Functional Programming & Lambda Calculus with Haskell
A Project-Based Deep Dive into the Foundations of Computation
Goal
Build a precise mental model of computation by implementing lambda calculus in Haskell, then grow that model into a full functional toolkit: typed abstractions, evaluation strategies, and practical encodings you can apply to real-world program design.
Overview
Lambda calculus is not just a programming technique—it’s the mathematical theory of computation itself. Created by Alonzo Church in the 1930s, it predates computers and proved that functions alone are sufficient to express any computation.
Haskell is the purest practical embodiment of these ideas. Unlike languages that bolt on functional features, Haskell is lambda calculus extended with a type system, lazy evaluation, and syntactic sugar.
Why This Matters
Understanding lambda calculus and functional programming transforms how you think about code:
- From “how” to “what”: Describe the result, not the steps
- From mutation to transformation: Data flows through functions
- From side effects to purity: Functions are predictable, testable, composable
- From runtime errors to compile-time proofs: The type system catches errors before execution
Core Concepts You’ll Master
| Concept Area | What You’ll Understand |
|---|---|
| Lambda Calculus | Variables, abstraction, application, reduction, Church encodings, fixed points |
| Type Systems | Hindley-Milner inference, algebraic data types, parametric polymorphism |
| Higher-Order Functions | Functions as values, currying, composition, point-free style |
| Laziness | Thunks, infinite data structures, call-by-need evaluation |
| Type Classes | Ad-hoc polymorphism, Functor, Applicative, Monad, and beyond |
| Category Theory | Functors, natural transformations, monads as mathematical objects |
| Effects | IO, State, Reader, Writer, monad transformers |
| Advanced Types | GADTs, type families, dependent types (via singletons) |
Concept Summary Table
| Concept Cluster | What You Need to Internalize |
|---|---|
| Lambda calculus syntax | Variables, abstraction, application, alpha-equivalence, substitution. |
| Evaluation strategies | Normal order vs applicative order, confluence, termination tradeoffs. |
| Encodings as data | Booleans, numerals, pairs, lists as pure functions. |
| Fixed points & recursion | Y combinator, recursion without names, self-application. |
| Types and inference | Hindley-Milner inference, polymorphism, ADTs. |
| Laziness | Thunks, sharing, infinite structures, call-by-need semantics. |
| Type classes | Functor/Applicative/Monad as compositional interfaces. |
| Effects modeling | IO and state as explicit, composable effects. |
Deep Dive Reading by Concept
Lambda Calculus Core
| Concept | Book & Chapter |
|---|---|
| Syntax, substitution, alpha/beta | Types and Programming Languages by Benjamin Pierce — Ch. 5: “The Untyped Lambda-Calculus” |
| Church encodings | Introduction to Functional Programming by Richard Bird — Ch. 2: “Equational Reasoning” |
Evaluation & Semantics
| Concept | Book & Chapter |
|---|---|
| Normal order vs applicative order | Programming in Haskell, 2nd Edition by Graham Hutton — Ch. 15: “Lazy Evaluation” |
| Confluence and normal forms | The Lambda Calculus: Its Syntax and Semantics by Henk Barendregt — Ch. 6: “Reduction” |
Types & Abstractions
| Concept | Book & Chapter |
|---|---|
| Hindley-Milner inference | Types and Programming Languages — Ch. 22: “Type Reconstruction” |
| Type classes | Haskell Programming from First Principles — Ch. 16: “Functor”, Ch. 17: “Applicative”, Ch. 18: “Monad” |
Effects in Haskell
| Concept | Book & Chapter |
|---|---|
| IO and purity boundary | Real World Haskell — Ch. 8: “IO” |
| Monads as effect modeling | Learn You a Haskell for Great Good! — Ch. 12: “A Fistful of Monads” |
Project 1: Pure Lambda Calculus Interpreter
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: OCaml, Racket, Rust
- Coolness Level: Level 5: Pure Magic (Super Cool)
- Business Potential: 1. The “Resume Gold” (Educational/Personal Brand)
- Difficulty: Level 3: Advanced
- Knowledge Area: Programming Language Theory / Lambda Calculus
- Software or Tool: Lambda Interpreter
- Main Book: “Haskell Programming from First Principles” by Christopher Allen and Julie Moronuki
What you’ll build
An interpreter for the untyped lambda calculus that parses lambda expressions, performs alpha-renaming, and reduces to normal form using different evaluation strategies (normal order, applicative order).
Why it teaches Lambda Calculus
Lambda calculus has only three constructs: variables (x), abstraction (λx.e), and application (e₁ e₂). By implementing an interpreter, you’ll see that these three things are sufficient to express any computation—numbers, booleans, loops, recursion—everything emerges from function application.
Core challenges you’ll face
- Parsing lambda syntax (handling nested abstractions and applications) → maps to syntax of lambda calculus
- Free vs bound variables (tracking variable scope) → maps to variable binding
- Alpha-renaming (avoiding variable capture) → maps to substitution correctness
- Beta-reduction (applying functions to arguments) → maps to computation itself
- Reduction strategies (which redex to reduce first) → maps to evaluation order
Key Concepts
- Lambda Calculus Syntax: A Tutorial Introduction to the Lambda Calculus (PDF) - Raúl Rojas
- Reduction Strategies: “Types and Programming Languages” Chapter 5 - Benjamin Pierce
- Substitution: Stanford CS 242: Lambda Calculus
- Parsing in Haskell: “Programming in Haskell” Chapter 13 - Graham Hutton
Difficulty
Advanced
Time estimate
2-3 weeks
Prerequisites
Basic Haskell syntax, understanding of recursion
Real world outcome
λ> (\x. \y. x) a b
Parsing: App (App (Lam "x" (Lam "y" (Var "x"))) (Var "a")) (Var "b")
Reduction trace (normal order):
(λx. λy. x) a b
→ (λy. a) b -- β-reduce: x := a
→ a -- β-reduce: y := b (y not used)
Normal form: a
λ> (\x. x x) (\x. x x)
WARNING: No normal form (diverges)
(λx. x x) (λx. x x)
→ (λx. x x) (λx. x x)
→ (λx. x x) (λx. x x)
→ ... (infinite loop)
λ> (\f. \x. f (f x)) (\y. y) z
Reduction trace:
(λf. λx. f (f x)) (λy. y) z
→ (λx. (λy. y) ((λy. y) x)) z
→ (λy. y) ((λy. y) z)
→ (λy. y) z
→ z
Normal form: z
Implementation Hints
Start with the data type for lambda terms:
Pseudo-Haskell:
data Term
= Var String -- Variable: x
| Lam String Term -- Abstraction: λx. e
| App Term Term -- Application: e₁ e₂
-- Free variables in a term
freeVars :: Term -> Set String
freeVars (Var x) = singleton x
freeVars (Lam x e) = delete x (freeVars e)
freeVars (App e1 e2) = union (freeVars e1) (freeVars e2)
-- Substitution: e[x := s] (replace x with s in e)
subst :: String -> Term -> Term -> Term
subst x s (Var y)
| x == y = s
| otherwise = Var y
subst x s (App e1 e2) = App (subst x s e1) (subst x s e2)
subst x s (Lam y e)
| x == y = Lam y e -- x is bound, no substitution
| y `notIn` freeVars s = Lam y (subst x s e) -- safe to substitute
| otherwise = -- need alpha-rename y first!
let y' = freshVar y (freeVars s `union` freeVars e)
in Lam y' (subst x s (subst y (Var y') e))
-- Beta reduction: (λx. e) s → e[x := s]
betaReduce :: Term -> Maybe Term
betaReduce (App (Lam x e) s) = Just (subst x s e)
betaReduce _ = Nothing
-- Normal order reduction (reduce leftmost-outermost redex first)
normalOrder :: Term -> Term
normalOrder term = case betaReduce term of
Just reduced -> normalOrder reduced
Nothing -> case term of
App e1 e2 -> let e1' = normalOrder e1
in if e1' /= e1 then App e1' e2
else App e1 (normalOrder e2)
Lam x e -> Lam x (normalOrder e)
_ -> term
Learning milestones
- Parser handles nested abstractions → You understand lambda syntax
- Substitution avoids capture → You understand variable binding
- Beta reduction works → You understand computation
- Different strategies give same normal forms → You understand Church-Rosser theorem
Project 2: Church Encodings - Numbers, Booleans, and Data from Nothing
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: Racket, OCaml, JavaScript (for comparison)
- Coolness Level: Level 5: Pure Magic (Super Cool)
- Business Potential: 1. The “Resume Gold” (Educational/Personal Brand)
- Difficulty: Level 3: Advanced
- Knowledge Area: Lambda Calculus / Church Encodings
- Software or Tool: Church Encoding Library
- Main Book: “Learn You a Haskell for Great Good!” by Miran Lipovača
What you’ll build
Implement Church numerals, Church booleans, Church pairs, and Church lists—representing data entirely as functions. Then build arithmetic (addition, multiplication, exponentiation), conditionals, and recursion using only lambda abstractions.
Why it teaches Lambda Calculus
This is the “magic trick” of lambda calculus: data is just patterns of function application. The number 3 is “apply a function 3 times.” True is “select the first of two options.” A pair is “given a selector, apply it to two values.” Once you see this, you understand that functions are sufficient for everything.
Core challenges you’ll face
- Church numerals (representing N as λf.λx. f(f(…f(x)))) → maps to data as functions
- Church booleans (True = λt.λf. t, False = λt.λf. f) → maps to control flow as selection
- Predecessor function (Kleene’s trick—famously difficult!) → maps to encoding complexity
- Church pairs and lists → maps to data structures as functions
- Y combinator for recursion → maps to fixed points
Key Concepts
- Church Encodings: Learn X in Y Minutes - Lambda Calculus
- Church Numerals: “Types and Programming Languages” Chapter 5 - Benjamin Pierce
- Y Combinator: Programming with Lambda Calculus
Difficulty
Advanced
Time estimate
1-2 weeks
Prerequisites
Project 1 (Lambda interpreter)
Real world outcome
-- In your Haskell library:
λ> let three = church 3
λ> let five = church 5
λ> unchurch (add three five)
8
λ> unchurch (mult three five)
15
λ> unchurch (power (church 2) (church 10))
1024
λ> unchurch (pred (church 7))
6
λ> let myList = cons (church 1) (cons (church 2) (cons (church 3) nil))
λ> unchurch (head myList)
1
λ> unchurch (head (tail myList))
2
λ> unchurch (factorial (church 5)) -- Using Y combinator!
120
Implementation Hints
Church numerals represent N as “apply f, N times, to x”:
Pseudo-Haskell (using Rank2Types for proper typing):
-- Church numeral: applies f to x, n times
-- zero = λf. λx. x
-- one = λf. λx. f x
-- two = λf. λx. f (f x)
-- three = λf. λx. f (f (f x))
type Church = forall a. (a -> a) -> a -> a
zero :: Church
zero = \f x -> x
succ' :: Church -> Church
succ' n = \f x -> f (n f x)
-- Convert Int to Church
church :: Int -> Church
church 0 = zero
church n = succ' (church (n - 1))
-- Convert Church to Int
unchurch :: Church -> Int
unchurch n = n (+1) 0
-- Addition: m + n = apply f, m+n times
add :: Church -> Church -> Church
add m n = \f x -> m f (n f x)
-- Multiplication: m * n = apply (apply f n times), m times
mult :: Church -> Church -> Church
mult m n = \f -> m (n f)
-- Power: m^n = apply multiplication by m, n times
power :: Church -> Church -> Church
power m n = n m
-- The predecessor is HARD! (Kleene's trick)
-- Idea: pair up (prev, current), iterate, extract prev
pred' :: Church -> Church
pred' n = \f x ->
-- Build (0, 0), then (0, f(0)), then (f(0), f(f(0))), ...
-- After n steps: (f^(n-1)(x), f^n(x))
fst' (n (\p -> pair (snd' p) (f (snd' p))) (pair x x))
-- Church booleans
type ChurchBool = forall a. a -> a -> a
true :: ChurchBool
true = \t f -> t
false :: ChurchBool
false = \t f -> f
if' :: ChurchBool -> a -> a -> a
if' b t f = b t f
-- Church pairs
pair :: a -> b -> ((a -> b -> c) -> c)
pair x y = \f -> f x y
fst' :: ((a -> b -> a) -> a) -> a
fst' p = p (\x y -> x)
snd' :: ((a -> b -> b) -> b) -> b
snd' p = p (\x y -> y)
Learning milestones
- Arithmetic works on Church numerals → You understand encoding
- Predecessor works → You understand Kleene’s insight
- Church lists work → You understand data structures as functions
- Factorial using Y combinator → You understand recursion without names
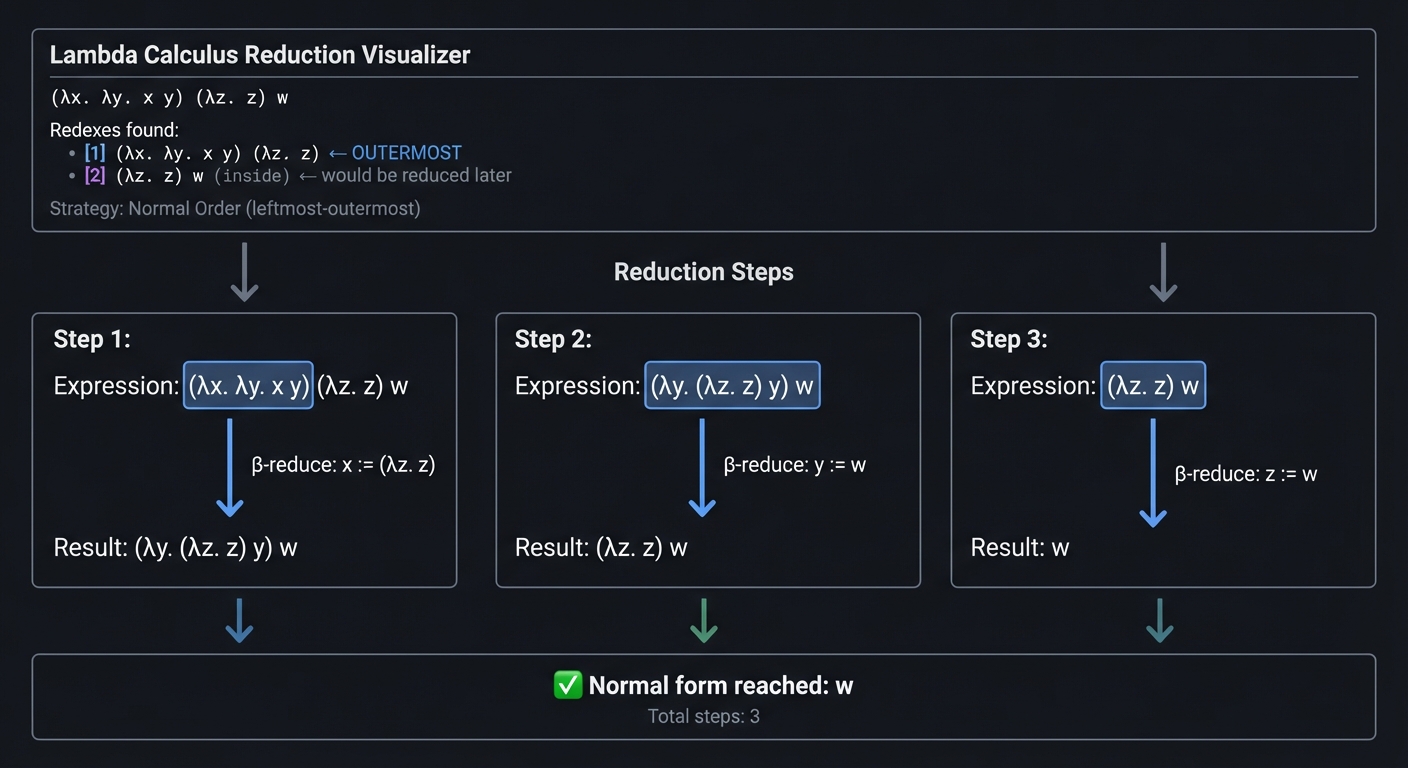
Project 3: Reduction Visualizer
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: Elm, PureScript, Racket
- Coolness Level: Level 4: Hardcore Tech Flex
- Business Potential: 2. The “Micro-SaaS / Pro Tool”
- Difficulty: Level 3: Advanced
- Knowledge Area: Lambda Calculus / Evaluation
- Software or Tool: Step-by-Step Reducer
- Main Book: “Types and Programming Languages” by Benjamin Pierce
What you’ll build
A visual/interactive tool that shows beta-reduction step-by-step, highlighting the redex being reduced, showing variable substitutions, and allowing the user to choose which redex to reduce (exploring different reduction orders).
