Project 7: Y86-64 CPU Simulator
Build a complete Y86-64 processor simulator that executes instructions both sequentially and through a pipelined model, producing detailed cycle-by-cycle traces that explain every stall, bubble, and forwarding decision.
Quick Reference
| Attribute | Value |
|---|---|
| Language | C (alt: Rust, Zig, C++) |
| Difficulty | Expert |
| Time | 1 month+ |
| Chapters | 4, 5 |
| Coolness | ★★★★★ Pure Magic |
| Portfolio Value | Resume Gold |
Table of Contents
- Learning Objectives
- Theoretical Foundation
- Project Specification
- Solution Architecture
- Implementation Guide
- Testing Strategy
- Common Pitfalls
- Extensions
- Real-World Connections
- Resources
- Self-Assessment Checklist
Learning Objectives
By completing this project, you will:
- Internalize ISA semantics: Understand exactly what each instruction does at the register/memory level
- Master datapath design: Know how data flows through fetch, decode, execute, memory, and writeback stages
- Understand pipeline hazards: Identify and classify RAW, WAR, and WAW dependencies
- Implement hazard mitigation: Build forwarding paths, stall logic, and bubble insertion
- Validate correctness rigorously: Prove that pipelined execution matches sequential semantics
- Think like hardware: Model time as discrete cycles, state as registers, and computation as combinational logic
- Debug at the cycle level: Trace execution and explain every micro-architectural decision
Theoretical Foundation
Y86-64 ISA Overview
Y86-64 is a teaching ISA designed by Bryant and O’Hallaron to illustrate processor design concepts. It’s a simplified subset of x86-64:
+-----------------------------------------------------------------------+
| Y86-64 vs x86-64 |
+-----------------------------------------------------------------------+
| Feature | Y86-64 | x86-64 |
|-------------------|-----------------------|---------------------------|
| Registers | 15 (no %r15) | 16 |
| Addressing Modes | Register, Immediate, | Many complex modes |
| | Base+Displacement | |
| Condition Codes | ZF, SF, OF | ZF, SF, OF, CF, PF, ... |
| Instructions | ~20 simple ones | 1000+ with extensions |
| Instruction Size | 1-10 bytes | 1-15 bytes |
| Privilege Levels | None | Ring 0-3 |
+-----------------------------------------------------------------------+
The simplification makes pipeline design tractable while preserving
the essential concepts of real processor architecture.
Y86-64 Instruction Set
+-----------------------------------------------------------------------+
| Y86-64 INSTRUCTION SET |
+-----------------------------------------------------------------------+
| Category | Instruction | Description |
|---------------|----------------|--------------------------------------|
| Data Transfer | irmovq V, rB | Immediate -> Register |
| | rrmovq rA, rB | Register -> Register |
| | mrmovq D(rB),rA| Memory -> Register |
| | rmmovq rA,D(rB)| Register -> Memory |
|---------------|----------------|--------------------------------------|
| Arithmetic | addq rA, rB | rB = rB + rA (sets CC) |
| | subq rA, rB | rB = rB - rA (sets CC) |
| | andq rA, rB | rB = rB & rA (sets CC) |
| | xorq rA, rB | rB = rB ^ rA (sets CC) |
|---------------|----------------|--------------------------------------|
| Control Flow | jmp Dest | Unconditional jump |
| | jle, jl, je, | Conditional jumps based on CC |
| | jne, jge, jg | |
| | call Dest | Push return addr, jump |
| | ret | Pop return addr, jump |
|---------------|----------------|--------------------------------------|
| Stack | pushq rA | Decrement %rsp, store rA |
| | popq rA | Load to rA, increment %rsp |
|---------------|----------------|--------------------------------------|
| Conditional | cmovle, cmovl, | Conditional move (if CC) |
| | cmove, cmovne, | |
| | cmovge, cmovg | |
|---------------|----------------|--------------------------------------|
| Special | halt | Stop execution |
| | nop | No operation |
+-----------------------------------------------------------------------+
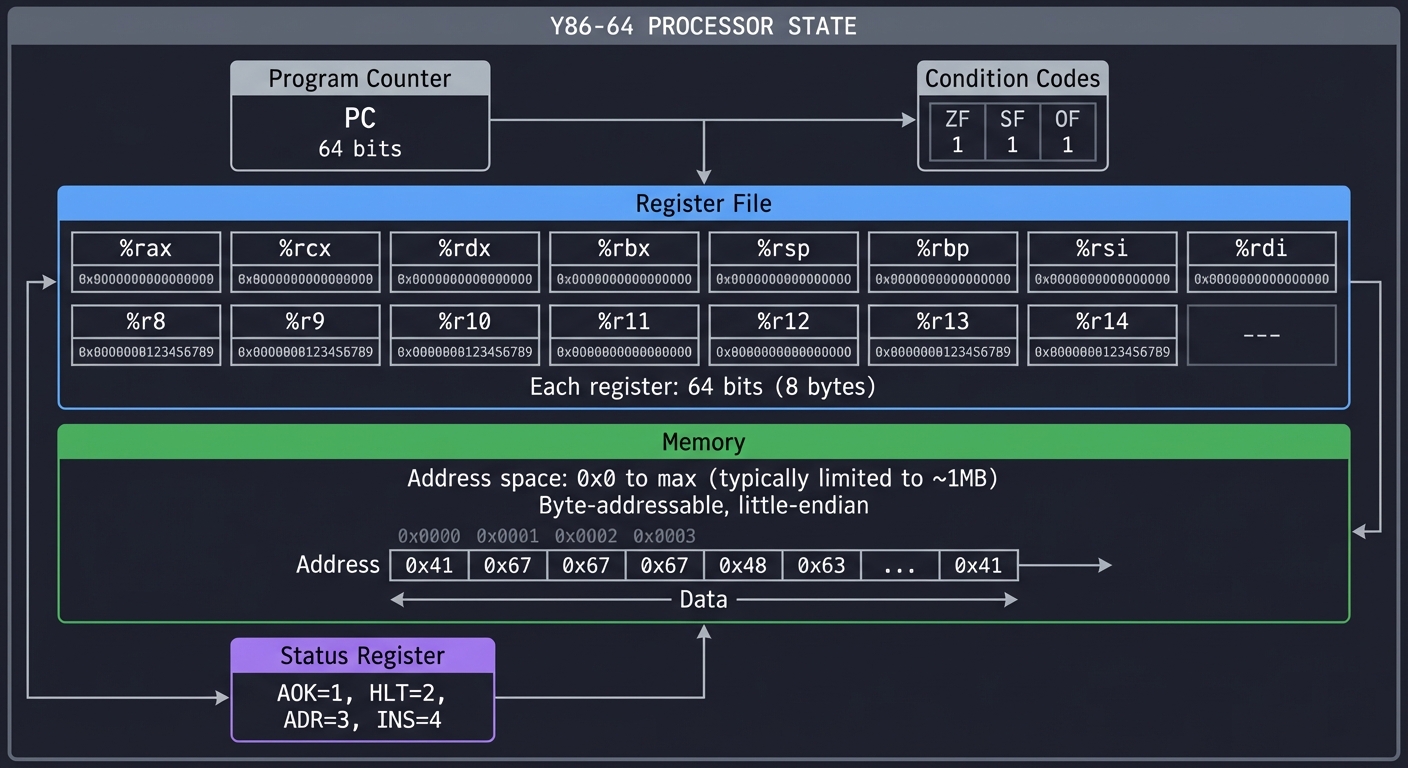
Processor State
+-----------------------------------------------------------------------+
| Y86-64 PROCESSOR STATE |
+-----------------------------------------------------------------------+
| |
| +------------------+ +------------------+ |
| | Program Counter | | Condition Codes | |
| | PC | | ZF SF OF | |
| | 64 bits | | 1 1 1 | |
| +------------------+ +------------------+ |
| |
| +----------------------------------------------------------+ |
