 workers?”
- Expected: Partition coordinator, data locality, hierarchical scheduling
- “How do you ensure tasks complete in the right order?”
- Expected: DAG representation, topological sort, dependency tracking