Why it teaches Lambda Calculus
Seeing reduction happen step-by-step makes the abstract concrete. You’ll understand why different reduction strategies matter, what the Church-Rosser theorem means in practice, and how infinite loops (non-termination) arise.
Core challenges you’ll face
- Identifying all redexes (finding all places where reduction can happen) → maps to reduction locations
- Highlighting substitution (showing what gets replaced) → maps to substitution visualization
- Step-by-step control (pause, step, choose redex) → maps to interactive exploration
- Detecting loops (recognizing non-terminating reductions) → maps to termination
Key Concepts
- Reduction Strategies: “Types and Programming Languages” Chapter 5 - Pierce
- Church-Rosser Theorem: Normal forms are unique (if they exist)
- Normal Order: Always finds normal form if it exists
- Applicative Order: May loop even when normal form exists
Difficulty
Advanced
Time estimate
1-2 weeks
Prerequisites
Project 1, basic terminal/web UI
Real world outcome
╔══════════════════════════════════════════════════════════════╗
║ Lambda Calculus Reduction Visualizer ║
╠══════════════════════════════════════════════════════════════╣
║ Expression: (λx. λy. x y) (λz. z) w ║
║ ║
║ Redexes found: ║
║ [1] (λx. λy. x y) (λz. z) ← OUTERMOST ║
║ [2] (λz. z) w (inside) ← would be reduced later ║
║ ║
║ Strategy: Normal Order (leftmost-outermost) ║
╠══════════════════════════════════════════════════════════════╣
║ Step 1: ║
║ (λx. λy. x y) (λz. z) w ║
║ └──────────┬────────┘ ║
║ ↓ β-reduce: x := (λz. z) ║
║ (λy. (λz. z) y) w ║
║ ║
║ Step 2: ║
║ (λy. (λz. z) y) w ║
║ └──────────┬─────┘ ║
║ ↓ β-reduce: y := w ║
║ (λz. z) w ║
║ ║
║ Step 3: ║
║ (λz. z) w ║
║ └───┬───┘ ║
║ ↓ β-reduce: z := w ║
║ w ║
║ ║
║ ✓ Normal form reached: w ║
║ Total steps: 3 ║
╚══════════════════════════════════════════════════════════════╝
Implementation Hints
Key is to find all redexes and tag them with their position:
Pseudo-Haskell:
-- A path through the term tree
data Path = Here | GoLeft Path | GoRight Path | GoBody Path
-- Find all redexes and their paths
findRedexes :: Term -> [(Path, Term)]
findRedexes term = case term of
App (Lam x body) arg ->
(Here, term) :
map (first GoLeft) (findRedexes (Lam x body)) ++
map (first GoRight) (findRedexes arg)
App e1 e2 ->
map (first GoLeft) (findRedexes e1) ++
map (first GoRight) (findRedexes e2)
Lam x body ->
map (first GoBody) (findRedexes body)
Var _ -> []
-- Reduce at a specific path
reduceAt :: Path -> Term -> Term
reduceAt Here (App (Lam x body) arg) = subst x arg body
reduceAt (GoLeft p) (App e1 e2) = App (reduceAt p e1) e2
reduceAt (GoRight p) (App e1 e2) = App e1 (reduceAt p e2)
reduceAt (GoBody p) (Lam x body) = Lam x (reduceAt p body)
-- Normal order: reduce leftmost-outermost first
normalOrderStep :: Term -> Maybe Term
normalOrderStep term =
case findRedexes term of
[] -> Nothing
((path, _):_) -> Just (reduceAt path term) -- first = leftmost-outermost
Learning milestones
- Can find all redexes → You understand reduction locations
- User can choose which to reduce → You understand strategies are choices
- Same expression, different paths, same result → You understand Church-Rosser
- Detects omega (infinite loop) → You understand non-termination
Project 4: Simply Typed Lambda Calculus + Type Inference
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: OCaml, Rust, Scala
- Coolness Level: Level 5: Pure Magic (Super Cool)
- Business Potential: 1. The “Resume Gold” (Educational/Personal Brand)
- Difficulty: Level 4: Expert
- Knowledge Area: Type Theory / Type Inference
- Software or Tool: Hindley-Milner Type Checker
- Main Book: “Types and Programming Languages” by Benjamin Pierce
What you’ll build
Extend your lambda calculus interpreter with types: a type checker for the simply typed lambda calculus, then Hindley-Milner type inference with let-polymorphism.
Why it teaches Type Systems
Haskell’s type system is built on Hindley-Milner inference. By implementing it yourself, you’ll understand how the compiler figures out types, why polymorphism works, and what those type error messages really mean.
Core challenges you’ll face
- Type representation (function types, type variables) → maps to type syntax
- Type checking (given a type, verify the term has it) → maps to type verification
- Unification (finding substitutions that make types equal) → maps to constraint solving
- Generalization/Instantiation (let-polymorphism) → maps to polymorphic types
Key Concepts
- Simply Typed Lambda Calculus: “Types and Programming Languages” Chapters 9-11 - Pierce
- Hindley-Milner: “Types and Programming Languages” Chapter 22 - Pierce
- Algorithm W: Wikipedia: Hindley-Milner
- Unification: “The Art of Prolog” Chapter 3 - Sterling & Shapiro
Difficulty
Expert
Time estimate
3-4 weeks
Prerequisites
Project 1, understanding of substitution
Real world outcome
λ> :type \x -> x
Inferred type: a -> a
λ> :type \f -> \x -> f (f x)
Inferred type: (a -> a) -> a -> a
λ> :type \f -> \g -> \x -> f (g x)
Inferred type: (b -> c) -> (a -> b) -> a -> c
λ> let id = \x -> x in (id 1, id True)
Inferred type: (Int, Bool)
-- Note: id is polymorphic, used at both Int and Bool!
λ> :type \x -> x x
Type error: Cannot unify 'a' with 'a -> b'
(Occurs check failed - infinite type)
λ> :type \f -> \x -> f x x
Inferred type: (a -> a -> b) -> a -> b
Implementation Hints
The key insight: type inference generates constraints, then solves them via unification.
Pseudo-Haskell:
data Type
= TVar String -- Type variable: a, b, c
| TArrow Type Type -- Function type: a -> b
| TInt | TBool -- Base types
data Scheme = Forall [String] Type -- Polymorphic type: ∀a. a -> a
-- Unification: find substitution making two types equal
unify :: Type -> Type -> Either TypeError Substitution
unify (TVar a) t = bindVar a t
unify t (TVar a) = bindVar a t
unify (TArrow a1 a2) (TArrow b1 b2) = do
s1 <- unify a1 b1
s2 <- unify (apply s1 a2) (apply s1 b2)
return (compose s2 s1)
unify TInt TInt = return empty
unify TBool TBool = return empty
unify t1 t2 = Left (CannotUnify t1 t2)
bindVar :: String -> Type -> Either TypeError Substitution
bindVar a (TVar b) | a == b = return empty
bindVar a t | a `occursIn` t = Left (InfiniteType a t) -- Occurs check!
bindVar a t = return (singleton a t)
-- Algorithm W: infer type of term in environment
infer :: Env -> Term -> Infer (Substitution, Type)
infer env (Var x) =
case lookup x env of
Just scheme -> do
t <- instantiate scheme -- Replace ∀-bound vars with fresh vars
return (empty, t)
Nothing -> throwError (UnboundVariable x)
infer env (Lam x body) = do
a <- freshTypeVar
(s, t) <- infer (extend x (Forall [] a) env) body
return (s, TArrow (apply s a) t)
infer env (App e1 e2) = do
(s1, t1) <- infer env e1
(s2, t2) <- infer (apply s1 env) e2
a <- freshTypeVar
s3 <- unify (apply s2 t1) (TArrow t2 a)
return (compose s3 (compose s2 s1), apply s3 a)
infer env (Let x e1 e2) = do
(s1, t1) <- infer env e1
let scheme = generalize (apply s1 env) t1 -- Polymorphism!
(s2, t2) <- infer (extend x scheme (apply s1 env)) e2
return (compose s2 s1, t2)
Learning milestones
- Type checking works → You understand type verification
- Unification solves constraints → You understand type equations
- Occurs check catches infinite types → You understand termination
- Let-polymorphism works → You understand generalization
Project 5: Algebraic Data Types and Pattern Matching
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: OCaml, Rust, Scala
- Coolness Level: Level 3: Genuinely Clever
- Business Potential: 1. The “Resume Gold” (Educational/Personal Brand)
- Difficulty: Level 2: Intermediate
- Knowledge Area: Functional Programming / Data Types
- Software or Tool: ADT Library
- Main Book: “Haskell Programming from First Principles” by Christopher Allen and Julie Moronuki
What you’ll build
Implement core Haskell data types from scratch: Maybe, Either, List, Tree, along with all their associated functions. Understand sums, products, recursive types, and exhaustive pattern matching.
Why it teaches Functional Programming
Algebraic Data Types are the way to model data in functional programming. Understanding that types are built from sums (OR) and products (AND), and that pattern matching is structural recursion, is fundamental to thinking functionally.
Core challenges you’ll face
- Sum types (Either, Maybe - one of several alternatives) → maps to tagged unions
- Product types (tuples, records - all fields together) → maps to structs
- Recursive types (List, Tree - types containing themselves) → maps to inductive definitions
- Pattern matching (destructuring and dispatch) → maps to structural recursion
Key Concepts
- Algebraic Data Types: “Haskell Programming from First Principles” Chapter 11
- Pattern Matching: “Learn You a Haskell for Great Good!” Chapter 4
- Recursive Data: “Programming in Haskell” Chapter 8 - Graham Hutton
Difficulty
Intermediate
Time estimate
1-2 weeks
Prerequisites
Basic Haskell syntax
Real world outcome
-- Your implementations:
λ> :t myMaybe
myMaybe :: MyMaybe a
λ> myJust 5 >>= (\x -> myJust (x * 2))
MyJust 10
λ> myNothing >>= (\x -> myJust (x * 2))
MyNothing
λ> myFoldr (+) 0 (myCons 1 (myCons 2 (myCons 3 myNil)))
6
λ> myMap (*2) (myCons 1 (myCons 2 (myCons 3 myNil)))
MyCons 2 (MyCons 4 (MyCons 6 MyNil))
λ> treeSum (Node 1 (Node 2 Leaf Leaf) (Node 3 Leaf Leaf))
6
λ> treeDepth (Node 1 (Node 2 (Node 3 Leaf Leaf) Leaf) Leaf)
3
Implementation Hints
Pseudo-Haskell:
-- Maybe: a value or nothing
data MyMaybe a = MyNothing | MyJust a
myFromMaybe :: a -> MyMaybe a -> a
myFromMaybe def MyNothing = def
myFromMaybe _ (MyJust x) = x
myMapMaybe :: (a -> b) -> MyMaybe a -> MyMaybe b
myMapMaybe _ MyNothing = MyNothing
myMapMaybe f (MyJust x) = MyJust (f x)
-- Either: one of two alternatives
data MyEither a b = MyLeft a | MyRight b
myEither :: (a -> c) -> (b -> c) -> MyEither a b -> c
myEither f _ (MyLeft x) = f x
myEither _ g (MyRight y) = g y
-- List: recursive sequence
data MyList a = MyNil | MyCons a (MyList a)
myFoldr :: (a -> b -> b) -> b -> MyList a -> b
myFoldr _ z MyNil = z
myFoldr f z (MyCons x xs) = f x (myFoldr f z xs)
myMap :: (a -> b) -> MyList a -> MyList b
myMap f = myFoldr (\x acc -> MyCons (f x) acc) MyNil
myFilter :: (a -> Bool) -> MyList a -> MyList a
myFilter p = myFoldr (\x acc -> if p x then MyCons x acc else acc) MyNil
-- Binary Tree
data MyTree a = Leaf | Node a (MyTree a) (MyTree a)
treeSum :: Num a => MyTree a -> a
treeSum Leaf = 0
treeSum (Node x left right) = x + treeSum left + treeSum right
treeFold :: b -> (a -> b -> b -> b) -> MyTree a -> b
treeFold leaf _ Leaf = leaf
treeFold leaf node (Node x left right) =
node x (treeFold leaf node left) (treeFold leaf node right)
Learning milestones
- Maybe and Either work → You understand sum types
- List fold/map work → You understand recursion schemes
- Tree operations work → You understand recursive data
- Can express any computation with folds → You understand catamorphisms
Project 6: The Functor-Applicative-Monad Hierarchy
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: Scala, PureScript, OCaml
- Coolness Level: Level 4: Hardcore Tech Flex
- Business Potential: 1. The “Resume Gold” (Educational/Personal Brand)
- Difficulty: Level 4: Expert
- Knowledge Area: Type Classes / Category Theory
- Software or Tool: Type Class Hierarchy
- Main Book: “Haskell Programming from First Principles” by Christopher Allen and Julie Moronuki
What you’ll build
Implement the Functor → Applicative → Monad hierarchy from scratch for multiple types (Maybe, Either, List, Reader, State), proving the laws hold and understanding why each abstraction is needed.
Why it teaches Functional Programming
Monads are infamous, but they’re just the third level of a beautiful abstraction hierarchy. Understanding this progression—from “mappable” (Functor) to “liftable” (Applicative) to “flattenable” (Monad)—is the key to advanced Haskell.
Core challenges you’ll face
- Functor (mapping over structure:
fmap) → maps to preserving structure - Applicative (applying wrapped functions:
<*>) → maps to independent effects - Monad (sequencing with result dependency:
>>=) → maps to dependent effects - Laws (proving identity, composition, associativity) → maps to correctness
Key Concepts
- Functors: “Haskell Programming from First Principles” Chapter 16
- Applicatives: “Haskell Programming from First Principles” Chapter 17
- Monads: “Haskell Programming from First Principles” Chapter 18
- Category Theory Connection: Haskell Wikibooks - Category Theory
Difficulty
Expert
Time estimate
2-3 weeks
Prerequisites
Project 5, understanding of type classes
Real world outcome
-- Your implementations work with any Functor/Applicative/Monad:
λ> myFmap (+1) (MyJust 5)
MyJust 6
λ> myPure (+) <*> MyJust 3 <*> MyJust 4
MyJust 7
λ> MyJust 3 >>= (\x -> MyJust 4 >>= (\y -> MyJust (x + y)))
MyJust 7
-- Same code works for List:
λ> myFmap (*2) (MyCons 1 (MyCons 2 (MyCons 3 MyNil)))
MyCons 2 (MyCons 4 (MyCons 6 MyNil))
λ> myPure (+) <*> (MyCons 1 (MyCons 2 MyNil)) <*> (MyCons 10 (MyCons 20 MyNil))
MyCons 11 (MyCons 21 (MyCons 12 (MyCons 22 MyNil)))
-- Functor laws verified:
λ> verifyFunctorIdentity (MyJust 5)
✓ fmap id = id
λ> verifyFunctorComposition (+1) (*2) (MyJust 5)
✓ fmap (f . g) = fmap f . fmap g
Implementation Hints
Pseudo-Haskell:
-- Functor: things you can map over
class MyFunctor f where
myFmap :: (a -> b) -> f a -> f b
-- Laws:
-- Identity: fmap id = id
-- Composition: fmap (f . g) = fmap f . fmap g
instance MyFunctor MyMaybe where
myFmap _ MyNothing = MyNothing
myFmap f (MyJust x) = MyJust (f x)
instance MyFunctor MyList where
myFmap _ MyNil = MyNil
myFmap f (MyCons x xs) = MyCons (f x) (myFmap f xs)
-- Applicative: Functors with "pure" and "apply"
class MyFunctor f => MyApplicative f where
myPure :: a -> f a
(<*>) :: f (a -> b) -> f a -> f b
-- Laws:
-- Identity: pure id <*> v = v
-- Homomorphism: pure f <*> pure x = pure (f x)
-- Interchange: u <*> pure y = pure ($ y) <*> u
-- Composition: pure (.) <*> u <*> v <*> w = u <*> (v <*> w)
instance MyApplicative MyMaybe where
myPure = MyJust
MyNothing <*> _ = MyNothing
_ <*> MyNothing = MyNothing
(MyJust f) <*> (MyJust x) = MyJust (f x)
instance MyApplicative MyList where
myPure x = MyCons x MyNil
fs <*> xs = myFlatMap (\f -> myFmap f xs) fs
-- Monad: Applicatives with "bind"
class MyApplicative m => MyMonad m where
(>>=) :: m a -> (a -> m b) -> m b
-- Laws:
-- Left identity: return a >>= f = f a
-- Right identity: m >>= return = m
-- Associativity: (m >>= f) >>= g = m >>= (\x -> f x >>= g)
instance MyMonad MyMaybe where
MyNothing >>= _ = MyNothing
(MyJust x) >>= f = f x
instance MyMonad MyList where
xs >>= f = myFlatMap f xs
myFlatMap :: (a -> MyList b) -> MyList a -> MyList b
myFlatMap _ MyNil = MyNil
myFlatMap f (MyCons x xs) = myAppend (f x) (myFlatMap f xs)
-- The difference between Applicative and Monad:
-- Applicative: effects are independent (can be parallelized)
-- Monad: later effects can depend on earlier results
-- With Applicative, you can do:
liftA2 :: MyApplicative f => (a -> b -> c) -> f a -> f b -> f c
liftA2 f x y = myPure f <*> x <*> y
-- With Monad, you can do:
-- x >>= (\a -> y >>= (\b -> if a > 0 then ... else ...))