| | Register File | |
| | +-----+-----+-----+-----+-----+-----+-----+-----+ | |
| | | %rax| %rcx| %rdx| %rbx| %rsp| %rbp| %rsi| %rdi| | |
| | +-----+-----+-----+-----+-----+-----+-----+-----+ | |
| | | %r8 | %r9 | %r10| %r11| %r12| %r13| %r14| --- | | |
| | +-----+-----+-----+-----+-----+-----+-----+-----+ | |
| | Each register: 64 bits (8 bytes) | |
| +----------------------------------------------------------+ |
| |
| +----------------------------------------------------------+ |
| | Memory | |
| | Address space: 0x0 to max (typically limited to ~1MB) | |
| | Byte-addressable, little-endian | |
| +----------------------------------------------------------+ |
| |
| +------------------+ |
| | Status Register | |
| | AOK=1, HLT=2, | |
| | ADR=3, INS=4 | |
| +------------------+ |
| |
+-----------------------------------------------------------------------+
Instruction Encoding Format
Y86-64 uses variable-length instruction encoding (1-10 bytes):
+-----------------------------------------------------------------------+
| INSTRUCTION ENCODING FORMAT |
+-----------------------------------------------------------------------+
| |
| Generic format: |
| +--------+--------+------------------+------------------+ |
| | icode | ifun | rA | rB | Constant | |
| | 4 bits | 4 bits | 4 bits | 4 bits | 0, 4, or 8 B | |
| +--------+--------+------------------+------------------+ |
| Byte 0 Byte 1 Bytes 2-9 |
| |
| icode: Instruction code (determines instruction type) |
| ifun: Function code (distinguishes variants) |
| rA, rB: Register specifiers (0xF = no register) |
| |
+-----------------------------------------------------------------------+
| |
| Examples: |
| |
| halt [0x00] (1 byte) |
| |
| nop [0x10] (1 byte) |
| |
| rrmovq %rax, %rbx |
| [0x20] [0x03] (2 bytes) |
| ^^^^ ^^^^ |
| icode rA=0, rB=3 |
| ifun=0 |
| |
| irmovq $0x123456789abcdef0, %rdx |
| [0x30] [0xF2] [0xF0 0xDE ... 0x12] (10 bytes) |
| ^^^^ ^^^^ ^^^^^^^^^^^^^^^^ |
| icode rA=F 8-byte immediate (little-endian) |
| ifun=0 rB=2 |
| |
| mrmovq 8(%rbp), %rax |
| [0x50] [0x05] [0x08 0x00 ... 0x00] (10 bytes) |
| ^^^^ ^^^^ ^^^^^^^^^^^^^^^^ |
| icode rA=0 8-byte displacement (= 8) |
| rB=5 |
| |
| addq %rax, %rbx |
| [0x60] [0x03] (2 bytes) |
| ^^^^ ^^^^ |
| icode rA=0, rB=3 |
| ifun=0 |
| |
| jle target |
| [0x71] [target address] (9 bytes) |
| ^^^^ ^^^^^^^^^^^^^^^ |
| icode 8-byte absolute address |
| ifun=1 (le) |
| |
| call function |
| [0x80] [function address] (9 bytes) |
| |
| ret [0x90] (1 byte) |
| |
| pushq %rax [0xA0] [0x0F] (2 bytes) |
| ^^^^ |
| rA=0, rB=F (unused) |
| |
| popq %rax [0xB0] [0x0F] (2 bytes) |
| |
+-----------------------------------------------------------------------+

Instruction Code Table
+-----------------------------------------------------------------------+
| ICODE / IFUN VALUES |
+-----------------------------------------------------------------------+
| icode | ifun | Instruction | Bytes | Description |
|-------|------|-------------|-------|----------------------------------|
| 0 | 0 | halt | 1 | Stop execution |
| 1 | 0 | nop | 1 | No operation |
| 2 | 0-6 | rrmovq/cmov | 2 | Register/conditional move |
| 3 | 0 | irmovq | 10 | Immediate to register |
| 4 | 0 | rmmovq | 10 | Register to memory |
| 5 | 0 | mrmovq | 10 | Memory to register |
| 6 | 0-3 | OPq | 2 | Arithmetic (add/sub/and/xor) |
| 7 | 0-6 | jXX | 9 | Conditional jump |
| 8 | 0 | call | 9 | Call function |
| 9 | 0 | ret | 1 | Return from function |
| A | 0 | pushq | 2 | Push register to stack |
| B | 0 | popq | 2 | Pop from stack to register |
+-----------------------------------------------------------------------+
ifun values for conditional operations:
0: unconditional (always) 1: le (<=)
2: l (<) 3: e (==)
4: ne (!=) 5: ge (>=)
6: g (>)
Register File Design
The register file is a key component that must support multiple reads and writes:
+-----------------------------------------------------------------------+
| REGISTER FILE DESIGN |
+-----------------------------------------------------------------------+
| |
| +---------------------------+ |
| | 15 x 64-bit Regs | |
| +---------------------------+ |
| | | | |
| Read Port A | | | Write Port |
| +-------+ | | | +-------+ |
| | srcA |--------------->| | |<----------| dstE | |
| +-------+ valA <-----| | | +-------+ |
| | | |------> valE |
| Read Port B | | | |
| +-------+ | | | +-------+ |
| | srcB |--------------->| | |<----------| dstM | |
| +-------+ valB <-----| | | +-------+ |
| | | |------> valM |
| +---------------------------+ |
| |
| Read ports: 2 (simultaneous reads for srcA and srcB) |
| Write ports: 2 (dstE for ALU results, dstM for memory loads) |
| |
| Register IDs: |
| 0: %rax 4: %rsp 8: %r8 12: %r12 |
| 1: %rcx 5: %rbp 9: %r9 13: %r13 |
| 2: %rdx 6: %rsi 10: %r10 14: %r14 |
| 3: %rbx 7: %rdi 11: %r11 15: NONE (0xF) |
| |
+-----------------------------------------------------------------------+

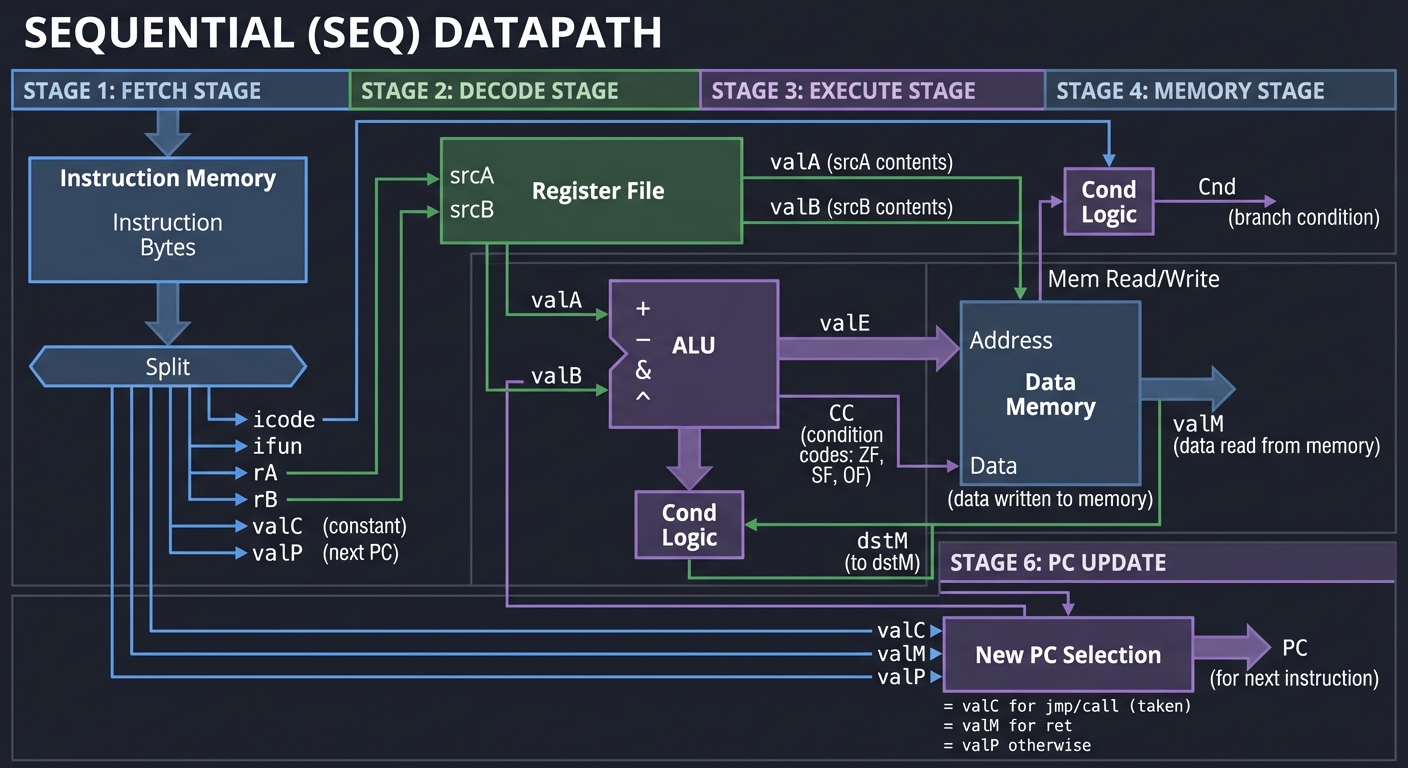
Sequential CPU Datapath
The sequential (SEQ) implementation executes one instruction per clock cycle:
+-----------------------------------------------------------------------+
| SEQUENTIAL (SEQ) DATAPATH |
+-----------------------------------------------------------------------+
| |
| +------------------------------------------------------------------+ |
| | FETCH STAGE | |
| +------------------------------------------------------------------+ |
| | |
| v |
| +-------------+ |
| | Instruction | +--------+ |
| | Memory |---->| Split |---> icode, ifun |
| +-------------+ +--------+---> rA, rB |
| | |---> valC (constant) |
| | |---> valP (next PC) |
| v |
| +------------------------------------------------------------------+ |
| | DECODE STAGE | |
| +------------------------------------------------------------------+ |
| | |
| v |
| +-------------+ |
| | Register |---> valA (srcA contents) |
| | File |---> valB (srcB contents) |
| +-------------+ |
| | |
| v |
| +------------------------------------------------------------------+ |
| | EXECUTE STAGE | |
| +------------------------------------------------------------------+ |
| | |
| v |
| +-------------+ |
| | ALU |---> valE (result) |
| +-------------+---> CC (condition codes: ZF, SF, OF) |
| | |
| | +------------+ |
| |-------->| Cond Logic |---> Cnd (branch condition) |
| | +------------+ |
| v |
| +------------------------------------------------------------------+ |
| | MEMORY STAGE | |
| +------------------------------------------------------------------+ |
| | |
| v |
| +-------------+ |
| | Data |---> valM (data read from memory) |
| | Memory |<--- (data written to memory) |
| +-------------+ |
| | |
| v |
| +------------------------------------------------------------------+ |
| | WRITEBACK STAGE | |
| +------------------------------------------------------------------+ |
| | |
| v |
| +-------------+ |
| | Register |<--- valE (to dstE) |
| | File |<--- valM (to dstM) |
| +-------------+ |
| | |
| v |
| +------------------------------------------------------------------+ |
| | PC UPDATE | |
| +------------------------------------------------------------------+ |
| | |
| v |
| +-------------+ |
| | New PC |---> PC (for next instruction) |
| | Selection | = valC for jmp/call (taken) |
| +-------------+ = valM for ret |
| = valP otherwise |
| |
+-----------------------------------------------------------------------+
Stage-by-Stage Details
+-----------------------------------------------------------------------+
| FETCH-DECODE-EXECUTE-MEMORY-WRITEBACK |
+-----------------------------------------------------------------------+
| |
| FETCH: |
| 1. Read instruction bytes from memory[PC] |
| 2. Extract icode, ifun from first byte |
| 3. Determine instruction length |
| 4. Extract rA, rB from register specifier byte (if present) |
| 5. Extract valC (8-byte constant, if present) |
| 6. Compute valP = PC + instruction_length |
| 7. Check for invalid instruction (set status = INS) |
| |
| DECODE: |
| 1. Determine srcA, srcB based on icode |
| 2. Read valA = R[srcA] (if srcA != 0xF) |
| 3. Read valB = R[srcB] (if srcB != 0xF) |
| 4. For pushq/popq, handle %rsp specially |
| |
| EXECUTE: |
| 1. Select ALU inputs (valA, valB, valC, or constants) |
| 2. Compute valE = ALU(aluA, aluB, operation) |
| 3. For OPq: set condition codes (ZF, SF, OF) |
| 4. For conditional: evaluate condition using CC |
| |
| MEMORY: |
| 1. For mrmovq/popq: valM = Memory[valE] |
| 2. For rmmovq/pushq: Memory[valE] = valA |
| 3. For call: Memory[valE] = valP (push return address) |
| 4. For ret: valM = Memory[valA] |
| 5. Check for invalid address (set status = ADR) |
| |
| WRITEBACK: |
| 1. Determine dstE, dstM based on icode |
| 2. For conditional move: dstE = 0xF if !Cnd (no write) |
| 3. Write R[dstE] = valE (if dstE != 0xF) |
| 4. Write R[dstM] = valM (if dstM != 0xF) |
| |
| PC UPDATE: |
| 1. For call: PC = valC |
| 2. For ret: PC = valM |
| 3. For jXX (taken): PC = valC |
| 4. Otherwise: PC = valP |
| |