-- The choice of second effect depends on first result!
Learning milestones
- Functor instances work → You understand mapping over structure
- Applicative instances work → You understand independent effects
- Monad instances work → You understand dependent sequencing
- Laws verified → You understand correctness guarantees
Project 7: Parser Combinator Library
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: Scala, OCaml, F#
- Coolness Level: Level 4: Hardcore Tech Flex
- Business Potential: 3. The “Service & Support” Model
- Difficulty: Level 3: Advanced
- Knowledge Area: Parsing / Combinators
- Software or Tool: Parsec Clone
- Main Book: “Programming in Haskell” by Graham Hutton
What you’ll build
A monadic parser combinator library (like Parsec) from scratch. Combinators for sequencing, choice, repetition, and error reporting. Use it to parse a non-trivial language (JSON or a simple programming language).
Why it teaches Functional Programming
Parser combinators are the crown jewel of functional programming. They demonstrate how small, composable pieces combine into powerful tools. You’ll see monads in their natural habitat: sequencing computations that might fail.
Core challenges you’ll face
- Parser type (String → Maybe (a, String) or better) → maps to state + failure
- Functor/Applicative/Monad (making parsers composable) → maps to type class instances
- Alternative (choice between parsers:
<|>) → maps to backtracking - Error messages (what went wrong, where) → maps to practical usability
Key Concepts
- Parser Combinators: “Programming in Haskell” Chapter 13 - Graham Hutton
- Monadic Parsing: “Monadic Parsing in Haskell” paper by Hutton & Meijer
- Error Handling: “Megaparsec” documentation
Difficulty
Advanced
Time estimate
2-3 weeks
Prerequisites
Projects 5 & 6
Real world outcome
-- Define JSON parser using your combinators:
jsonValue :: Parser JSON
jsonValue = jsonNull <|> jsonBool <|> jsonNumber <|> jsonString
<|> jsonArray <|> jsonObject
-- Parse JSON:
λ> parse jsonValue "{\"name\": \"Alice\", \"age\": 30, \"active\": true}"
Right (JObject [("name", JString "Alice"), ("age", JNumber 30), ("active", JBool True)])
λ> parse jsonValue "[1, 2, 3]"
Right (JArray [JNumber 1, JNumber 2, JNumber 3])
λ> parse jsonValue "{invalid"
Left "Line 1, Column 2: Expected '\"', got 'i'"
-- Parse arithmetic expressions:
λ> parse expr "1 + 2 * 3"
Right (Add (Num 1) (Mul (Num 2) (Num 3)))
λ> parse expr "(1 + 2) * 3"
Right (Mul (Add (Num 1) (Num 2)) (Num 3))
Implementation Hints
Pseudo-Haskell:
-- Parser type: input → either error or (result, remaining input)
newtype Parser a = Parser { runParser :: String -> Either ParseError (a, String) }
data ParseError = ParseError { pePosition :: Int, peExpected :: String, peGot :: String }
instance Functor Parser where
fmap f (Parser p) = Parser $ \input -> do
(x, rest) <- p input
return (f x, rest)
instance Applicative Parser where
pure x = Parser $ \input -> Right (x, input)
(Parser pf) <*> (Parser pa) = Parser $ \input -> do
(f, rest1) <- pf input
(a, rest2) <- pa rest1
return (f a, rest2)
instance Monad Parser where
(Parser pa) >>= f = Parser $ \input -> do
(a, rest) <- pa input
runParser (f a) rest
instance Alternative Parser where
empty = Parser $ \_ -> Left (ParseError 0 "something" "nothing")
(Parser p1) <|> (Parser p2) = Parser $ \input ->
case p1 input of
Right result -> Right result
Left _ -> p2 input -- backtrack and try p2
-- Primitive parsers
satisfy :: (Char -> Bool) -> Parser Char
satisfy pred = Parser $ \input -> case input of
(c:cs) | pred c -> Right (c, cs)
(c:_) -> Left (ParseError 0 "matching char" [c])
[] -> Left (ParseError 0 "char" "end of input")
char :: Char -> Parser Char
char c = satisfy (== c)
string :: String -> Parser String
string = traverse char
-- Combinators
many :: Parser a -> Parser [a]
many p = many1 p <|> pure []
many1 :: Parser a -> Parser [a]
many1 p = (:) <$> p <*> many p
sepBy :: Parser a -> Parser sep -> Parser [a]
sepBy p sep = sepBy1 p sep <|> pure []
sepBy1 :: Parser a -> Parser sep -> Parser [a]
sepBy1 p sep = (:) <$> p <*> many (sep *> p)
between :: Parser open -> Parser close -> Parser a -> Parser a
between open close p = open *> p <* close
-- JSON parser (using your combinators!)
jsonNull :: Parser JSON
jsonNull = JNull <$ string "null"
jsonBool :: Parser JSON
jsonBool = (JBool True <$ string "true") <|> (JBool False <$ string "false")
jsonNumber :: Parser JSON
jsonNumber = JNumber . read <$> many1 (satisfy isDigit)
jsonString :: Parser JSON
jsonString = JString <$> between (char '"') (char '"') (many (satisfy (/= '"')))
jsonArray :: Parser JSON
jsonArray = JArray <$> between (char '[') (char ']') (sepBy jsonValue (char ','))
jsonObject :: Parser JSON
jsonObject = JObject <$> between (char '{') (char '}') (sepBy keyValue (char ','))
where keyValue = (,) <$> (jstring <* char ':') <*> jsonValue
Learning milestones
- Basic parsers work → You understand the parser type
- Combinators compose → You understand monadic sequencing
- JSON parses correctly → You’ve built something useful
- Good error messages → You’ve made it practical
Project 8: Lazy Evaluation Demonstrator
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: Scala (with lazy vals), OCaml (with Lazy)
- Coolness Level: Level 4: Hardcore Tech Flex
- Business Potential: 1. The “Resume Gold” (Educational/Personal Brand)
- Difficulty: Level 4: Expert
- Knowledge Area: Evaluation Strategies / Laziness
- Software or Tool: Thunk Visualizer
- Main Book: “Haskell in Depth” by Vitaly Bragilevsky
What you’ll build
A visualization tool showing how lazy evaluation works: thunks, forcing, sharing, and space leaks. Implement a lazy evaluator and demonstrate infinite data structures.
Why it teaches Functional Programming
Laziness is Haskell’s secret weapon and biggest footgun. Understanding thunks, weak head normal form, and when forcing happens lets you write efficient code and debug space leaks.
Core challenges you’ll face
- Thunk representation (suspended computations) → maps to call-by-need
- Forcing and WHNF (when evaluation happens) → maps to evaluation order
- Sharing (computing once, using many times) → maps to efficiency
- Space leaks (thunks accumulating) → maps to performance
- Infinite structures (lazy lists, streams) → maps to elegance
Key Concepts
- Lazy Evaluation: “Haskell in Depth” Chapter 4 - Bragilevsky
- Space Leaks: “Real World Haskell” Chapter 25 - O’Sullivan et al.
- Strictness Analysis: GHC documentation on strictness
Difficulty
Expert
Time estimate
2-3 weeks
Prerequisites
Projects 1-6
Real world outcome
λ> let xs = [1..] in take 5 xs
-- Visualization:
xs = 1 : <thunk>
↓ force (need 5 elements)
xs = 1 : 2 : <thunk>
↓ force
xs = 1 : 2 : 3 : <thunk>
↓ force
xs = 1 : 2 : 3 : 4 : <thunk>
↓ force
xs = 1 : 2 : 3 : 4 : 5 : <thunk> -- thunk remains!
Result: [1, 2, 3, 4, 5]
Thunks created: 6
Thunks forced: 5
Thunks remaining: 1 (rest of infinite list)
λ> let fibs = 0 : 1 : zipWith (+) fibs (tail fibs)
λ> take 10 fibs
-- Sharing visualization:
fibs[0] = 0 (computed)
fibs[1] = 1 (computed)
fibs[2] = <thunk: fibs[0] + fibs[1]>
↓ force
fibs[2] = 1 (computed, shared reference)
fibs[3] = <thunk: fibs[1] + fibs[2]>
↓ force (reuses computed fibs[2]!)
fibs[3] = 2 (computed)
...
Result: [0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
Additions performed: 8 (not exponential!)
λ> foldl (+) 0 [1..1000000]
-- Space leak visualization:
0 + 1 = <thunk>
<thunk> + 2 = <thunk>
<thunk> + 3 = <thunk>
... 1 million thunks! ...
Finally forced → stack overflow!
λ> foldl' (+) 0 [1..1000000]
-- Strict version:
0 + 1 = 1 (forced immediately)
1 + 2 = 3 (forced immediately)
3 + 3 = 6 (forced immediately)
... constant space! ...
Result: 500000500000
Implementation Hints
Build a small lazy language evaluator:
Pseudo-Haskell:
-- Thunk: unevaluated expression + environment
data Thunk = Thunk Expr Env | Forced Value
-- Value in WHNF (Weak Head Normal Form)
data Value
= VInt Int
| VBool Bool
| VClosure String Expr Env
| VCons Thunk Thunk -- Lazy list: head and tail are thunks
| VNil
-- Mutable thunk storage (for sharing)
type ThunkRef = IORef Thunk
-- Force a thunk: evaluate to WHNF and cache result
force :: ThunkRef -> IO Value
force ref = do
thunk <- readIORef ref
case thunk of
Forced v -> return v -- Already computed, return cached
Thunk expr env -> do
v <- eval expr env
writeIORef ref (Forced v) -- Cache the result!
return v
-- Evaluate expression to WHNF
eval :: Expr -> Env -> IO Value
eval (Var x) env =
case lookup x env of
Just ref -> force ref -- Force the thunk
Nothing -> error "Unbound variable"
eval (Lam x body) env = return (VClosure x body env)
eval (App f arg) env = do
fVal <- eval f env
case fVal of
VClosure x body closureEnv -> do
-- Don't evaluate arg yet! Create thunk
argRef <- newIORef (Thunk arg env)
eval body ((x, argRef) : closureEnv)
eval (Cons hd tl) env = do
-- Both head and tail are thunks!
hdRef <- newIORef (Thunk hd env)
tlRef <- newIORef (Thunk tl env)
return (VCons hdRef tlRef)
-- Infinite list of ones
-- ones = 1 : ones
-- ones = Cons (Int 1) (Var "ones")
-- with environment { "ones" -> <thunk: ones definition> }
Learning milestones
- Thunks visualize correctly → You understand lazy evaluation
- Sharing prevents recomputation → You understand efficiency
- Infinite structures work → You understand laziness power
- Space leaks identified → You understand strictness
Project 9: Monad Transformers from Scratch
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: Scala, PureScript
- Coolness Level: Level 4: Hardcore Tech Flex
- Business Potential: 1. The “Resume Gold” (Educational/Personal Brand)
- Difficulty: Level 4: Expert
- Knowledge Area: Effects / Monad Transformers
- Software or Tool: MTL Clone
- Main Book: “Haskell in Depth” by Vitaly Bragilevsky
What you’ll build
Implement the common monad transformers (MaybeT, EitherT, ReaderT, StateT, WriterT) and understand how to stack them to combine effects.
Why it teaches Functional Programming
Real programs need multiple effects: reading config, maintaining state, handling errors, logging. Monad transformers let you compose these effects. Understanding them is essential for real Haskell.
Core challenges you’ll face
- Transformer types (wrapping monads in other monads) → maps to effect composition
- Lift operation (running inner monad in outer) → maps to effect access
- MonadTrans class (abstracting over transformers) → maps to generic lifting
- Stack ordering (StateT over Maybe vs Maybe over State) → maps to effect semantics
Key Concepts
- Monad Transformers: “Haskell in Depth” Chapter 5 - Bragilevsky
- MTL Style: “Monad Transformers Step by Step” paper by Martin Grabmüller
- Effect Order: Different orders give different behaviors!
Difficulty
Expert
Time estimate
2-3 weeks
Prerequisites
Project 6 (Functor/Applicative/Monad)
Real world outcome
-- Stack: ReaderT Config (StateT AppState (ExceptT AppError IO))
type App a = ReaderT Config (StateT AppState (ExceptT AppError IO)) a
runApp :: Config -> AppState -> App a -> IO (Either AppError (a, AppState))
runApp config state app =
runExceptT (runStateT (runReaderT app config) state)
-- Your transformers in action:
myProgram :: App String
myProgram = do
config <- ask -- ReaderT effect
modify (incrementCounter) -- StateT effect
when (count config > 100) $
throwError TooManyRequests -- ExceptT effect
liftIO $ putStrLn "Hello" -- IO effect
return "done"
λ> runApp defaultConfig initialState myProgram
Right ("done", AppState { counter = 1, ... })
λ> runApp badConfig initialState myProgram
Left TooManyRequests
Implementation Hints
Pseudo-Haskell:
-- MaybeT: add failure to any monad
newtype MaybeT m a = MaybeT { runMaybeT :: m (Maybe a) }
instance Monad m => Functor (MaybeT m) where
fmap f (MaybeT mma) = MaybeT $ fmap (fmap f) mma
instance Monad m => Applicative (MaybeT m) where
pure = MaybeT . pure . Just
(MaybeT mmf) <*> (MaybeT mma) = MaybeT $ do
mf <- mmf
case mf of
Nothing -> return Nothing
Just f -> fmap (fmap f) mma
instance Monad m => Monad (MaybeT m) where
(MaybeT mma) >>= f = MaybeT $ do
ma <- mma
case ma of
Nothing -> return Nothing
Just a -> runMaybeT (f a)
-- StateT: add mutable state to any monad
newtype StateT s m a = StateT { runStateT :: s -> m (a, s) }
instance Monad m => Monad (StateT s m) where
(StateT f) >>= g = StateT $ \s -> do
(a, s') <- f s
runStateT (g a) s'
get :: Monad m => StateT s m s
get = StateT $ \s -> return (s, s)
put :: Monad m => s -> StateT s m ()
put s = StateT $ \_ -> return ((), s)
modify :: Monad m => (s -> s) -> StateT s m ()
modify f = get >>= put . f
-- ReaderT: add read-only environment to any monad
newtype ReaderT r m a = ReaderT { runReaderT :: r -> m a }
instance Monad m => Monad (ReaderT r m) where
(ReaderT f) >>= g = ReaderT $ \r -> do
a <- f r
runReaderT (g a) r
ask :: Monad m => ReaderT r m r
ask = ReaderT return
local :: (r -> r) -> ReaderT r m a -> ReaderT r m a
local f (ReaderT g) = ReaderT (g . f)
-- MonadTrans: lifting operations
class MonadTrans t where
lift :: Monad m => m a -> t m a
instance MonadTrans MaybeT where
lift ma = MaybeT (fmap Just ma)
instance MonadTrans (StateT s) where
lift ma = StateT $ \s -> fmap (\a -> (a, s)) ma
instance MonadTrans (ReaderT r) where
lift ma = ReaderT $ \_ -> ma
Learning milestones
- Individual transformers work → You understand each effect
- Stacking works → You understand composition
- Lift works at any level → You understand MonadTrans
- Different orders behave differently → You understand effect semantics
Project 10: Property-Based Testing Framework
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: Scala (ScalaCheck), F# (FsCheck), Python (Hypothesis)
- Coolness Level: Level 4: Hardcore Tech Flex
- Business Potential: 3. The “Service & Support” Model
- Difficulty: Level 3: Advanced
- Knowledge Area: Testing / Generators
- Software or Tool: QuickCheck Clone
- Main Book: “Real World Haskell” by O’Sullivan, Stewart, and Goerzen
What you’ll build
A property-based testing framework like QuickCheck: random generators for data, shrinking failing cases, and the core property-checking loop.