+-----------------------------------------------------------------------+
Control Logic for SEQ
Each instruction needs specific control signals. Here’s a subset:
+-----------------------------------------------------------------------+
| SEQ CONTROL SIGNAL LOGIC |
+-----------------------------------------------------------------------+
| |
| srcA: |
| rrmovq, rmmovq, OPq, pushq: rA |
| popq, ret: %rsp |
| otherwise: NONE (0xF) |
| |
| srcB: |
| OPq, rmmovq, mrmovq: rB |
| pushq, popq, call, ret: %rsp |
| otherwise: NONE (0xF) |
| |
| dstE: |
| rrmovq, irmovq, OPq: rB |
| pushq, popq, call, ret: %rsp |
| otherwise: NONE (0xF) |
| |
| dstM: |
| mrmovq, popq: rA |
| otherwise: NONE (0xF) |
| |
| aluA: |
| rrmovq, OPq: valA |
| irmovq, rmmovq, mrmovq: valC |
| call, pushq: -8 |
| ret, popq: 8 |
| |
| aluB: |
| rrmovq, irmovq: 0 |
| OPq, rmmovq, mrmovq, pushq, popq, call, ret: valB |
| |
| aluFun: |
| OPq: ifun (0=add, 1=sub, 2=and, 3=xor) |
| otherwise: ADD (always add for address calculation) |
| |
+-----------------------------------------------------------------------+
Pipelining Fundamentals
Pipelining overlaps instruction execution to improve throughput:
+-----------------------------------------------------------------------+
| WHY PIPELINE? |
+-----------------------------------------------------------------------+
| |
| SEQUENTIAL (SEQ): |
| +-------+-------+-------+-------+-------+ |
| | I1 | I2 | I3 | I4 | I5 | ... |
| | FDEMW | FDEMW | FDEMW | FDEMW | FDEMW | |
| +-------+-------+-------+-------+-------+ |
| Cycle: 5 10 15 20 25 |
| |
| Each instruction takes 5 cycles, throughput = 1 instr / 5 cycles |
| |
| PIPELINED (PIPE): |
| +---+---+---+---+---+---+---+---+---+ |
| |I1F|I1D|I1E|I1M|I1W| | | | | |
| | |I2F|I2D|I2E|I2M|I2W| | | | |
| | | |I3F|I3D|I3E|I3M|I3W| | | |
| | | | |I4F|I4D|I4E|I4M|I4W| | |
| | | | | |I5F|I5D|I5E|I5M|I5W| |
| +---+---+---+---+---+---+---+---+---+ |
| Cycle: 1 2 3 4 5 6 7 8 9 |
| |
| 5 instructions complete by cycle 9 (vs cycle 25) |
| Throughput approaches 1 instr / cycle (5x improvement!) |
| |
+-----------------------------------------------------------------------+
| |
| PIPELINE REGISTERS (between stages): |
| |
| +----+ +----+ +----+ +----+ +----+ |
| | F |----->| D |----->| E |----->| M |----->| W | |
| +----+ F/D +----+ D/E +----+ E/M +----+ M/W +----+ |
| reg reg reg reg |
| |
| Each clock cycle: |
| - All pipeline registers update simultaneously |
| - Each stage processes its current values |
| - Output flows into the next stage's register |
| |
+-----------------------------------------------------------------------+
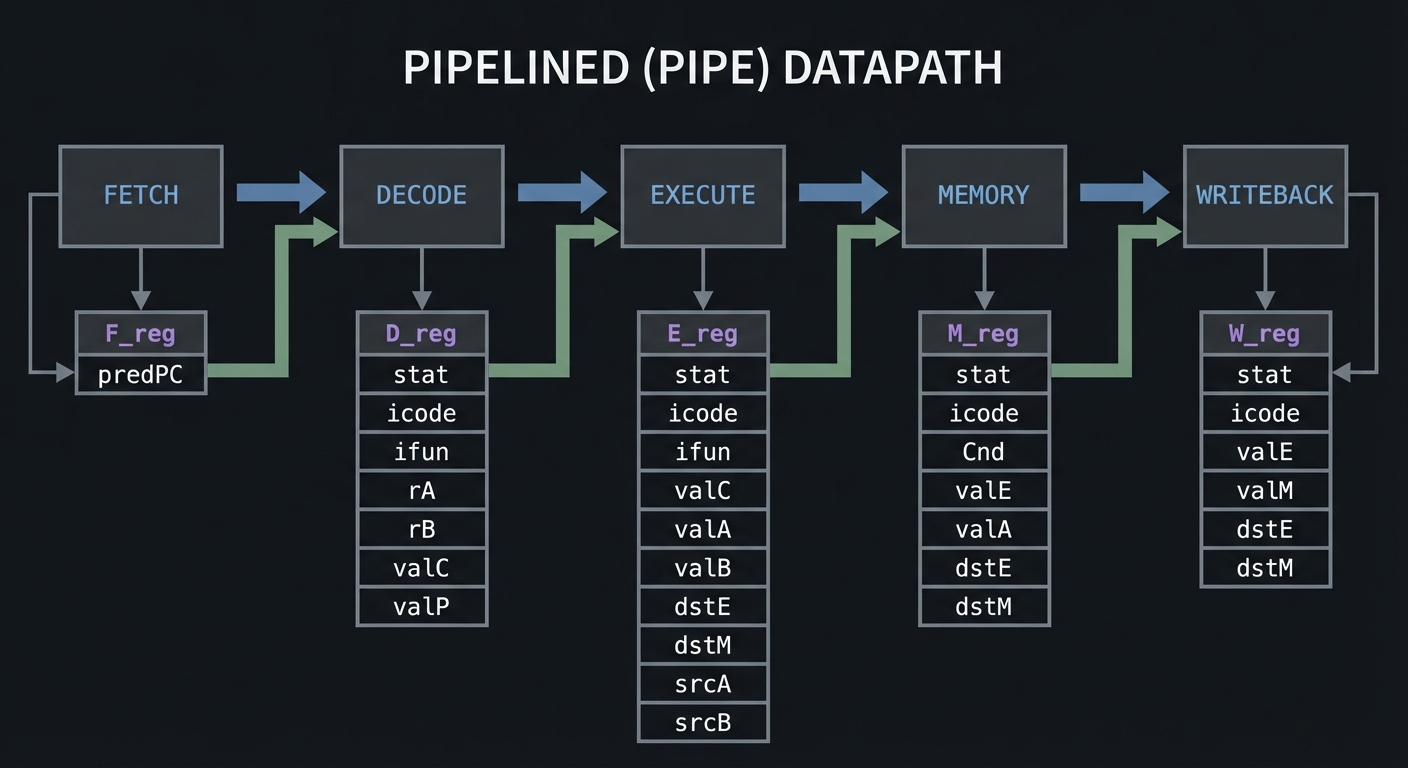
The PIPE Datapath
+-----------------------------------------------------------------------+
| PIPELINED (PIPE) DATAPATH |
+-----------------------------------------------------------------------+
| |
| +-------+ +--------+ +--------+ +--------+ +---------+ |
| | FETCH |===>| DECODE |===>|EXECUTE |===>| MEMORY |===>|WRITEBACK| |
| +-------+ +--------+ +--------+ +--------+ +---------+ |
| | | | | | |
| v v v v v |
| +-------+ +--------+ +--------+ +--------+ |
| | F_reg | | D_reg | | E_reg | | M_reg | |
| +-------+ +--------+ +--------+ +--------+ |
| | predPC| | stat | | stat | | stat | |
| | | | icode | | icode | | icode | |
| | | | ifun | | ifun | | Cnd | |
| | | | rA | | valC | | valE | |
| | | | rB | | valA | | valA | |
| | | | valC | | valB | | dstE | |
| | | | valP | | dstE | | dstM | |
| | | | | | dstM | | | |
| | | | | | srcA | | | |
| | | | | | srcB | | | |
| +-------+ +--------+ +--------+ +--------+ |
| |
| +--------+ |
| | W_reg | |
| +--------+ |
| | stat | |
| | icode | |
| | valE | |
| | valM | |
| | dstE | |
| | dstM | |
| +--------+ |
| |
+-----------------------------------------------------------------------+
Data Hazards
Data hazards occur when instructions depend on results not yet available:
+-----------------------------------------------------------------------+
| DATA HAZARDS |
+-----------------------------------------------------------------------+
| |
| RAW (Read After Write) - Most Common: |
| ------------------------------------- |
| irmovq $10, %rax # Writes %rax in stage 5 (W) |
| addq %rax, %rbx # Reads %rax in stage 2 (D) |
| |
| Cycle: 1 2 3 4 5 6 7 |
| irmovq: F D E M W |
| addq: F D E M W |
| ^ ^ |
| | | |
| Reads %rax Writes %rax |
| |
| Problem: addq reads OLD value of %rax (before irmovq writes) |
| |
| WAW (Write After Write) - Rare in Y86: |
| -------------------------------------- |
| irmovq $10, %rax |
| irmovq $20, %rax # Both write %rax |
| |
| In PIPE: resolved because writes happen in order |
| |
| WAR (Write After Read) - Cannot Happen in PIPE: |
| ----------------------------------------------- |
| In-order pipeline reads before writes, so WAR is impossible |
| |
+-----------------------------------------------------------------------+
| |
| HAZARD CASES BY STAGE DISTANCE: |
| -------------------------------- |
| |
| Case 1: Execute depends on Decode (distance = 1) |
| +---+---+---+---+---+ |
| | F | D | E | M | W | Instruction 1 (producer) |
| | | F | D | E | M | Instruction 2 (consumer) |
| +---+---+---+---+---+ |
| ^ ^ |
| D reads E produces |
| |
| valE not ready when I2 needs it in D stage |
| Solution: FORWARD from E_valE |
| |
| Case 2: Memory depends on Execute (distance = 2) |
| +---+---+---+---+---+---+ |
| | F | D | E | M | W | | Instruction 1 (producer) |
| | | | F | D | E | M | Instruction 2 (consumer) |
| +---+---+---+---+---+---+ |
| ^ ^ |
| D reads M has valE |
| |
| valE ready by M, forward from M_valE |
| Solution: FORWARD from M_valE |
| |
| Case 3: Writeback depends on Execute (distance = 3) |
| +---+---+---+---+---+---+---+ |
| | F | D | E | M | W | | | Instruction 1 |
| | | | | F | D | E | M | Instruction 2 |
| +---+---+---+---+---+---+---+ |
| ^ ^ |
| D reads W has valE |
| |
| Solution: FORWARD from W_valE |
| |
| Case 4: Load-Use Hazard (special - REQUIRES STALL) |
| mrmovq (%rax), %rbx # Produces valM in M stage |
| addq %rbx, %rcx # Needs %rbx in D stage |
| |
| +---+---+---+---+---+---+ |
| | F | D | E | M | W | | mrmovq |
| | | F | D | E | M | W | addq |
| +---+---+---+---+---+---+ |
| ^ ^ |
| D reads M produces valM |
| |
| Cannot forward: valM not available until END of M stage |
| But D needs it at START of cycle |
| Solution: STALL (insert bubble, delay addq by 1 cycle) |
| |
+-----------------------------------------------------------------------+
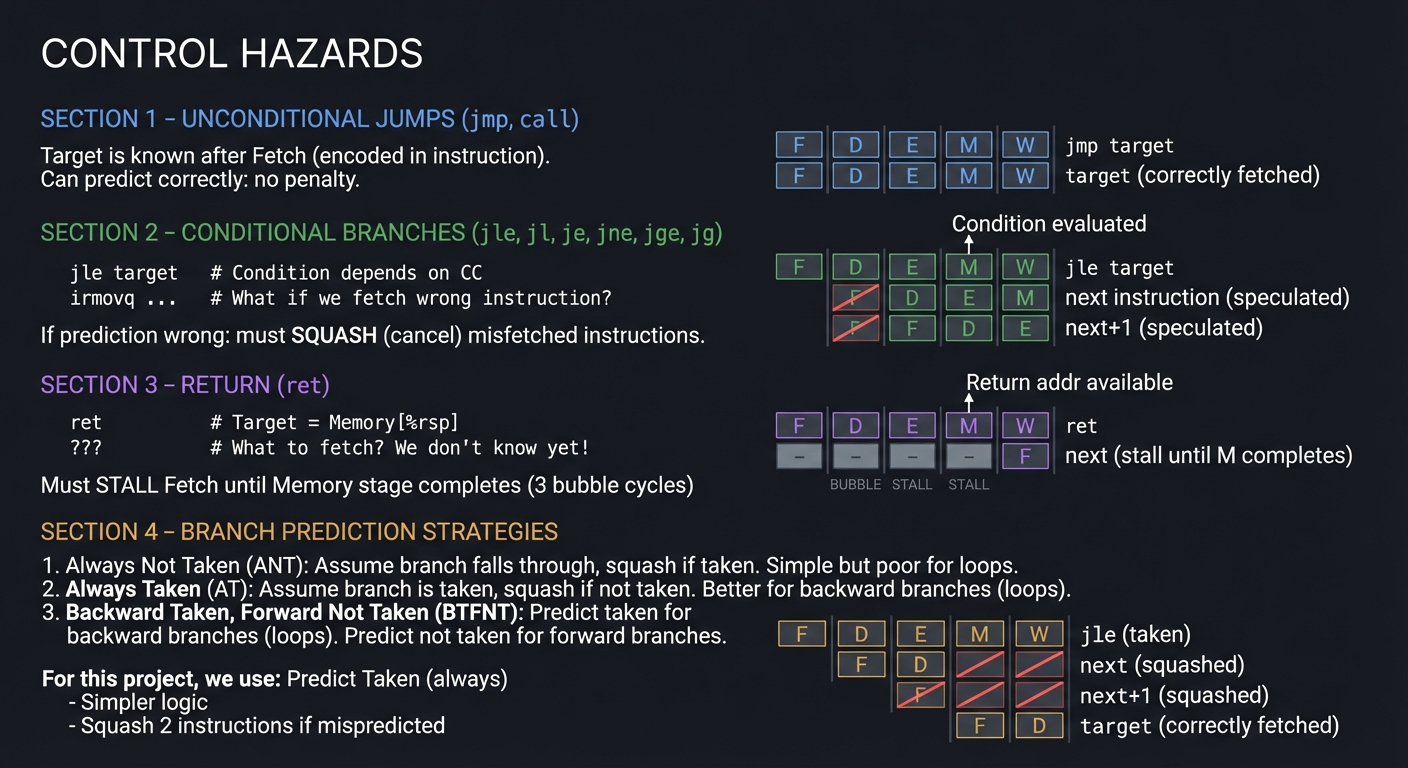
Control Hazards
Control hazards arise from branches and jumps where the next PC is uncertain:
+-----------------------------------------------------------------------+
| CONTROL HAZARDS |
+-----------------------------------------------------------------------+
| |
| UNCONDITIONAL JUMPS (jmp, call): |
| --------------------------------- |
| Target is known after Fetch (encoded in instruction) |
| Can predict correctly: no penalty |
| |
| CONDITIONAL BRANCHES (jle, jl, je, jne, jge, jg): |
| -------------------------------------------------- |
| Target known after Fetch, but condition known after Execute |
| |
| jle target # Condition depends on CC |
| irmovq ... # What if we fetch wrong instruction? |
| |
| +---+---+---+---+---+ |
| | F | D | E | M | W | jle |
| | | F | D | E | M | next instruction (speculated) |
| | | | F | D | E | next+1 (speculated) |
| +---+---+---+---+---+ |
| ^ |
| Condition |
| evaluated |
| |
| If prediction wrong: must SQUASH (cancel) misfetched instructions |
| |
| RETURN (ret): |
| -------------- |
| Target comes from stack - unknown until Memory stage! |
| |
| ret # Target = Memory[%rsp] |
| ??? # What to fetch? We don't know yet! |
| |
| +---+---+---+---+---+ |
| | F | D | E | M | W | ret |
| | | - | - | - | F | next (stall until M completes) |
| +---+---+---+---+---+ |
| ^ |
| Return addr |
| available |
| |
| Must STALL Fetch until Memory stage completes (3 bubble cycles) |
| |
+-----------------------------------------------------------------------+
| |
| BRANCH PREDICTION STRATEGIES: |
| ------------------------------ |
| |
| 1. Always Not Taken (ANT): |
| Assume branch falls through, squash if taken |
| Simple but poor for loops |
| |
| 2. Always Taken (AT): |
| Assume branch is taken, squash if not taken |
| Better for backward branches (loops) |
| |
| 3. Backward Taken, Forward Not Taken (BTFNT): |
| Predict taken for backward branches (loops) |
| Predict not taken for forward branches |
| |
| For this project, we use: Predict Taken (always) |
| - Simpler logic |
| - Squash 2 instructions if mispredicted |
| |
+-----------------------------------------------------------------------+
Hazard Detection and Forwarding
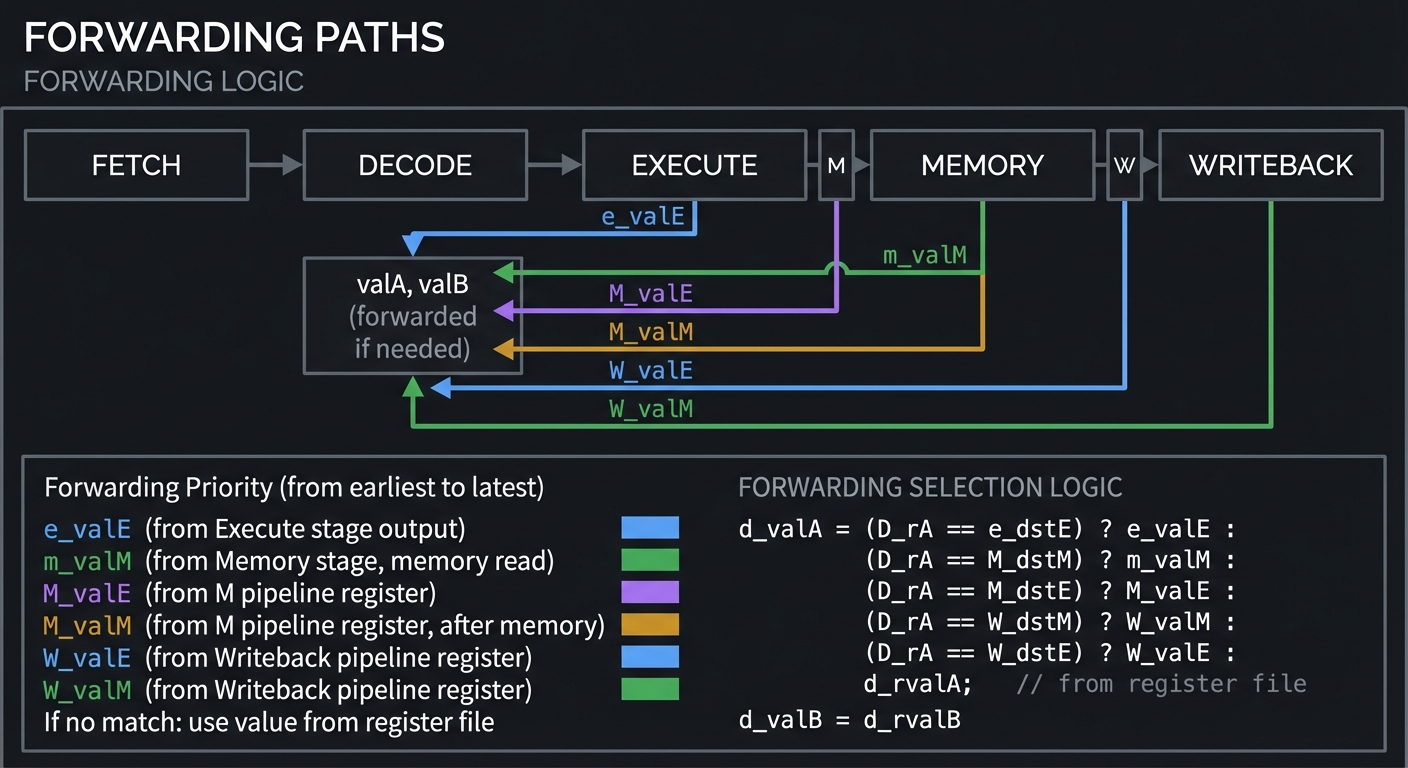
Forwarding bypasses the register file to supply values directly:
+-----------------------------------------------------------------------+
| FORWARDING PATHS |
+-----------------------------------------------------------------------+
| |
| FORWARDING LOGIC |
| |