Why it teaches Functional Programming
QuickCheck is a landmark Haskell invention that spread to every language. It shows the power of higher-order functions and type classes for building generic, composable test infrastructure.
Core challenges you’ll face
- Random generators (Gen monad for generating test data) → maps to monadic generation
- Arbitrary type class (generating any type) → maps to type class polymorphism
- Shrinking (finding minimal failing case) → maps to search algorithms
- Property composition (combining tests) → maps to combinator design
Key Concepts
- QuickCheck Paper: “QuickCheck: A Lightweight Tool for Random Testing” by Claessen & Hughes
- Generators: “Real World Haskell” Chapter 11
- Shrinking: Finding the smallest counterexample
Difficulty
Advanced
Time estimate
2-3 weeks
Prerequisites
Projects 5 & 6, understanding of randomness
Real world outcome
-- Properties written with your framework:
prop_reverse_reverse :: [Int] -> Bool
prop_reverse_reverse xs = reverse (reverse xs) == xs
prop_append_length :: [Int] -> [Int] -> Bool
prop_append_length xs ys = length (xs ++ ys) == length xs + length ys
-- Bug detection:
prop_bad_sort :: [Int] -> Bool
prop_bad_sort xs = badSort xs == sort xs
λ> quickCheck prop_reverse_reverse
+++ OK, passed 100 tests.
λ> quickCheck prop_append_length
+++ OK, passed 100 tests.
λ> quickCheck prop_bad_sort
*** Failed! Falsifiable (after 12 tests):
[3, 1, 2]
Shrinking...
*** Failed! Falsifiable (after 12 tests and 4 shrinks):
[1, 0] -- Minimal counterexample!
Implementation Hints
Pseudo-Haskell:
-- Generator monad
newtype Gen a = Gen { runGen :: StdGen -> (a, StdGen) }
instance Monad Gen where
return x = Gen $ \g -> (x, g)
(Gen f) >>= k = Gen $ \g ->
let (a, g') = f g
in runGen (k a) g'
-- Arbitrary: types that can be randomly generated
class Arbitrary a where
arbitrary :: Gen a
shrink :: a -> [a] -- List of "smaller" values
shrink _ = []
instance Arbitrary Int where
arbitrary = Gen $ \g -> random g
shrink 0 = []
shrink n = [0, n `div` 2] -- Shrink towards 0
instance Arbitrary a => Arbitrary [a] where
arbitrary = do
len <- choose (0, 30)
replicateM len arbitrary
shrink [] = []
shrink (x:xs) =
[] : xs : -- Remove first element
[x':xs | x' <- shrink x] ++ -- Shrink first element
[x:xs' | xs' <- shrink xs] -- Shrink rest
-- Core testing loop
quickCheck :: Arbitrary a => (a -> Bool) -> IO ()
quickCheck prop = do
g <- newStdGen
loop 100 g
where
loop 0 _ = putStrLn "+++ OK, passed 100 tests."
loop n g = do
let (value, g') = runGen arbitrary g
if prop value
then loop (n-1) g'
else do
putStrLn $ "*** Failed! Falsifiable (after " ++ show (101-n) ++ " tests):"
print value
shrinkLoop value
shrinkLoop value =
case filter (not . prop) (shrink value) of
[] -> do
putStrLn "Minimal counterexample:"
print value
(smaller:_) -> shrinkLoop smaller -- Keep shrinking!
-- Combinators
choose :: (Int, Int) -> Gen Int
choose (lo, hi) = Gen $ \g -> randomR (lo, hi) g
elements :: [a] -> Gen a
elements xs = do
i <- choose (0, length xs - 1)
return (xs !! i)
oneof :: [Gen a] -> Gen a
oneof gens = do
i <- choose (0, length gens - 1)
gens !! i
Learning milestones
- Generators work → You understand monadic random generation
- Arbitrary instances work → You understand type class polymorphism
- Shrinking finds minimal cases → You understand search
- Framework catches real bugs → You’ve built something useful
Project 11: Lenses and Optics Library
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: Scala (Monocle), PureScript
- Coolness Level: Level 4: Hardcore Tech Flex
- Business Potential: 1. The “Resume Gold” (Educational/Personal Brand)
- Difficulty: Level 4: Expert
- Knowledge Area: Data Access / Optics
- Software or Tool: Lens Clone
- Main Book: “Optics By Example” by Chris Penner
What you’ll build
Implement the lens hierarchy: Lens, Prism, Traversal, Iso. Understand how they compose and use them to elegantly access and update nested data.
Why it teaches Functional Programming
In imperative programming, updating nested data is trivial: person.address.city = "NYC". In pure FP, without mutation, this requires boilerplate. Lenses solve this elegantly, and understanding them reveals deep connections to profunctors and category theory.
Core challenges you’ll face
- Lens type (getter + setter combined) → maps to composable access
- Van Laarhoven encoding (lens as function) → maps to higher-order magic
- Prisms (for sum types) → maps to partial access
- Traversals (for multiple targets) → maps to batch updates
Key Concepts
- Lenses: “Optics By Example” by Chris Penner
- Van Laarhoven: “Lenses, Folds, and Traversals” by Edward Kmett
- Profunctor Optics: Academic papers on optics
Difficulty
Expert
Time estimate
3-4 weeks
Prerequisites
Projects 5 & 6, comfort with higher-order functions
Real world outcome
-- Deeply nested update, elegantly:
data Person = Person { _name :: String, _address :: Address }
data Address = Address { _city :: String, _street :: String }
-- Without lenses (ugly):
updateCity :: String -> Person -> Person
updateCity newCity person =
person { _address = (_address person) { _city = newCity } }
-- With your lenses (elegant):
λ> set (address . city) "NYC" person
Person { _name = "Alice", _address = Address { _city = "NYC", _street = "123 Main" }}
λ> view (address . city) person
"NYC"
λ> over (address . city) toUpper person
Person { _name = "Alice", _address = Address { _city = "NYC", _street = "123 Main" }}
-- Traversals (update multiple):
λ> over (employees . traverse . salary) (*1.1) company
-- Gives everyone a 10% raise!
-- Prisms (for sum types):
λ> preview _Left (Left 5)
Just 5
λ> preview _Left (Right "hello")
Nothing
Implementation Hints
Pseudo-Haskell:
-- Simple lens (getter + setter)
data Lens' s a = Lens'
{ view :: s -> a
, set :: a -> s -> s
}
-- Compose lenses
(.) :: Lens' a b -> Lens' b c -> Lens' a c
(Lens' viewAB setAB) . (Lens' viewBC setBC) = Lens'
{ view = viewBC . viewAB
, set = \c a -> setAB (setBC c (viewAB a)) a
}
-- The magic: Van Laarhoven representation
-- A lens is a function that, given a way to "focus" on the inner value,
-- produces a way to "focus" on the outer value
type Lens s t a b = forall f. Functor f => (a -> f b) -> s -> f t
type Lens' s a = Lens s s a a
-- Building a lens
lens :: (s -> a) -> (s -> b -> t) -> Lens s t a b
lens getter setter = \f s -> setter s <$> f (getter s)
-- Using a lens to get
view :: Lens' s a -> s -> a
view l s = getConst (l Const s)
-- Using a lens to set
set :: Lens' s a -> a -> s -> s
set l a s = runIdentity (l (\_ -> Identity a) s)
-- Using a lens to modify
over :: Lens' s a -> (a -> a) -> s -> s
over l f s = runIdentity (l (Identity . f) s)
-- Composition is just function composition!
-- (l1 . l2) automatically works because of the type signature
-- Traversals: focus on multiple values
type Traversal s t a b = forall f. Applicative f => (a -> f b) -> s -> f t
-- Traverse over a list
traverse :: Traversal [a] [b] a b
traverse f = sequenceA . map f
-- Prisms: for sum types (partial access)
type Prism s t a b = forall p f. (Choice p, Applicative f) => p a (f b) -> p s (f t)
_Left :: Prism (Either a c) (Either b c) a b
_Right :: Prism (Either c a) (Either c b) a b
Learning milestones
- Simple lenses work → You understand getter/setter fusion
- Lens composition works → You understand composability
- Traversals work → You understand multiple targets
- Prisms work → You understand partial access
Real World Outcome
When you run your lens library, you’ll experience the transformative power of composable accessors for nested data structures. Here’s exactly what you’ll see:
-- Start your GHCi REPL with your library loaded:
$ ghci LensLibrary.hs
GHCi, version 9.4.7: https://www.haskell.org/ghc/ :? for help
-- Define deeply nested data:
λ> data Person = Person { _name :: String, _address :: Address } deriving (Show)
λ> data Address = Address { _city :: String, _street :: Street } deriving (Show)
λ> data Street = Street { _number :: Int, _name :: String } deriving (Show)
-- Create test data:
λ> let alice = Person "Alice" (Address "NYC" (Street 42 "Main St"))
λ> alice
Person {_name = "Alice", _address = Address {_city = "NYC", _street = Street {_number = 42, _name = "Main St"}}}
-- WITHOUT LENSES (the old painful way):
λ> alice { _address = (_address alice) { _street = (_street (_address alice)) { _number = 100 }}}
Person {_name = "Alice", _address = Address {_city = "NYC", _street = Street {_number = 100, _name = "Main St"}}}
-- Deeply nested, hard to read, error-prone!
-- WITH YOUR LENSES (elegant composition):
λ> import Control.Lens
λ> set (address . street . number) 100 alice
Person {_name = "Alice", _address = Address {_city = "NYC", _street = Street {_number = 100, _name = "Main St"}}}
-- Beautiful! Reads like: "set the street number in the address to 100"
-- View (get) values deep in structures:
λ> view (address . city) alice
"NYC"
λ> view (address . street . number) alice
42
-- Modify (over) values with a function:
λ> over (address . city) (map toUpper) alice
Person {_name = "Alice", _address = Address {_city = "NYC", _street = Street {_number = 42, _name = "Main St"}}}
λ> over (address . street . number) (*2) alice
Person {_name = "Alice", _address = Address {_city = "NYC", _street = Street {_number = 84, _name = "Main St"}}}
-- TRAVERSALS - operate on multiple values at once:
λ> data Company = Company { _employees :: [Person] } deriving Show
λ> let company = Company [alice, Person "Bob" (Address "SF" (Street 10 "Oak"))]
λ> over (employees . traverse . address . city) (map toUpper) company
Company {_employees = [Person {_name = "Alice", _address = Address {_city = "NYC", ...}},
Person {_name = "Bob", _address = Address {_city = "SF", ...}}]}
-- Changed EVERY employee's city to uppercase in one elegant expression!
-- PRISMS - work with sum types (Either, Maybe):
λ> preview _Just (Just 42)
Just 42
λ> preview _Just Nothing
Nothing
λ> preview _Left (Left "error")
Just "error"
λ> preview _Left (Right 100)
Nothing
-- Practical example: safely extract from Maybe
λ> set _Just 100 (Just 42)
Just 100
λ> set _Just 100 Nothing
Nothing
-- Prism respects the structure!
-- FOLDING with lenses:
λ> toListOf (employees . traverse . address . city) company
["NYC","SF"]
-- Extract all cities from all employees!
-- MULTIPLE UPDATES:
λ> let complexData = Company [
Person "Alice" (Address "NYC" (Street 42 "Main")),
Person "Bob" (Address "SF" (Street 10 "Oak")),
Person "Carol" (Address "LA" (Street 7 "Elm"))
]
λ> over (employees . traverse . address . street . number) (+100) complexData
Company {_employees = [
Person {_name = "Alice", _address = Address {_city = "NYC", _street = Street {_number = 142, ...}}},
Person {_name = "Bob", _address = Address {_city = "SF", _street = Street {_number = 110, ...}}},
Person {_name = "Carol", _address = Address {_city = "LA", _street = Street {_number = 107, ...}}}]}
-- Added 100 to EVERY street number in the company!
What you’re experiencing:
- Composability: Lenses compose with
.just like functions - Type safety: The compiler ensures you’re accessing valid fields
- Elegance: What took 3 lines of nested record updates now takes 1 line
- Power: Traversals let you update multiple values simultaneously
- Flexibility: Same lens works for viewing, setting, and modifying
This is why lenses are ubiquitous in production Haskell code. You’ll never want to go back to manual nested record updates!
The Core Question You’re Answering
“How do you elegantly access and update deeply nested immutable data structures without mutation or boilerplate?”
In imperative programming, updating nested data is trivial: person.address.city = "NYC". But in pure functional programming, data is immutable. You need to create a new structure with the changed value, which leads to nightmarish code like:
person { address = (address person) { city = (city (address person)) { name = "NYC" }}}
Lenses answer a deeper question: Can we make nested immutable updates as easy as mutable updates? The answer is yes, through the power of composable accessors.
But there’s an even deeper question: What if accessors were first-class values that compose? This leads to the Van Laarhoven representation, where a lens is not a pair of getter/setter, but a higher-order function that abstracts over different “actions” (getting, setting, modifying, folding).
By building this library, you’re answering:
- How can getters and setters fuse into a single composable value?
- How can the same abstraction work for single values (Lens), optional values (Prism), and multiple values (Traversal)?
- How does this connect to profunctors and category theory?
Concepts You Must Understand First
Stop and research these before coding:
- Immutable Data Updates in Haskell
- How do record updates work in Haskell? (
person { field = newValue }) - Why is
person { address { city = "NYC" }}not valid syntax? - What’s the relationship between purity and immutability?
- Book Reference: “Learn You a Haskell for Great Good!” Chapter 8 - Miran Lipovaca
- How do record updates work in Haskell? (
- First-Class Functions and Composition
- What does it mean for a function to be “first-class”?
- How does function composition
(.)work at the type level? - Why is
(f . g) x = f (g x)? - Book Reference: “Haskell Programming from First Principles” Chapter 7 - Christopher Allen and Julie Moronuki
- Higher-Order Functions
- What is a function that takes a function as argument?
- What is a function that returns a function?
- How do combinators like
map,filter,foldrelate? - Book Reference: “Learn You a Haskell for Great Good!” Chapter 6 - Miran Lipovaca
- The Functor Type Class
- What does
fmap :: (a -> b) -> f a -> f breally mean? - What are the functor laws?
- How is
Consta functor? How isIdentitya functor? - Book Reference: “Haskell Programming from First Principles” Chapter 16 - Christopher Allen and Julie Moronuki
- What does
- Existential Quantification (forall)
- What does
forall f. Functor f => ...mean? - Why is
forallcalled “universal quantification”? - How does rank-2 polymorphism work?
- Book Reference: “Optics By Example” Chapter 2 - Chris Penner
- What does
- Product and Sum Types
- What’s the difference between a product type (record) and sum type (Either)?
- How do you access fields in a product?
- How do you pattern match on a sum?
- Book Reference: “Haskell Programming from First Principles” Chapter 11 - Christopher Allen and Julie Moronuki
- Getters and Setters as First-Class Values
- Can you pass a “getter” as a value?
- Can you compose getters?
getCity . getAddress? - How do you represent “set the city in the address”?
- Book Reference: “Optics By Example” Chapter 1 - Chris Penner
Questions to Guide Your Design
Before implementing, think through these:
- Simple Lens Representation
- If a lens has a getter and a setter, what’s the type signature?
data Lens s a = Lens { view :: s -> a, set :: a -> s -> s }— does this work?- How do you compose two such lenses? What’s
lens1 . lens2? - Can you write
composeLens :: Lens a b -> Lens b c -> Lens a c?
- The Van Laarhoven Encoding
- Instead of storing getter/setter separately, what if a lens is a function?
type Lens s t a b = forall f. Functor f => (a -> f b) -> s -> f t- What does this type signature mean? “Given a way to focus on
a(producingf b), produce a way to focus ons(producingf t)” - Why does this automatically compose with
(.)?
- Using Different Functors for Different Operations
- To get a value: what functor captures “just return the value”? (
Const a) - To set a value: what functor captures “replace with a new value”? (
Identity) - To modify a value: what functor captures “apply a function”? (
Identityagain) - How does the same lens type work for all three operations?
- To get a value: what functor captures “just return the value”? (
- Traversals - Multiple Targets
- A Lens focuses on one value. What if you want to focus on many?
type Traversal s t a b = forall f. Applicative f => (a -> f b) -> s -> f t- Why
Applicativeinstead of justFunctor? - How does
traverseover a list fit this type?
- Prisms - Partial Access
- How do you focus on a value that might not exist?
- For
Either a b, how do you focus on thea(only if it’sLeft)? - What’s the type of a Prism? (Hint: involves
Choiceprofunctor) - Why can’t you always “set” through a prism?
Thinking Exercise
Build a Mental Model of Lens Composition
Before coding, trace this by hand:
-- Given:
data Person = Person { _address :: Address }
data Address = Address { _city :: String }
let alice = Person (Address "NYC")
-- Define simple lenses:
address :: Lens' Person Address
address = lens _address (\person newAddr -> person { _address = newAddr })
city :: Lens' Address String
city = lens _city (\addr newCity -> addr { _city = newCity })
-- Compose them:
addressCity :: Lens' Person String
addressCity = address . city
-- Now trace: view addressCity alice
-- Step by step:
-- 1. addressCity = address . city
-- 2. view (address . city) alice
-- 3. Expand composition: view city (view address alice)
-- 4. view address alice = _address alice = Address "NYC"
-- 5. view city (Address "NYC") = _city (Address "NYC") = "NYC"
-- Result: "NYC"
-- Trace: set addressCity "SF" alice
-- Step by step:
-- 1. set (address . city) "SF" alice
-- 2. set address (set city "SF" (view address alice)) alice
-- 3. view address alice = Address "NYC"
-- 4. set city "SF" (Address "NYC") = Address "SF"
-- 5. set address (Address "SF") alice = alice { _address = Address "SF" }
-- Result: Person (Address "SF")
Questions while tracing:
- At what point does the composition happen?
- How many times do you “dive into” the address?
- Draw a diagram showing the flow of data through the composed lens
- Why does this feel like function composition?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is a lens and why would you use one?”
- Answer: A composable accessor for nested data. In pure FP, updating nested structures without mutation is painful. Lenses make it elegant.
- “How do lenses compose? Why is it better than manual composition?”
- Answer: Lenses compose with
(.)because of the Van Laarhoven encoding. Manual composition requires writing boilerplate for each nesting level.
- Answer: Lenses compose with
- “What’s the difference between a Lens, a Prism, and a Traversal?”
- Answer: Lens focuses on one mandatory value. Prism focuses on one optional value (sum types). Traversal focuses on zero-or-more values.
- “Explain the type signature:
type Lens s t a b = forall f. Functor f => (a -> f b) -> s -> f t“- Answer: It’s a rank-2 polymorphic function. Given a way to focus on the small thing (
a), it produces a way to focus on the big thing (s). The functorfdetermines what “focus” means (get, set, modify).
- Answer: It’s a rank-2 polymorphic function. Given a way to focus on the small thing (
- “Why do Traversals require Applicative instead of just Functor?”
- Answer: Because traversals work with multiple values. Applicative allows combining effects (
<*>), which is necessary when you’re updating multiple targets.
- Answer: Because traversals work with multiple values. Applicative allows combining effects (
- “How would you implement
over(modify through a lens)?”- Answer:
over l f s = runIdentity (l (Identity . f) s). UseIdentityfunctor and apply the functionfat the focus point.
- Answer:
- “What real-world problems do lenses solve?”
- Answer: Updating deeply nested JSON in web APIs, modifying game state (player in level in world), updating configuration structures, working with databases/ORMs.
Hints in Layers
Hint 1: Start with Simple Lenses (Data Constructor)
Don’t jump to Van Laarhoven encoding immediately. Start simple:
data Lens' s a = Lens'
{ view :: s -> a
, set :: a -> s -> s
}
-- Create a lens for a record field:
nameLens :: Lens' Person String
nameLens = Lens'
{ view = \(Person name _) -> name
, set = \newName (Person _ addr) -> Person newName addr
}
-- Use it:
view nameLens alice -- gets name
set nameLens "Bob" alice -- sets name
Hint 2: Implement over using view and set
over :: Lens' s a -> (a -> a) -> s -> s
over l f s = set l (f (view l s)) s
-- Example:
over nameLens (map toUpper) alice
-- Gets the name, applies toUpper to it, sets it back
Hint 3: Try to Compose Simple Lenses
composeLens :: Lens' a b -> Lens' b c -> Lens' a c
composeLens (Lens' viewAB setAB) (Lens' viewBC setBC) = Lens'
{ view = \a -> viewBC (viewAB a)
, set = \c a -> setAB (setBC c (viewAB a)) a
}
This works, but notice the complexity! This motivates the Van Laarhoven encoding.
Hint 4: Understand Van Laarhoven Encoding
The key insight: a lens is a way to apply a functor-wrapped function to a focused part.
type Lens s t a b = forall f. Functor f => (a -> f b) -> s -> f t
type Lens' s a = Lens s s a a -- simple version
-- Build a lens:
lens :: (s -> a) -> (s -> b -> t) -> Lens s t a b
lens getter setter = \f s -> setter s <$> f (getter s)
-- ^^^^^^^^^^^^^^^^
-- Apply f to the focused value (getter s)
-- Then use setter to rebuild the structure
-- Use it to view:
view :: Lens' s a -> s -> a
view l s = getConst (l Const s)
-- ^^^^^^
-- l expects: a -> f a
-- Const :: a -> Const a b
-- Result: Const a, extract with getConst
-- Use it to set:
set :: Lens' s a -> a -> s -> s
set l newVal s = runIdentity (l (\_ -> Identity newVal) s)
-- ^^^^^^^^^^^^^^^^^^^^^^
-- Ignore old value, return new value wrapped in Identity
-- Use it to modify:
over :: Lens' s a -> (a -> a) -> s -> s
over l f s = runIdentity (l (Identity . f) s)
-- ^^^^^^^^^^^^^^^^
-- Apply f and wrap result in Identity
Hint 5: Implement Traversals
A traversal is just a lens that allows multiple focuses:
type Traversal s t a b = forall f. Applicative f => (a -> f b) -> s -> f t
-- Traverse a list:
traverseList :: Traversal [a] [b] a b
traverseList f [] = pure []
traverseList f (x:xs) = (:) <$> f x <*> traverseList f xs
-- ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-- Applicative allows combining multiple effects
-- Use it:
toListOf :: Traversal s t a b -> s -> [a]
toListOf t s = getConst (t (\a -> Const [a]) s)
Hint 6: Implement Prisms
A prism is for sum types (optional values):
-- Simplified prism:
data Prism' s a = Prism'
{ preview :: s -> Maybe a -- might not exist
, review :: a -> s -- always can construct
}
_Just :: Prism' (Maybe a) a
_Just = Prism'
{ preview = id -- Maybe a -> Maybe a
, review = Just -- a -> Maybe a
}
_Left :: Prism' (Either a b) a
_Left = Prism'
{ preview = either Just (const Nothing)
, review = Left
}
Hint 7: Use lens Library’s Types for Reference
Once you understand the basics, look at the real lens library:
$ ghci
λ> :i Lens
type Lens s t a b = forall f. Functor f => (a -> f b) -> s -> f t
λ> :i Traversal
type Traversal s t a b = forall f. Applicative f => (a -> f b) -> s -> f t
λ> :i Prism
type Prism s t a b = forall p f. (Choice p, Applicative f) => p a (f b) -> p s (f t)
Study the difference in constraints. Each adds power at the cost of generality.
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| What lenses are and why they matter | “Optics By Example” | Ch. 1-3 |
| Van Laarhoven encoding | “Optics By Example” | Ch. 4 |
| Composing lenses | “Optics By Example” | Ch. 5 |
| Traversals and multiple focuses | “Optics By Example” | Ch. 6 |
| Prisms for sum types | “Optics By Example” | Ch. 8 |
| Isos and other optics | “Optics By Example” | Ch. 9-10 |
| Functor and Applicative (prerequisites) | “Haskell Programming from First Principles” | Ch. 16-17 |
| Higher-order functions | “Learn You a Haskell for Great Good!” | Ch. 6 |
| Advanced type features (Rank-N types) | “Thinking with Types” by Sandy Maguire | Ch. 6 |
| Profunctor optics (advanced) | “Profunctor Optics: Modular Data Accessors” (paper) | Full paper |
| Real-world lens usage | “Haskell in Depth” | Ch. 7.3 |
Project 12: Free Monad DSL
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: Scala, PureScript
- Coolness Level: Level 5: Pure Magic (Super Cool)
- Business Potential: 4. The “Open Core” Infrastructure
- Difficulty: Level 5: Master
- Knowledge Area: DSLs / Free Structures
- Software or Tool: Free Monad Interpreter
- Main Book: “Haskell in Depth” by Vitaly Bragilevsky
What you’ll build
Create a domain-specific language (DSL) using free monads. Define an algebra of operations, build programs in the DSL, and write multiple interpreters (production, testing, logging).
Why it teaches Functional Programming
Free monads separate what a program does from how it’s executed. This is the ultimate expression of declarative programming: describe the computation abstractly, then interpret it however you want.
Core challenges you’ll face
- Free monad construction (lifting an algebra into a monad) → maps to free structures
- Smart constructors (ergonomic DSL syntax) → maps to embedded DSLs
- Interpreters (different semantics for same program) → maps to interpretation
- Effect composition (combining multiple DSLs) → maps to effect systems
Key Concepts
- Free Monads: “Haskell in Depth” Chapter 11 - Bragilevsky
- Why Free Monads Matter: Paper by Gabriel Gonzalez
- Data Types à la Carte: Composing DSLs
Difficulty
Master
Time estimate
2-3 weeks
Prerequisites
Projects 6 & 9
Real world outcome
-- Define a DSL for a key-value store:
data KVStoreF k v next
= Get k (Maybe v -> next)
| Put k v next
| Delete k next
type KVStore k v = Free (KVStoreF k v)
-- Write programs in the DSL:
program :: KVStore String Int Int
program = do
put "x" 1
put "y" 2
x <- get "x"
y <- get "y"
return $ fromMaybe 0 x + fromMaybe 0 y
-- Interpreter 1: In-memory Map
runInMemory :: KVStore String Int a -> State (Map String Int) a
-- Interpreter 2: Logging
runWithLogging :: KVStore String Int a -> IO a
-- Interpreter 3: Testing (mock)
runMock :: [(String, Int)] -> KVStore String Int a -> a
λ> evalState (runInMemory program) Map.empty
3
λ> runWithLogging program
[LOG] PUT "x" = 1
[LOG] PUT "y" = 2
[LOG] GET "x" -> Just 1
[LOG] GET "y" -> Just 2
3
λ> runMock [("x", 10), ("y", 20)] program
30
Implementation Hints
Pseudo-Haskell:
-- Free monad: "free" data structure that forms a monad
data Free f a
= Pure a
| Free (f (Free f a))
instance Functor f => Functor (Free f) where
fmap f (Pure a) = Pure (f a)
fmap f (Free fa) = Free (fmap (fmap f) fa)
instance Functor f => Applicative (Free f) where
pure = Pure
Pure f <*> a = fmap f a
Free ff <*> a = Free (fmap (<*> a) ff)
instance Functor f => Monad (Free f) where
Pure a >>= f = f a
Free fa >>= f = Free (fmap (>>= f) fa)
-- Lift a functor value into Free
liftF :: Functor f => f a -> Free f a
liftF fa = Free (fmap Pure fa)
-- Our DSL functor
data KVStoreF k v next
= Get k (Maybe v -> next)
| Put k v next
| Delete k next
deriving Functor
type KVStore k v = Free (KVStoreF k v)
-- Smart constructors (ergonomic API)
get :: k -> KVStore k v (Maybe v)
get k = liftF (Get k id)
put :: k -> v -> KVStore k v ()
put k v = liftF (Put k v ())
delete :: k -> KVStore k v ()
delete k = liftF (Delete k ())
-- Interpreter: fold the free monad
interpret :: Monad m => (forall x. f x -> m x) -> Free f a -> m a
interpret _ (Pure a) = return a
interpret handler (Free fa) = do
next <- handler fa
interpret handler next
-- In-memory interpreter
runInMemory :: KVStore String Int a -> State (Map String Int) a
runInMemory = interpret handler
where
handler :: KVStoreF String Int x -> State (Map String Int) x
handler (Get k cont) = do
m <- get
return (cont (Map.lookup k m))
handler (Put k v next) = do
modify (Map.insert k v)
return next
handler (Delete k next) = do
modify (Map.delete k)
return next
Learning milestones
- Free monad is a monad → You understand free structures
- DSL programs compose → You understand embedded DSLs
- Multiple interpreters work → You understand separation of concerns
- Testing is trivial → You understand practical benefits
Real World Outcome
When you complete this project, you’ll have built a domain-specific language (DSL) where programs are pure data structures, completely separate from their execution. Here’s what you’ll see in action:
-- Load your Free Monad DSL library:
$ ghci FreeDSL.hs
GHCi, version 9.4.7: https://www.haskell.org/ghc/ :? for help
-- Your DSL algebra - operations as data:
λ> :t get
get :: k -> KVStore k v (Maybe v)
λ> :t put
put :: k -> v -> KVStore k v ()
λ> :t delete
delete :: k -> KVStore k v ()
-- Write a program in your DSL (it's just data, not executed yet!):
λ> let program1 = do
put "name" "Alice"
put "age" 30
name <- get "name"
age <- get "age"
return (name, age)
λ> :t program1
program1 :: KVStore String Int (Maybe String, Maybe Int)
-- It's just a value! Not executed yet.
-- INTERPRETER 1: Pure in-memory (using State monad)
λ> import qualified Data.Map as Map
λ> import Control.Monad.State
λ> runPure program1
(Just "Alice", Just 30)
-- Executed in pure State monad, no IO!
-- INTERPRETER 2: With logging (see what happens)
λ> runWithLogging program1
[LOG] PUT "name" = "Alice"
[LOG] PUT "age" = 30
[LOG] GET "name" -> Just "Alice"
[LOG] GET "age" -> Just 30
Result: (Just "Alice", Just 30)
-- INTERPRETER 3: Mock/Test interpreter
λ> let mockData = Map.fromList [("name", "Bob"), ("age", 25)]
λ> runMock mockData program1
(Just "Bob", Just 25)
-- Same program, different data source!
-- INTERPRETER 4: Real Redis (IO)
λ> runRedis program1
Connecting to Redis at localhost:6379...
SET name "Alice"
SET age 30
GET name -> "Alice"
GET age -> 30
Result: (Just "Alice", Just 30)
-- The POWER: Same program, 4 different interpreters!
-- More complex program - business logic:
λ> :{
let transferMoney = do
balanceA <- get "account_A"
balanceB <- get "account_B"
case (balanceA, balanceB) of
(Just a, Just b) | a >= 100 -> do
put "account_A" (a - 100)
put "account_B" (b + 100)
return (Just "Transfer successful")
_ -> return Nothing
:}
-- Test with mock data (no database needed!):
λ> let testAccounts = Map.fromList [("account_A", 500), ("account_B", 200)]
λ> runMock testAccounts transferMoney
Just "Transfer successful"
λ> let poorAccounts = Map.fromList [("account_A", 50), ("account_B", 200)]
λ> runMock poorAccounts transferMoney
Nothing
-- Business logic tested without touching a database!
-- Production with logging:
λ> runWithLogging transferMoney
[LOG] GET "account_A" -> Just 500
[LOG] GET "account_B" -> Just 200
[LOG] PUT "account_A" = 400
[LOG] PUT "account_B" = 300
Result: Just "Transfer successful"
-- Compose multiple DSL programs:
λ> :{
let workflow = do
put "step" 1
transferMoney
put "step" 2
get "step"
:}
λ> runPure workflow
Just 2
-- EFFECT COMPOSITION - multiple DSLs together:
-- Define logging DSL:
data LogF next = Log String next deriving Functor
type Logging = Free LogF
-- Combine with KVStore:
λ> :{
let combined = do
liftKV $ put "user" "Alice"
liftLog $ log "User created"
user <- liftKV $ get "user"
liftLog $ log ("Retrieved: " ++ show user)
return user
:}
-- Interpret both effects:
λ> runCombined combined
[LOG] User created
[KV] PUT "user" = "Alice"
[KV] GET "user" -> Just "Alice"
[LOG] Retrieved: Just "Alice"
Result: Just "Alice"
What you’re witnessing:
-
Separation of Description from Execution: Your DSL program is pure data. No side effects until you choose an interpreter.
- Multiple Interpretations: The same program can be:
- Tested with mock data (pure, fast)
- Run in production with real database (IO)
- Logged for debugging
- Analyzed for optimization
-
Testability: Write tests without databases, file systems, or network calls. Just pure functions.
-
Composability: DSL programs compose with
donotation. Multiple DSLs can be composed together. - Type Safety: The compiler ensures your DSL operations are well-formed.
This is how modern Haskell libraries like Polysemy, Eff, and Fused-Effects work. You’ve built the foundation!
The Core Question You’re Answering
“How do you separate WHAT a program does from HOW it’s executed?”