| +--------+ +--------+ +--------+ +--------+ +---------+ |
| | FETCH | | DECODE | |EXECUTE | | MEMORY | |WRITEBACK| |
| +--------+ +--------+ +--------+ +--------+ +---------+ |
| | ^ | | | |
| | | +------+ | | |
| | | | | | |
| | +----+---e_valE------------+ | |
| | | | | |
| | +----+---------m_valM---------------------+ |
| | | | |
| | +--------------M_valE---------------------+ |
| | | | |
| | +--------------M_valM---------------------+ |
| | | |
| | +----------------------------------W_valE---------+
| | | |
| | +----------------------------------W_valM---------+
| | |
| valA, valB |
| (forwarded if needed) |
| |
| Forwarding Priority (from earliest to latest): |
| 1. e_valE (from Execute stage output) |
| 2. m_valM (from Memory stage, memory read) |
| 3. M_valE (from M pipeline register) |
| 4. M_valM (from M pipeline register, after memory) |
| 5. W_valE (from Writeback pipeline register) |
| 6. W_valM (from Writeback pipeline register) |
| |
| If no match: use value from register file |
| |
+-----------------------------------------------------------------------+
| |
| FORWARDING SELECTION LOGIC (pseudocode): |
| |
| d_valA = (D_rA == e_dstE) ? e_valE : |
| (D_rA == M_dstM) ? m_valM : |
| (D_rA == M_dstE) ? M_valE : |
| (D_rA == W_dstM) ? W_valM : |
| (D_rA == W_dstE) ? W_valE : |
| d_rvalA; // from register file |
| |
| Similarly for d_valB |
| |
+-----------------------------------------------------------------------+
Stalling and Bubbling
When forwarding is insufficient, we must stall or insert bubbles:
+-----------------------------------------------------------------------+
| STALLING AND BUBBLING |
+-----------------------------------------------------------------------+
| |
| STALL: Hold a stage's inputs constant (don't advance) |
| BUBBLE: Insert a nop-like instruction (clear the stage) |
| |
| +------------------------------------------------------------------+ |
| | PIPELINE CONTROL SIGNALS | |
| +------------------------------------------------------------------+ |
| | | |
| | For each pipeline register: | |
| | NORMAL: load new values from previous stage | |
| | STALL: keep current values (don't update) | |
| | BUBBLE: load bubble/nop values (clear state) | |
| | | |
| +------------------------------------------------------------------+ |
| |
| LOAD-USE HAZARD (requires stall): |
| |
| Cycle: 1 2 3 4 5 6 7 |
| mrmovq: [F] [D] [E] [M] [W] |
| addq: [F] [D] [D] [E] [M] [W] <- D repeats! |
| next: [F] [F] [D] [E] [M] <- F repeats! |
| |
| ^ ^ |
| | | |
| Bubble Stall |
| in E F and D |
| |
| Actions: |
| - F_stall = 1 (hold PC) |
| - D_stall = 1 (hold D register) |
| - E_bubble = 1 (insert nop into Execute) |
| |
| MISPREDICTED BRANCH: |
| |
| Cycle: 1 2 3 4 5 6 7 |
| jne: [F] [D] [E] [M] [W] |
| wrongI1: [F] [D] X <- cancelled! |
| wrongI2: [F] X <- cancelled! |
| correct: [F] [D] [E] [M] <- fetch after E |
| |
| ^ |
| Branch |
| resolved |
| |
| Actions (at cycle 4): |
| - D_bubble = 1 (cancel wrongI1) |
| - E_bubble = 1 (cancel wrongI2) |
| - Correct PC fed to Fetch |
| |
| RETURN INSTRUCTION: |
| |
| Cycle: 1 2 3 4 5 6 7 |
| ret: [F] [D] [E] [M] [W] |
| bubble: [B] [B] [B] <- 3 bubbles |
| target: [F] [D] [E] <- after M completes |
| |
| Actions: |
| - While ret in D, E, or M: D_bubble = 1 |
| - F_stall until return address available |
| |
+-----------------------------------------------------------------------+
Complete Pipeline Control Logic
+-----------------------------------------------------------------------+
| PIPELINE CONTROL CONDITIONS |
+-----------------------------------------------------------------------+
| |
| CONDITION DEFINITIONS: |
| |
| load_use_hazard = ( |
| E_icode in {IMRMOVQ, IPOPQ} && |
| E_dstM in {d_srcA, d_srcB} |
| ) |
| |
| mispredicted_branch = ( |
| E_icode == IJXX && !e_Cnd // branch in E, not taken |
| ) |
| |
| ret_hazard = ( |
| IRET in {D_icode, E_icode, M_icode} |
| ) |
| |
+-----------------------------------------------------------------------+
| |
| CONTROL ACTIONS: |
| |
| Condition | F_stall | D_stall | D_bubble | E_bubble | |
| ---------------------|---------|---------|----------|----------| |
| load_use_hazard | 1 | 1 | 0 | 1 | |
| mispredicted_branch | 0 | 0 | 1 | 1 | |
| ret_hazard | 1 | 0 | 1 | 0 | |
| normal | 0 | 0 | 0 | 0 | |
| |
| Special case: load_use + ret simultaneously: |
| Prioritize load_use (stall), don't bubble D |
| |
+-----------------------------------------------------------------------+
Pipeline Registers