In most programming, when you write:
user = database.get("user_123")
database.put("user_123", user.updated())
You’ve tangled the logic (get user, update, save) with the execution (actual database calls). This makes testing hard, reasoning hard, and composition hard.
Free monads answer a deeper question: What if we could build programs as pure data structures, then interpret them later?
Think of it like this:
- Imperative: “Go to the store, buy milk, come home” (you execute each step immediately)
- Free Monad: Write down “1. Go to store, 2. Buy milk, 3. Come home” on paper (pure description), then hand the list to different people who execute it differently (one person drives, one walks, one takes a bus)
By building this DSL, you’re answering:
- How can we represent effectful computations as pure data?
- How can the same “program” have multiple interpretations?
- What does it mean for a data type to be “free” over a functor?
- How does this connect to algebraic effect systems?
Concepts You Must Understand First
Stop and research these before coding:
- Monads and Do-Notation
- What does the
>>=(bind) operator do? - How does
donotation desugar? - Why is
Monadmore powerful than justFunctor? - Book Reference: “Haskell Programming from First Principles” Chapter 18 - Christopher Allen and Julie Moronuki
- What does the
- Functors
- What is
fmap :: (a -> b) -> f a -> f b? - What are the functor laws?
- How do you derive
Functorfor custom data types? - Book Reference: “Learn You a Haskell for Great Good!” Chapter 11 - Miran Lipovaca
- What is
- Recursive Data Structures
- How do you define a data type that refers to itself?
- What is
data Tree a = Leaf a | Branch (Tree a) (Tree a)? - How do you fold over recursive structures?
- Book Reference: “Haskell Programming from First Principles” Chapter 11 - Christopher Allen and Julie Moronuki
- Higher-Kinded Types
- What does
f :: * -> *mean? - What’s the difference between
Maybe Int(type) andMaybe(type constructor)? - How do you abstract over type constructors?
- Book Reference: “Haskell in Depth” Chapter 6 - Vitaly Bragilevsky
- What does
- Smart Constructors
- What is a smart constructor?
- How do you hide raw constructors and expose only a safe API?
- Why use
liftF :: Functor f => f a -> Free f a? - Book Reference: “Haskell in Depth” Chapter 11 - Vitaly Bragilevsky
- The State Monad
- What is
State s a? - How does
get,put, andmodifywork? - How do you run stateful computations?
- Book Reference: “Learn You a Haskell for Great Good!” Chapter 13 - Miran Lipovaca
- What is
- What “Free” Means in Mathematics
- What is a “free structure”? (No extra constraints beyond the required laws)
- Free monoid: lists with
[]and++ - Free monad: the “freest” monad over a functor
- Book Reference: “Category Theory for Programmers” by Bartosz Milewski - Chapter on Free Monoids
Questions to Guide Your Design
Before implementing, think through these:
- Representing Operations as Data
- How do you represent “get key” as data, not an actual fetch?
- What’s the type of
data KVStoreF k v next = Get k (Maybe v -> next) | ...? - Why does
Gettake a continuation(Maybe v -> next)? - What does the
nextparameter represent?
- Building the Free Monad
data Free f a = Pure a | Free (f (Free f a))— what does this mean?- Why is
Pure athe base case? - Why is the recursive case
f (Free f a)instead of justf a? - How does this form a monad?
- The Monad Instance
- How do you implement
return :: a -> Free f a? (Hint: usePure) - How do you implement
>>=(bind)? - What happens when you bind
Pure a? When you bindFree fa? - Why do you need
Functor fconstraint?
- How do you implement
- Smart Constructors
- Instead of exposing
Free (Get k id), how do you make it ergonomic? get :: k -> Free (KVStoreF k v) (Maybe v)— how to implement?- Why use
liftF :: Functor f => f a -> Free f a? - What’s the pattern for lifting functor values into Free?
- Instead of exposing
- Interpreters
- How do you “run” a Free monad program?
interpret :: Monad m => (forall x. f x -> m x) -> Free f a -> m a- What is a natural transformation
f x -> m x? - How do you fold the Free structure into a target monad?
- Multiple Interpreters
- How does the same program run in
State,IO, or pure functions? - What stays the same? What changes?
- How do you inject test data into an interpreter?
- How does the same program run in
Thinking Exercise
Trace a Free Monad Program by Hand
Before coding, trace this execution step by step:
-- Simple DSL:
data KVFO k v next
= Get k (Maybe v -> next)
| Put k v next
deriving Functor
type KV k v = Free (KVF k v)
get :: k -> KV k v (Maybe v)
get k = liftF (Get k id)
put :: k -> v -> KV k v ()
put k v = liftF (Put k v ())
-- Program:
program :: KV String Int Int
program = do
put "x" 10
v <- get "x"
return (maybe 0 (*2) v)
-- Trace the structure:
-- Step 1: put "x" 10
-- = liftF (Put "x" 10 ())
-- = Free (Put "x" 10 (Pure ()))
-- Step 2: bind with the rest
-- = Free (Put "x" 10 (Pure ())) >>= (\() -> get "x" >>= ...)
-- = Free (fmap (>>= ...) (Put "x" 10 (Pure ())))
-- = Free (Put "x" 10 (Pure () >>= ...))
-- = Free (Put "x" 10 (get "x" >>= ...))
-- Step 3: get "x"
-- = liftF (Get "x" id)
-- = Free (Get "x" (Pure . id))
-- = Free (Get "x" Pure)
-- Final structure:
-- Free (Put "x" 10 (Free (Get "x" (\v -> Pure (maybe 0 (*2) v)))))
-- Now interpret with State monad:
-- interpret handler (Free (Put "x" 10 next)) = do
-- handler (Put "x" 10 next) -- calls State's put
-- interpret handler next -- continues
-- interpret handler (Free (Get "x" cont)) = do
-- v <- handler (Get "x" cont) -- calls State's get
-- interpret handler (cont v) -- continues with result
-- interpret handler (Pure a) = return a -- base case
Questions while tracing:
- Draw the tree structure of the Free monad
- Where is the actual computation happening? (Nowhere! It’s just data)
- What happens when you swap the interpreter?
- How does the continuation threading work?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is a Free Monad?”
- Answer: A data structure that gives you a monad for free, given just a functor. It represents computations as a tree of operations, separating description from execution.
- “Why use Free Monads instead of just using IO or State directly?”
- Answer: Separation of concerns. Your business logic becomes pure data, easily testable. Same program can have multiple interpretations (production, testing, logging).
- “What does ‘Free’ mean in Free Monad?”
- Answer: It’s the “freest” monad over a functor—it adds no extra constraints beyond the monad laws. Like how lists are the free monoid.
- “How do Free Monads help with testing?”
- Answer: You can write pure interpreters with mock data. No need for databases, file systems, or network calls in tests.
- “What’s the performance cost of Free Monads?”
- Answer: Building the tree structure has overhead. Modern approaches (Freer, Eff, Polysemy) optimize this with type-aligned sequences.
- “What’s the difference between Free Monad and MTL-style type classes?”
- Answer: MTL uses type classes (like
MonadState,MonadReader). Free monads use data structures. MTL is faster but less flexible; Free is slower but more explicit.
- Answer: MTL uses type classes (like
- “Can you compose multiple DSLs with Free Monads?”
- Answer: Yes! Using coproducts of functors (Data Types à la Carte). Or use Freer monads which make composition easier.
Hints in Layers
Hint 1: Start with the Functor
Your DSL operations must form a functor:
data KVStoreF k v next
= Get k (Maybe v -> next)
| Put k v next
| Delete k next
deriving Functor -- GHC can derive this!
-- Manual functor instance:
instance Functor (KVStoreF k v) where
fmap f (Get k cont) = Get k (f . cont)
fmap f (Put k v next) = Put k v (f next)
fmap f (Delete k next) = Delete k (f next)
Notice the pattern: fmap applies f to the next continuation.
Hint 2: Build the Free Monad Type
data Free f a
= Pure a -- Base case: done
| Free (f (Free f a)) -- Recursive: one operation, then more
-- Example value:
exampleFree :: Free (KVStoreF String Int) Int
exampleFree = Free (Put "x" 10 (Free (Get "x" (\v -> Pure (maybe 0 id v)))))
Hint 3: Implement the Monad Instance
instance Functor f => Functor (Free f) where
fmap f (Pure a) = Pure (f a)
fmap f (Free fa) = Free (fmap (fmap f) fa)
-- ^^^^^ functor of f
-- ^^^^^ functor of Free f
instance Functor f => Applicative (Free f) where
pure = Pure
Pure f <*> a = fmap f a
Free ff <*> a = Free (fmap (<*> a) ff)
instance Functor f => Monad (Free f) where
return = Pure
Pure a >>= f = f a
Free fa >>= f = Free (fmap (>>= f) fa)
-- ^^^^^^^^^^^
-- Push the bind inside the functor
Hint 4: Create Smart Constructors
liftF :: Functor f => f a -> Free f a
liftF fa = Free (fmap Pure fa)
-- ^^^^^^^^^^^^
-- Wrap each result in Pure
-- DSL operations:
get :: k -> Free (KVStoreF k v) (Maybe v)
get k = liftF (Get k id)
-- ^^
-- id is the continuation
put :: k -> v -> Free (KVStoreF k v) ()
put k v = liftF (Put k v ())
-- ^^
-- unit value as placeholder
delete :: k -> Free (KVStoreF k v) ()
delete k = liftF (Delete k ())
Hint 5: Write an Interpreter
An interpreter folds the Free structure:
interpret :: Monad m => (forall x. f x -> m x) -> Free f a -> m a
interpret _ (Pure a) = return a
interpret handler (Free fa) = do
a <- handler fa -- Handle this layer
interpret handler a -- Continue with the rest
-- In-memory interpreter using State:
runInMemory :: Free (KVStoreF k v) a -> State (Map k v) a
runInMemory = interpret handler
where
handler :: KVStoreF k v x -> State (Map k v) x
handler (Get k cont) = do
m <- get
return (cont (Map.lookup k m))
handler (Put k v next) = do
modify (Map.insert k v)
return next
handler (Delete k next) = do
modify (Map.delete k)
return next
Hint 6: Add Logging Interpreter
runWithLogging :: (Show k, Show v) => Free (KVStoreF k v) a -> IO a
runWithLogging = interpret handler
where
handler :: KVStoreF k v x -> IO x
handler (Get k cont) = do
putStrLn $ "[LOG] GET " ++ show k
return (cont Nothing) -- Mock return
handler (Put k v next) = do
putStrLn $ "[LOG] PUT " ++ show k ++ " = " ++ show v
return next
handler (Delete k next) = do
putStrLn $ "[LOG] DELETE " ++ show k
return next
Hint 7: Testing with Pure Interpreter
runMock :: Ord k => Map k v -> Free (KVStoreF k v) a -> a
runMock initialData program =
evalState (runInMemory program) initialData
-- Usage:
testData = Map.fromList [("user", "Alice"), ("age", 30)]
result = runMock testData myProgram
-- No IO! Pure testing!
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Free monads conceptually | “Haskell in Depth” | Ch. 11 |
| Monad fundamentals | “Haskell Programming from First Principles” | Ch. 18 |
| Why free monads matter | “Why Free Monads Matter” (paper) by Gabriel Gonzalez | Full paper |
| Data types à la carte (composing DSLs) | “Data Types à la Carte” (paper) by Wouter Swierstra | Full paper |
| Free structures in category theory | “Category Theory for Programmers” | Ch. on Monoids |
| Functor and higher-order types | “Haskell Programming from First Principles” | Ch. 16 |
| State monad for interpreters | “Learn You a Haskell for Great Good!” | Ch. 13 |
| Real-world DSL design | “Domain Specific Languages” by Martin Fowler | Ch. 4-5 |
| Effect systems (next evolution) | “Polysemy documentation” | Online docs |
| Advanced free monad optimization | “Reflection without Remorse” (paper) | Full paper |
| Practical interpreter patterns | “Haskell in Depth” | Ch. 10 |
Project 13: Category Theory Visualizer
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: Scala, Idris
- Coolness Level: Level 5: Pure Magic (Super Cool)
- Business Potential: 2. The “Micro-SaaS / Pro Tool”
- Difficulty: Level 4: Expert
- Knowledge Area: Category Theory / Mathematics
- Software or Tool: Category Visualizer
- Main Book: “Category Theory for Programmers” by Bartosz Milewski
What you’ll build
A tool that visualizes category theory concepts: categories as graphs, functors as graph homomorphisms, natural transformations as arrows between functors, and monads as monoids in the category of endofunctors.
Why it teaches Functional Programming
Category theory is the mathematics behind Haskell’s type class hierarchy. Seeing functors as structure-preserving maps, and natural transformations as polymorphic functions, makes the abstract concrete.
Core challenges you’ll face
- Category representation (objects, morphisms, composition) → maps to types and functions
- Functor visualization (mapping between categories) → maps to Functor type class
- Natural transformations (morphisms between functors) → maps to polymorphic functions
- Monad structure (unit + multiplication satisfying laws) → maps to return + join
Key Concepts
- Categories: “Category Theory for Programmers” Chapters 1-3 - Bartosz Milewski
- Functors: “Category Theory for Programmers” Chapter 7
- Natural Transformations: “Category Theory for Programmers” Chapter 10
- Monads Categorically: Programming with Categories (Draft)
Difficulty
Expert
Time estimate
3-4 weeks
Prerequisites
Projects 6 & 11, mathematical comfort
Real world outcome
╔══════════════════════════════════════════════════════════════════════╗
║ Category Theory Visualizer ║
╠══════════════════════════════════════════════════════════════════════╣
║ ║
║ Category: Hask (Haskell types and functions) ║
║ ║
║ Objects: Int ──── String ──── Bool ──── [a] ──── Maybe a ║
║ ║
║ Morphisms: ║
║ show : Int → String ║
║ length : String → Int ║
║ even : Int → Bool ║
║ ║
║ Composition: length . show : Int → Int ║
║ (Length of string representation of number) ║
║ ║
╠══════════════════════════════════════════════════════════════════════╣
║ ║
║ Functor: Maybe ║
║ ║
║ On Objects: On Morphisms: ║
║ Int ──→ Maybe Int show ──→ fmap show ║
║ String ──→ Maybe String ║
║ ║
║ fmap show (Just 42) = Just "42" ║
║ fmap show Nothing = Nothing ║
║ ║
║ Functor Laws: ║
║ fmap id = id ✓ ║
║ fmap (f . g) = fmap f . fmap g ✓ ║
║ ║
╠══════════════════════════════════════════════════════════════════════╣
║ ║
║ Natural Transformation: safeHead : [] → Maybe ║
║ ║
║ [Int] ────safeHead────→ Maybe Int ║
║ │ │ ║
║ fmap f fmap f ║
║ ↓ ↓ ║
║ [String] ───safeHead────→ Maybe String ║
║ ║
║ Naturality: safeHead . fmap f = fmap f . safeHead ✓ ║
║ ║
╠══════════════════════════════════════════════════════════════════════╣
║ ║
║ Monad: Maybe (as Monoid in Endofunctors) ║
║ ║
║ Unit (return): a → Maybe a ║
║ return 42 = Just 42 ║
║ ║
║ Multiplication (join): Maybe (Maybe a) → Maybe a ║
║ join (Just (Just 42)) = Just 42 ║
║ join (Just Nothing) = Nothing ║
║ join Nothing = Nothing ║
║ ║
║ Monad Laws (Monoid Laws): ║
║ join . return = id (left identity) ✓ ║
║ join . fmap return = id (right identity) ✓ ║
║ join . join = join . fmap join (associativity) ✓ ║
║ ║
╚══════════════════════════════════════════════════════════════════════╝
Implementation Hints
Pseudo-Haskell:
-- A category has objects, morphisms, identity, and composition
data Category obj mor = Category
{ objects :: [obj]
, morphisms :: [(mor, obj, obj)] -- (morphism, source, target)
, identity :: obj -> mor
, compose :: mor -> mor -> Maybe mor
}
-- A functor maps between categories
data Functor' c1 c2 = Functor'
{ objectMap :: obj1 -> obj2
, morphismMap :: mor1 -> mor2
}
-- Verify functor laws
verifyFunctor :: Functor' c1 c2 -> Bool
verifyFunctor f =
-- Identity: F(id_A) = id_{F(A)}
all (\obj -> morphismMap f (identity c1 obj) == identity c2 (objectMap f obj)) (objects c1)
&&
-- Composition: F(g . f) = F(g) . F(f)
all (\(m1, m2) -> morphismMap f (compose c1 m1 m2) == compose c2 (morphismMap f m1) (morphismMap f m2))
[(m1, m2) | m1 <- morphisms c1, m2 <- morphisms c1, composable m1 m2]
-- Natural transformation between functors
data NatTrans f g a = NatTrans { component :: f a -> g a }
-- Verify naturality: η_B . F(f) = G(f) . η_A
verifyNaturality :: (Functor f, Functor g) => NatTrans f g -> (a -> b) -> f a -> Bool
verifyNaturality eta f fa =
component eta (fmap f fa) == fmap f (component eta fa)
-- Monad as monoid in endofunctors
-- Unit: Id → M
-- Multiplication: M ∘ M → M (that's join!)