Each pipeline register holds state passed between stages:
+-----------------------------------------------------------------------+
| PIPELINE REGISTER CONTENTS |
+-----------------------------------------------------------------------+
| |
| F Register (minimal - just predicted PC): |
| +------------------------------------------+ |
| | predPC | Predicted next PC | |
| +------------------------------------------+ |
| |
| D Register (after Fetch, before Decode): |
| +------------------------------------------+ |
| | stat | Status (AOK, HLT, ADR, INS) | |
| | icode | Instruction code | |
| | ifun | Instruction function | |
| | rA | Register A specifier | |
| | rB | Register B specifier | |
| | valC | Constant (immediate/disp) | |
| | valP | PC of next instruction | |
| +------------------------------------------+ |
| |
| E Register (after Decode, before Execute): |
| +------------------------------------------+ |
| | stat | Status | |
| | icode | Instruction code | |
| | ifun | Instruction function | |
| | valC | Constant | |
| | valA | Value read from srcA | |
| | valB | Value read from srcB | |
| | dstE | Destination register (ALU) | |
| | dstM | Destination register (Memory) | |
| | srcA | Source A (for forwarding) | |
| | srcB | Source B (for forwarding) | |
| +------------------------------------------+ |
| |
| M Register (after Execute, before Memory): |
| +------------------------------------------+ |
| | stat | Status | |
| | icode | Instruction code | |
| | Cnd | Condition result (for cmov/jmp) | |
| | valE | ALU result | |
| | valA | Passthrough (for rmmovq/pushq) | |
| | dstE | Destination register (ALU) | |
| | dstM | Destination register (Memory) | |
| +------------------------------------------+ |
| |
| W Register (after Memory, before Writeback): |
| +------------------------------------------+ |
| | stat | Status | |
| | icode | Instruction code | |
| | valE | ALU result | |
| | valM | Memory result | |
| | dstE | Destination register (ALU) | |
| | dstM | Destination register (Memory) | |
| +------------------------------------------+ |
| |
+-----------------------------------------------------------------------+
Project Specification
What You Will Build
A command-line Y86-64 simulator with two execution modes:
- Sequential Simulator (SEQ): Execute one instruction per cycle, producing final state
- Pipelined Simulator (PIPE): Execute with 5-stage pipeline, producing per-cycle traces
Functional Requirements
- Object File Loading:
- Parse Y86-64 object files (YO format)
- Load code and data into simulated memory
- Validate memory addresses
- Sequential Execution:
- Implement all Y86-64 instructions
- Track register and memory state
- Report final state (registers, CC, status)
- Pipelined Execution:
- Implement 5-stage pipeline with registers
- Detect and handle all hazards (data, control)
- Produce cycle-by-cycle trace output
- Trace Output:
- Show pipeline stage contents each cycle
- Indicate stalls, bubbles, and forwards
- Explain hazard reasons
Example Trace Output
$ ./y86sim -p trace.yo
=== Y86-64 PIPELINED SIMULATOR ===
Program: trace.yo
Mode: Pipelined with trace
Cycle 1:
+-------+------------+------------+------------+------------+------------+
| Stage | icode | valE | valM | srcA/B | dstE/M |
+-------+------------+------------+------------+------------+------------+
| F | irmovq | - | - | - | - |
| D | nop | - | - | -/- | -/- |
| E | nop | - | - | - | -/- |
| M | nop | - | - | - | -/- |
| W | nop | - | - | - | -/- |
+-------+------------+------------+------------+------------+------------+
PC = 0x000, Status = AOK
Cycle 2:
+-------+------------+------------+------------+------------+------------+
| Stage | icode | valE | valM | srcA/B | dstE/M |
+-------+------------+------------+------------+------------+------------+
| F | mrmovq | - | - | - | - |
| D | irmovq | - | - | -/- | -/%rax |
| E | nop | - | - | - | -/- |
| M | nop | - | - | - | -/- |
| W | nop | - | - | - | -/- |
+-------+------------+------------+------------+------------+------------+
PC = 0x00a, Status = AOK
Cycle 3:
+-------+------------+------------+------------+------------+------------+
| Stage | icode | valE | valM | srcA/B | dstE/M |
+-------+------------+------------+------------+------------+------------+
| F | addq | - | - | - | - |
| D | mrmovq | - | - | -/%rax | %rbx/- |
| E | irmovq | 0x0000064 | - | - | %rax/- |
| M | nop | - | - | - | -/- |
| W | nop | - | - | - | -/- |
+-------+------------+------------+------------+------------+------------+