verifyMonadMonoid :: Monad m => m a -> Bool
verifyMonadMonoid ma =
-- Left identity: join . return = id
join (return ma) == ma
&&
-- Right identity: join . fmap return = id
join (fmap return ma) == ma
&&
-- Associativity: join . join = join . fmap join
-- For m (m (m a)), both paths give m a
Learning milestones
- Categories visualize → You understand objects and morphisms
- Functors preserve structure → You understand Functor
- Natural transformations are polymorphic functions → You understand parametricity
- Monads are monoids → You understand the deep structure
Real World Outcome
When you complete this project, you’ll have a visual tool that transforms abstract category theory into concrete, observable structures. Here’s what you’ll see:
$ ./category-viz
╔══════════════════════════════════════════════════════════════════════╗
║ Category Theory Visualizer v1.0 ║
║ Making the Abstract Concrete ║
╚══════════════════════════════════════════════════════════════════════╝
> show category Hask
Category: Hask (Haskell types and functions)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Objects (Types):
• Int
• String
• Bool
• [a] (lists)
• Maybe a (optional values)
• Either a b (sum types)
Sample Morphisms (Functions):
show : Int → String
length : String → Int
even : Int → Bool
not : Bool → Bool
id : a → a (identity for all types)
Composition Examples:
┌─────────────────────────────────────┐
│ length . show : Int → Int │
│ │
│ Int ──show──→ String ──length──→ Int│
│ │
│ Example: (length . show) 12345 = 5 │
└─────────────────────────────────────┘
Identity Law (verified):
✓ id . show = show
✓ show . id = show
Associativity Law (verified):
✓ (f . g) . h = f . (g . h)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
> visualize functor Maybe
Functor: Maybe
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Maps between categories: Hask → Hask
Object Mapping:
Int ──→ Maybe Int
String ──→ Maybe String
Bool ──→ Maybe Bool
a ──→ Maybe a
Morphism Mapping (fmap):
show : Int → String
↓
fmap show : Maybe Int → Maybe String
Visual Diagram:
┌──────────────────────────────────────────┐
│ Source Category (Hask) │
│ │
│ Int ────────show────────→ String │
│ │
└──────────────────────────────────────────┘
│
fmap
↓
┌──────────────────────────────────────────┐
│ Target Category (Hask) │
│ │
│ Maybe Int ──fmap show──→ Maybe String │
│ │
└──────────────────────────────────────────┘
Examples in Action:
λ> fmap show (Just 42)
Just "42"
λ> fmap show Nothing
Nothing
Functor Laws (verified):
Identity: fmap id = id
✓ fmap id (Just 5) = Just 5
✓ fmap id Nothing = Nothing
Composition: fmap (f . g) = fmap f . fmap g
✓ fmap (length . show) (Just 42) = 2
✓ (fmap length . fmap show) (Just 42) = 2
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
> visualize natural-transformation listToMaybe
Natural Transformation: listToMaybe
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Between functors: [] → Maybe
Type signature: [a] → Maybe a
What it does: Takes the first element of a list, if it exists
Naturality Square:
┌──────────────────────────────────────────┐
│ │
│ [Int] ────listToMaybe────→ Maybe Int
│ │ │
│ fmap show fmap show
│ ↓ ↓
│ [String] ──listToMaybe────→ Maybe String
│ │
└──────────────────────────────────────────┘
Naturality Condition:
listToMaybe . fmap f = fmap f . listToMaybe
Verification:
Left path: listToMaybe (fmap show [1,2,3])
= listToMaybe ["1","2","3"]
= Just "1"
Right path: fmap show (listToMaybe [1,2,3])
= fmap show (Just 1)
= Just "1"
✓ Both paths give the same result!
More examples:
λ> listToMaybe [1,2,3]
Just 1
λ> listToMaybe []
Nothing
λ> listToMaybe ["hello", "world"]
Just "hello"
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
> visualize monad Maybe
Monad: Maybe (as Monoid in the Category of Endofunctors)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Endofunctor: Maybe : Hask → Hask
Monad Structure:
1. Unit (η): return : a → Maybe a
2. Multiplication (μ): join : Maybe (Maybe a) → Maybe a
Unit (return):
return 42 = Just 42
return x = Just x (wraps value in Maybe context)
Multiplication (join):
join (Just (Just 42)) = Just 42
join (Just Nothing) = Nothing
join Nothing = Nothing
(Flattens nested Maybes)
Monad Laws (Monoid Laws in Endofunctors):
1. Left Identity: join . return = id
┌────────────────────────────────┐
│ Maybe a ──return──→ Maybe (Maybe a) │
│ │ │ │
│ └────────join────────┘ │
│ ↓ │
│ Maybe a │
└────────────────────────────────┘
Example: join (return (Just 5)) = Just 5 ✓
2. Right Identity: join . fmap return = id
Example: join (fmap return (Just 5)) = Just 5 ✓
3. Associativity: join . join = join . fmap join
Example with Maybe (Maybe (Maybe 42)):
join (join x) = join (fmap join x) ✓
Visual Diagram (Monad as Monoid):
┌────────────────────────────────────────────┐
│ Maybe ⊗ Maybe ────μ (join)────→ Maybe │
│ │ │ │
│ │ │ │
│ I ──η (return)──────────────────→Maybe │
│ (Identity) │
└────────────────────────────────────────────┘
Connection to do-notation:
do { x <- ma; mb } desugars to ma >>= (\x -> mb)
which is join (fmap (\x -> mb) ma)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
> compare List Maybe
Comparing Functors: [] vs Maybe
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Both are Functors: Hask → Hask
[] Maybe
── ─────
0 or more values 0 or 1 value
fmap over all elements fmap over the single element
Represents choice Represents optionality
Monoid: ++ and [] Not a monoid (no universal append)
Both are Monads:
[] Maybe
── ─────
return x = [x] return x = Just x
join = concat join flattens nested Maybes
Usage:
List: non-deterministic computation (multiple results)
Maybe: computation that might fail (0 or 1 result)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
> export diagram functor-composition
Exporting diagram...
Saved to: functor-composition.svg
[Generated SVG shows:]
F : C → D G : D → E
────────────────────────
G ∘ F : C → E
Objects: F(a) → G(F(a))
Morphisms: F(f) → G(F(f))
✓ Diagram exported successfully
What you’re experiencing:
- Abstract Made Concrete: Category theory concepts become visible, interactive diagrams
- Law Verification: Automatically check functor laws, monad laws, naturality conditions
- Visual Learning: See how functors map objects and morphisms
- Composition Understanding: Watch how natural transformations compose
- Deep Insight: Understand “monad as monoid in endofunctors” visually
This tool transforms the hardest parts of Haskell (the mathematical foundations) into something you can SEE and INTERACT with!
The Core Question You’re Answering
“What IS the mathematical structure behind Haskell’s type classes?”
When you write fmap, >>=, <*>, you’re not just calling functions—you’re using structures from category theory. But category theory is notoriously abstract. This project answers:
Can we make category theory visual and concrete?
Deeper questions you’re exploring:
- What does it mean for a functor to “preserve structure”?
- How is a natural transformation “a morphism between functors”?
- Why are monads “monoids in the category of endofunctors”?
- How do these abstractions map to real Haskell code?
By visualizing these structures, you’re bridging the gap between mathematical abstraction and practical programming.
Concepts You Must Understand First
Stop and research these before coding:
- Categories - Objects and Morphisms
- What is a category? (Objects, morphisms, composition, identity)
- What is an example category? (Set, types, groups, etc.)
- What are the category laws? (identity, associativity)
- Book Reference: “Category Theory for Programmers” Ch. 1-3 - Bartosz Milewski
- The Hask Category
- What are the objects in Hask? (Haskell types)
- What are the morphisms in Hask? (Functions)
- What is composition in Hask? (
(.)operator) - Book Reference: “Category Theory for Programmers” Ch. 1 - Bartosz Milewski
- Functors - Structure-Preserving Maps
- What does a functor map? (Objects → objects, morphisms → morphisms)
- What must a functor preserve? (Identity, composition)
- How does this relate to Haskell’s
Functortypeclass? - Book Reference: “Category Theory for Programmers” Ch. 7 - Bartosz Milewski
- Natural Transformations
- What is a morphism between functors?
- What is the naturality condition?
- How do natural transformations relate to polymorphic functions?
- Book Reference: “Category Theory for Programmers” Ch. 10 - Bartosz Milewski
- Endofunctors
- What is an endofunctor? (F : C → C, maps category to itself)
- Why are Haskell functors endofunctors on Hask?
- What is the category of endofunctors?
- Book Reference: “Category Theory for Programmers” Ch. 7 - Bartosz Milewski
- Monoids
- What is a monoid? (Set with binary operation and identity)
- What are the monoid laws? (associativity, identity)
- Examples: (Int, +, 0), (List, ++, [])
- Book Reference: “Haskell Programming from First Principles” Ch. 15 - Christopher Allen and Julie Moronuki
- Monads as Monoids in Endofunctors
- How is a monad a monoid?
- What are the monad’s “multiplication” (join) and “unit” (return)?
- How do monad laws correspond to monoid laws?
- Book Reference: “Category Theory for Programmers” Ch. 21 - Bartosz Milewski
Questions to Guide Your Design
Before implementing, think through these:
- Representing Categories
- How do you represent a category in code?
data Category obj mor = Category { objects :: [obj], morphisms :: [(mor, obj, obj)], ... }?- How do you represent composition?
- How do you verify category laws?
- Representing Functors
- A functor maps objects AND morphisms. How to represent both?
data Functor c1 c2 = Functor { mapObj :: obj1 -> obj2, mapMor :: mor1 -> mor2 }?- How do you verify functor laws (preserve identity, preserve composition)?
- Visualizing Morphism Composition
- How do you draw:
f : a → b,g : b → c,g ∘ f : a → c? - ASCII art? Graphviz? SVG?
- How do you show that composition is associative?
- How do you draw:
- Natural Transformations
- How do you represent
η : F → G(transformation between functors)? - What is the naturality square? How to visualize it?
- How to verify:
η_b ∘ F(f) = G(f) ∘ η_a?
- How do you represent
- Monad Structure
- How do you visualize
return : a → m a? - How do you visualize
join : m (m a) → m a? - How do you show the monad laws graphically?
- How do you visualize
- Interactive Exploration
- How do users interact with your visualizer?
- Command-line? Web interface?
- How do you let users define custom categories, functors?
Thinking Exercise
Trace a Functor by Hand
Before coding, manually verify that Maybe is a functor:
-- Functor F = Maybe
-- Source category: Hask
-- Target category: Hask (it's an endofunctor)
-- Object mapping:
-- Int → Maybe Int
-- String → Maybe String
-- a → Maybe a
-- Morphism mapping (fmap):
-- show : Int → String
-- ↓
-- fmap show : Maybe Int → Maybe String
-- Verify Functor Laws:
-- 1. Preserve Identity:
-- F(id_a) = id_{F(a)}
--
-- fmap id (Just 5) = Just (id 5) = Just 5 ✓
-- fmap id Nothing = Nothing ✓
-- Therefore: fmap id = id ✓
-- 2. Preserve Composition:
-- F(g ∘ f) = F(g) ∘ F(f)
--
-- Let f = show : Int → String
-- Let g = length : String → Int
--
-- Left side: fmap (length . show) (Just 42)
-- = Just ((length . show) 42)
-- = Just (length "42")
-- = Just 2
--
-- Right side: (fmap length . fmap show) (Just 42)
-- = fmap length (fmap show (Just 42))
-- = fmap length (Just "42")
-- = Just (length "42")
-- = Just 2
--
-- ✓ Both sides equal!
Questions while tracing:
- Draw the commutative diagram for functor composition
- What would happen if
Maybedidn’t preserve composition? - How would you automate this verification?
The Interview Questions They’ll Ask
Prepare to answer these:
- “What is a category?”
- Answer: A collection of objects and morphisms (arrows) with composition and identity, satisfying associativity and identity laws.
- “What is a functor in category theory?”
- Answer: A structure-preserving map between categories. It maps objects to objects and morphisms to morphisms, preserving identity and composition.
- “How does the Functor type class in Haskell relate to category theory?”
- Answer: It’s an endofunctor on Hask (Haskell types and functions).
fmapis the morphism mapping.
- Answer: It’s an endofunctor on Hask (Haskell types and functions).
- “What is a natural transformation?”
- Answer: A morphism between functors. In Haskell, it’s a polymorphic function that works uniformly across all types.
- “Explain ‘a monad is a monoid in the category of endofunctors.’“
- Answer: In the category of endofunctors, a monad has unit (return: Id → M) and multiplication (join: M∘M → M), satisfying monoid laws.
- “What is the naturality condition?”
- Answer: For natural transformation η : F → G, the square commutes: η_b ∘ F(f) = G(f) ∘ η_a for all morphisms f.
- “Why do functor laws matter?”
- Answer: They ensure
fmapis predictable and composable. Without laws,fmap idmight change values, breaking abstraction.
- Answer: They ensure
Hints in Layers
Hint 1: Start with Simple Category Representation
data Category obj mor = Category
{ objects :: [obj]
, morphisms :: [(mor, obj, obj)] -- (morphism, source, target)
, compose :: mor -> mor -> Maybe mor
, identity :: obj -> mor
}
-- Example: Small category
catExample :: Category String String
catExample = Category
{ objects = ["A", "B", "C"]
, morphisms = [("f", "A", "B"), ("g", "B", "C"), ("g.f", "A", "C")]
, compose = \m1 m2 -> ... -- implement composition
, identity = \obj -> "id_" ++ obj
}
Hint 2: Verify Category Laws
verifyIdentity :: Category obj mor -> Bool
verifyIdentity cat = all check (objects cat)
where
check obj =
let idMor = identity cat obj
morphs = filter (\(m, src, _) -> src == obj) (morphisms cat)
in all (\(m, _, _) -> compose cat idMor m == Just m) morphs
verifyAssociativity :: Category obj mor -> Bool
verifyAssociativity cat = ...
Hint 3: Represent Functors
data Functor' c1 c2 = Functor'
{ sourceCategory :: c1
, targetCategory :: c2
, mapObject :: obj1 -> obj2
, mapMorphism :: mor1 -> mor2
}
-- Maybe functor
maybeFunctor :: Functor' HaskCategory HaskCategory
maybeFunctor = Functor'
{ mapObject = \t -> MaybeType t
, mapMorphism = \f -> FmapF f
}
Hint 4: Visualize with ASCII Art
drawMorphism :: String -> String -> String -> String
drawMorphism src mor tgt =
src ++ " ──" ++ mor ++ "──→ " ++ tgt
drawCommutativeSquare :: String -> String -> String -> String -> String
drawCommutativeSquare f g h k =
unlines
[ " A ──" ++ f ++ "──→ B"
, " │ │"
, " " ++ g ++ " " ++ k
, " ↓ ↓"
, " C ──" ++ h ++ "──→ D"
]
Hint 5: Verify Functor Laws
verifyFunctorIdentity :: (Eq obj2, Eq mor2) => Functor' c1 c2 -> Bool
verifyFunctorIdentity f =
all (\obj -> mapMorphism f (identity (sourceCategory f) obj)
== identity (targetCategory f) (mapObject f obj))
(objects (sourceCategory f))
verifyFunctorComposition :: Functor' c1 c2 -> Bool
verifyFunctorComposition f = ...
-- F(g ∘ f) = F(g) ∘ F(f)
Hint 6: Natural Transformations
data NatTrans f g = NatTrans
{ source :: f
, target :: g
, component :: forall a. f a -> g a
}
-- Example: listToMaybe
listToMaybe' :: NatTrans [] Maybe
listToMaybe' = NatTrans
{ source = listFunctor
, target = maybeFunctor
, component = \case
[] -> Nothing
(x:_) -> Just x
}
Hint 7: Visualize Monad as Monoid
visualizeMonad :: Monad m => String
visualizeMonad =
unlines
[ "Monad Structure:"
, ""
, "Unit (return): a → m a"
, "Multiplication (join): m (m a) → m a"
, ""
, "Monoid Laws:"
, " join . return = id (left identity)"
, " join . fmap return = id (right identity)"
, " join . join = join . fmap join (associativity)"
]
Books That Will Help
| Topic | Book | Chapter |
|---|---|---|
| Categories, objects, morphisms | “Category Theory for Programmers” | Ch. 1-3 |
| Functors and their laws | “Category Theory for Programmers” | Ch. 7 |
| Natural transformations | “Category Theory for Programmers” | Ch. 10 |
| Monads categorically | “Category Theory for Programmers” | Ch. 21 |
| Functor/Applicative/Monad in Haskell | “Haskell Programming from First Principles” | Ch. 16-18 |
| More mathematical category theory | “Category Theory” by Steve Awodey | Ch. 1-4 |
| Applied category theory | “Seven Sketches in Compositionality” | Ch. 1-2 |
| Practical category theory | “Programming with Categories” (online book) | Ch. 1-3 |
| Visualizing mathematics | “Visual Group Theory” by Nathan Carter | Ch. 1-2 |
| Graph drawing algorithms | “Graph Drawing” by Di Battista et al. | Ch. 2-3 |
Project 14: Lisp Interpreter in Haskell
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: OCaml, Rust
- Coolness Level: Level 4: Hardcore Tech Flex
- Business Potential: 1. The “Resume Gold” (Educational/Personal Brand)
- Difficulty: Level 3: Advanced
- Knowledge Area: Interpreters / Language Implementation
- Software or Tool: Scheme Interpreter
- Main Book: “Write Yourself a Scheme in 48 Hours”
What you’ll build
A complete Scheme interpreter: parsing S-expressions, environment handling, primitive operations, lambda functions, macros, and a REPL.
Why it teaches Functional Programming
Lisp is the original functional language, and implementing it in Haskell is a rite of passage. You’ll use everything: parsing, monads for state/IO/errors, recursive data structures, and higher-order functions.
Core challenges you’ll face
- S-expression parsing (lists all the way down) → maps to parser combinators
- Environment management (lexical scoping) → maps to Reader monad
- Evaluation (apply, eval, special forms) → maps to interpretation
- Error handling (graceful failures) → maps to Either/ExceptT
Key Concepts
- Write Yourself a Scheme: 48 Hour Tutorial
- SICP Scheme: “Structure and Interpretation of Computer Programs” Chapter 4
- Lisp Evaluation: McCarthy’s original eval/apply
Difficulty
Advanced
Time estimate
3-4 weeks
Prerequisites
Project 7 (Parser combinators)
Real world outcome
scheme> (+ 1 2 3)
6
scheme> (define (square x) (* x x))
square
scheme> (square 5)
25
scheme> (define (factorial n)
(if (= n 0)
1
(* n (factorial (- n 1)))))
factorial
scheme> (factorial 10)
3628800
scheme> (map square '(1 2 3 4 5))
(1 4 9 16 25)
scheme> (define (my-map f xs)
(if (null? xs)
'()
(cons (f (car xs)) (my-map f (cdr xs)))))
my-map
scheme> (my-map (lambda (x) (+ x 10)) '(1 2 3))
(11 12 13)
scheme> (let ((x 10) (y 20)) (+ x y))
30
Implementation Hints
Pseudo-Haskell:
-- S-expressions
data LispVal
= Atom String
| Number Integer
| String String
| Bool Bool
| List [LispVal]
| DottedList [LispVal] LispVal
| PrimitiveFunc ([LispVal] -> ThrowsError LispVal)
| Func { params :: [String], body :: [LispVal], closure :: Env }
type Env = IORef [(String, IORef LispVal)]
type ThrowsError = Either LispError
type IOThrowsError = ExceptT LispError IO
-- Evaluation
eval :: Env -> LispVal -> IOThrowsError LispVal
eval env (Atom id) = getVar env id
eval env (Number n) = return (Number n)
eval env (String s) = return (String s)
eval env (Bool b) = return (Bool b)
eval env (List [Atom "quote", val]) = return val
eval env (List [Atom "if", pred, conseq, alt]) = do
result <- eval env pred
case result of
Bool True -> eval env conseq
_ -> eval env alt
eval env (List [Atom "define", Atom var, form]) = do
val <- eval env form
defineVar env var val
eval env (List (Atom "define" : List (Atom var : params) : body)) =
makeFunc params body env >>= defineVar env var
eval env (List [Atom "lambda", List params, body]) =
makeFunc (map show params) [body] env
eval env (List (function : args)) = do
func <- eval env function
argVals <- mapM (eval env) args
apply func argVals
apply :: LispVal -> [LispVal] -> IOThrowsError LispVal
apply (PrimitiveFunc func) args = liftThrows (func args)
apply (Func params body closure) args = do
env <- liftIO $ bindVars closure (zip params args)
evalBody env body
-- Primitive operations
primitives :: [(String, [LispVal] -> ThrowsError LispVal)]
primitives =
[ ("+", numericBinop (+))
, ("-", numericBinop (-))
, ("*", numericBinop (*))
, ("car", car)
, ("cdr", cdr)
, ("cons", cons)
, ("eq?", eqv)
]
Learning milestones
- Numbers and arithmetic work → You can evaluate expressions
- Lambda and define work → You have a real language
- Recursion works → You have a useful language
- map/filter work → You have a functional language
Project 15: Compile Functional Language to LLVM/C
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell
- Alternative Programming Languages: OCaml, Rust
- Coolness Level: Level 5: Pure Magic (Super Cool)
- Business Potential: 5. The “Industry Disruptor”
- Difficulty: Level 5: Master
- Knowledge Area: Compilers / Code Generation
- Software or Tool: Functional Language Compiler
- Main Book: “Compilers: Principles and Practice” by Dave & Dave
What you’ll build
A compiler for a small functional language: parsing, type checking (Hindley-Milner), closure conversion, and code generation to LLVM IR or C.
Why it teaches Functional Programming
This is the ultimate project. You’ll implement lambda calculus, type inference, and understand how functional features (closures, currying, lazy evaluation) get compiled to machine code.
Core challenges you’ll face
- Closure conversion (turning closures into explicit data) → maps to lambda lifting
- Continuation-passing style (making control flow explicit) → maps to CPS transform
- Garbage collection (memory management for FP) → maps to runtime systems
- Tail call optimization (recursive calls in constant space) → maps to TCO
Key Concepts
- Closure Conversion: “Compiling with Continuations” by Andrew Appel
- LLVM Code Generation: LLVM-HS documentation
- Lambda Lifting: Johnsson’s paper on lambda lifting
- CPS Transformation: “The Essence of Compiling with Continuations”
Difficulty
Master
Time estimate
2-3 months
Prerequisites
All previous projects, especially 4 & 14
Real world outcome
-- Source language:
let square = \x -> x * x in
let sum_squares = \x y -> square x + square y in
sum_squares 3 4
-- After type inference:
square : Int -> Int
sum_squares : Int -> Int -> Int
result : Int
-- After closure conversion:
struct Closure_square { (*code)(Closure*, Int) };
struct Closure_sum_squares { (*code)(Closure*, Int, Int), Closure* square_ref };
-- Generated LLVM IR:
define i32 @square(i32 %x) {
%result = mul i32 %x, %x
ret i32 %result
}
define i32 @sum_squares(i32 %x, i32 %y) {
%sq_x = call i32 @square(i32 %x)
%sq_y = call i32 @square(i32 %y)
%result = add i32 %sq_x, %sq_y
ret i32 %result
}
define i32 @main() {
%result = call i32 @sum_squares(i32 3, i32 4)
ret i32 %result ; returns 25
}
-- Compile and run:
$ ./mycompiler program.ml -o program
$ ./program
25
Implementation Hints
Pseudo-Haskell:
-- 1. Parse to AST
data Expr
= Var String
| Lam String Expr
| App Expr Expr
| Let String Expr Expr
| Lit Int
| BinOp Op Expr Expr
-- 2. Type check (Hindley-Milner, from Project 4)
typeCheck :: Expr -> Either TypeError Type
-- 3. Closure conversion
-- Turn: \x -> x + y (where y is free)
-- Into: { code = \env x -> x + env.y, env = { y = y } }
data ClosureConverted
= CVar String
| CClosure [String] ClosureConverted -- free vars + body
| CApp ClosureConverted ClosureConverted
| CEnvRef Int -- reference to captured variable
| ...
closureConvert :: Expr -> ClosureConverted
closureConvert expr = go (freeVars expr) expr
where
go env (Lam x body) =
let fvs = freeVars body \\ [x]
in CClosure fvs (go (fvs ++ [x]) body)
go env (Var x) =
case elemIndex x env of
Just i -> CEnvRef i
Nothing -> CVar x
...
-- 4. Generate LLVM IR
codegen :: ClosureConverted -> LLVM.Module
codegen expr = buildModule "main" $ do
-- Generate closure struct types
-- Generate function code
-- Generate main that calls top-level expression
define "main" [] i32 $ do
result <- generateExpr expr
ret result
Learning milestones
- Parser and type checker work → You have a front-end
- Closure conversion works → You understand compilation of FP
- Code generates and runs → You have a working compiler
- Tail calls optimized → You understand advanced compilation
Final Comprehensive Project: Self-Hosting Functional Language
- File: FUNCTIONAL_PROGRAMMING_LAMBDA_CALCULUS_HASKELL_PROJECTS.md
- Main Programming Language: Haskell (then your language!)
- Alternative Programming Languages: OCaml, Rust
- Coolness Level: Level 5: Pure Magic (Super Cool)
- Business Potential: 5. The “Industry Disruptor”
- Difficulty: Level 5: Master
- Knowledge Area: Language Implementation / Bootstrapping
- Software or Tool: Self-Hosting Compiler
- Main Book: “Types and Programming Languages” by Benjamin Pierce
What you’ll build
A functional programming language that can compile itself. Start with a Haskell implementation, then rewrite the compiler in your own language, achieving self-hosting.
Why it teaches Functional Programming
Self-hosting is the ultimate test of language understanding. Your language must be expressive enough to implement its own compiler. This proves you’ve created something real.
Core challenges you’ll face
- Feature completeness (enough features to write a compiler) → maps to language design
- Bootstrapping (chicken-and-egg: need compiler to compile compiler) → maps to bootstrapping
- Standard library (I/O, strings, data structures in your language) → maps to runtime
- Optimization (your compiler must be fast enough) → maps to performance
Key Concepts
- Bootstrapping: Use Haskell to compile V1, then V1 to compile V2
- Minimal Language: What’s the smallest language that can self-host?
- GHC History: How GHC bootstrapped from C
Difficulty
Master (6+ months)
Time estimate
6-12 months
Prerequisites
All previous projects
Real world outcome
-- Your language (call it "Lambda"):
-- This is the compiler for Lambda, written in Lambda!
module Compiler where
data Expr = Var String | Lam String Expr | App Expr Expr | ...
parse :: String -> Expr
parse = ...
typeCheck :: Expr -> Either Error Type
typeCheck = ...
compile :: Expr -> LLVM
compile = ...
main :: IO ()
main = do
source <- readFile "input.lam"
let ast = parse source
case typeCheck ast of
Left err -> print err
Right _ -> writeFile "output.ll" (compile ast)
-- Compile the compiler with itself:
$ lambda compiler.lam -o lambda2 # lambda compiles compiler to lambda2
$ lambda2 compiler.lam -o lambda3 # lambda2 compiles compiler to lambda3
$ diff lambda2 lambda3 # should be identical!
(no differences - self-hosting achieved!)
Implementation Hints
Start with a minimal core:
- Lambda calculus + integers + booleans
- Algebraic data types + pattern matching
- Type inference
- IO monad for effects
Then add syntactic sugar until you can comfortably write a compiler.
Learning milestones
- Haskell implementation complete → You have a working compiler
- Rewrite begins in your language → You’re eating your own dog food
- Rewrite compiles with original → Bootstrap stage 1
- Rewrite compiles itself → Self-hosting achieved!
Project Comparison Table
| Project | Difficulty | Time | Depth of Understanding | Fun Factor |
|---|---|---|---|---|
| 1. Lambda Calculus Interpreter | Advanced | 2-3 weeks | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 2. Church Encodings | Advanced | 1-2 weeks | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 3. Reduction Visualizer | Advanced | 1-2 weeks | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 4. Type Inference Engine | Expert | 3-4 weeks | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 5. Algebraic Data Types | Intermediate | 1-2 weeks | ⭐⭐⭐ | ⭐⭐⭐ |
| 6. Functor/Applicative/Monad | Expert | 2-3 weeks | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 7. Parser Combinators | Advanced | 2-3 weeks | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 8. Lazy Evaluation | Expert | 2-3 weeks | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 9. Monad Transformers | Expert | 2-3 weeks | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 10. Property-Based Testing | Advanced | 2-3 weeks | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 11. Lenses/Optics | Expert | 3-4 weeks | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 12. Free Monad DSL | Master | 2-3 weeks | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 13. Category Theory Visualizer | Expert | 3-4 weeks | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 14. Lisp Interpreter | Advanced | 3-4 weeks | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 15. Compile to LLVM | Master | 2-3 months | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Final: Self-Hosting Language | Master | 6-12 months | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
Recommended Learning Path
Phase 1: Lambda Calculus Foundations (6-8 weeks)
- Project 1: Lambda Calculus Interpreter - The theoretical foundation
- Project 2: Church Encodings - Data from nothing
- Project 3: Reduction Visualizer - See computation happen
Phase 2: Haskell Fundamentals (4-6 weeks)
- Project 5: Algebraic Data Types - Modeling data
- Project 6: Functor/Applicative/Monad - The type class hierarchy
Phase 3: Type Systems (4-6 weeks)
- Project 4: Type Inference Engine - Hindley-Milner
Phase 4: Practical Haskell (8-10 weeks)
- Project 7: Parser Combinators - Elegant parsing
- Project 8: Lazy Evaluation - Haskell’s secret
- Project 9: Monad Transformers - Effect composition
- Project 10: Property-Based Testing - Testing done right
Phase 5: Advanced Topics (8-10 weeks)
- Project 11: Lenses/Optics - Data access
- Project 12: Free Monad DSL - Separation of concerns
- Project 13: Category Theory Visualizer - Mathematical foundations
Phase 6: Language Implementation (4-6 months)
- Project 14: Lisp Interpreter - Classic exercise
- Project 15: Compile to LLVM - Real compilation
- Final: Self-Hosting Language - The ultimate test
Essential Resources
Books
- “Haskell Programming from First Principles” by Allen & Moronuki - Best introduction
- “Learn You a Haskell for Great Good!” by Miran Lipovača - Fun and visual
- “Programming in Haskell” by Graham Hutton - Academic but practical
- “Types and Programming Languages” by Benjamin Pierce - Type theory bible
- “Category Theory for Programmers” by Bartosz Milewski - CT for coders
- “Haskell in Depth” by Vitaly Bragilevsky - Real-world Haskell
Papers
- “A Tutorial Introduction to the Lambda Calculus” - Raúl Rojas
- “Monadic Parsing in Haskell” - Hutton & Meijer
- “QuickCheck: A Lightweight Tool for Random Testing” - Claessen & Hughes
- “Functional Pearl: Monadic Parsing in Haskell” - Hutton
Online
- Haskell Wiki - Community knowledge base
- Typeclassopedia - Type class guide
- Learn X in Y Minutes: Lambda Calculus
- Stanford CS 242: Lambda Calculus
Summary
| # | Project | Main Language |
|---|---|---|
| 1 | Pure Lambda Calculus Interpreter | Haskell |
| 2 | Church Encodings Library | Haskell |
| 3 | Reduction Visualizer | Haskell |
| 4 | Simply Typed Lambda + Type Inference | Haskell |
| 5 | Algebraic Data Types Library | Haskell |
| 6 | Functor-Applicative-Monad Hierarchy | Haskell |
| 7 | Parser Combinator Library | Haskell |
| 8 | Lazy Evaluation Demonstrator | Haskell |
| 9 | Monad Transformers from Scratch | Haskell |
| 10 | Property-Based Testing Framework | Haskell |
| 11 | Lenses and Optics Library | Haskell |
| 12 | Free Monad DSL | Haskell |
| 13 | Category Theory Visualizer | Haskell |
| 14 | Lisp Interpreter in Haskell | Haskell |
| 15 | Compile Functional Language to LLVM | Haskell |
| Final | Self-Hosting Functional Language | Haskell → Your Language |
“A monad is just a monoid in the category of endofunctors, what’s the problem?” — A Haskeller, probably
After completing these projects, you’ll actually understand what that means.