PC = 0x014, Status = AOK
FORWARD: D_valB <- E_valE (0x0000064) [%rax from irmovq]
Cycle 4:
+-------+------------+------------+------------+------------+------------+
| Stage | icode | valE | valM | srcA/B | dstE/M |
+-------+------------+------------+------------+------------+------------+
| F | addq | - | - | - | - |
| D | addq | - | - |%rbx/%rcx | -/%rcx |
| E | bubble | - | - | - | -/- |
| M | irmovq | 0x0000064 | - | - | %rax/- |
| W | nop | - | - | - | -/- |
+-------+------------+------------+------------+------------+------------+
PC = 0x014, Status = AOK
STALL: Load-use hazard (%rbx from mrmovq)
Action: F stall, D stall, E bubble
Cycle 5:
+-------+------------+------------+------------+------------+------------+
| Stage | icode | valE | valM | srcA/B | dstE/M |
+-------+------------+------------+------------+------------+------------+
| F | halt | - | - | - | - |
| D | addq | - | - |%rbx/%rcx | -/%rcx |
| E | mrmovq | 0x0000064 | - | - | %rbx/- |
| M | bubble | - | - | - | -/- |
| W | irmovq | 0x0000064 | - | - | %rax/- |
+-------+------------+------------+------------+------------+------------+
PC = 0x016, Status = AOK
FORWARD: D_valA <- m_valM (pending) [%rbx from mrmovq]
...
=== FINAL STATE ===
Cycles: 12
Instructions: 8
CPI: 1.50
Registers:
%rax = 0x0000000000000064
%rbx = 0x0000000000000005
%rcx = 0x0000000000000069
...
Condition Codes: ZF=0 SF=0 OF=0
Status: HLT
Hazard Statistics:
Load-use stalls: 1
Branch mispredicts: 0
Return stalls: 0
Data forwards: 3
Non-Functional Requirements
- Correctness: Pipelined execution must produce identical final state to sequential
- Completeness: All Y86-64 instructions implemented
- Traceability: Every pipeline event must be explainable
- Performance: Handle programs up to 10,000 instructions
Real World Outcome
When you complete this project, here is exactly what you will see when running your Y86-64 simulator:
$ cd y86sim
$ make
gcc -O2 -Wall -g -c src/main.c -o build/main.o
gcc -O2 -Wall -g -c src/seq_sim.c -o build/seq_sim.o
gcc -O2 -Wall -g -c src/pipe_sim.c -o build/pipe_sim.o
...
gcc -o y86sim build/*.o
$ cat tests/sum.yo
| # Sum array program
0x000: 30f40002000000000000 | irmovq $0x200, %rsp
0x00a: 30f10001000000000000 | irmovq array, %rcx
0x014: 30f20500000000000000 | irmovq $5, %rdx
0x01e: 6300 | xorq %rax, %rax
0x020: 6266 | andq %rsi, %rsi
0x022: | loop:
0x022: 50610000000000000000 | mrmovq (%rcx), %rsi
0x02c: 6060 | addq %rsi, %rax
0x02e: 30f70800000000000000 | irmovq $8, %rdi
0x038: 6071 | addq %rdi, %rcx
0x03a: 30f70100000000000000 | irmovq $1, %rdi
0x044: 6172 | subq %rdi, %rdx
0x046: 742200000000000000 | jne loop
0x04f: 00 | halt
0x100: | array:
0x100: 0100000000000000 | .quad 1
0x108: 0200000000000000 | .quad 2
...
$ ./y86sim --mode seq tests/sum.yo
=== Y86-64 SEQUENTIAL SIMULATOR ===
Program: tests/sum.yo
Mode: Sequential
Executing...
Instructions: 37
Status: HLT
=== FINAL STATE ===
Registers:
%rax = 0x000000000000000f (15 = 1+2+3+4+5)
%rcx = 0x0000000000000128
%rdx = 0x0000000000000000
%rsp = 0x0000000000000200
...
Condition Codes: ZF=1 SF=0 OF=0
Status: HLT (Halted)
$ ./y86sim --mode pipe --trace tests/sum.yo
=== Y86-64 PIPELINED SIMULATOR ===
Program: tests/sum.yo
Mode: Pipelined with trace
Cycle 1:
+-------+------------+--------+--------+----------+----------+
| Stage | icode | valE | valM | src A/B | dst E/M |
+-------+------------+--------+--------+----------+----------+
| F | irmovq | - | - | -/- | -/- |
| D | bubble | - | - | -/- | -/- |
| E | bubble | - | - | -/- | -/- |
| M | bubble | - | - | -/- | -/- |
| W | bubble | - | - | -/- | -/- |
+-------+------------+--------+--------+----------+----------+
PC = 0x000, Status = AOK
Cycle 2:
+-------+------------+--------+--------+----------+----------+
| Stage | icode | valE | valM | src A/B | dst E/M |
+-------+------------+--------+--------+----------+----------+
| F | irmovq | - | - | -/- | -/- |
| D | irmovq | - | - | -/F | %rsp/- |
| E | bubble | - | - | -/- | -/- |
| M | bubble | - | - | -/- | -/- |
| W | bubble | - | - | -/- | -/- |
+-------+------------+--------+--------+----------+----------+
PC = 0x00a, Status = AOK
...
Cycle 15:
FORWARD: D_valA <- M_valE (0x0000000000000108) [%rcx from addq]
STALL: Load-use hazard (%rsi from mrmovq)
Action: F stall, D stall, E bubble
...
=== FINAL STATE ===
Cycles: 52
Instructions: 37
CPI: 1.41
Registers:
%rax = 0x000000000000000f
Hazard Statistics:
Load-use stalls: 5
Branch mispredicts: 0
Return stalls: 0
Data forwards: 23
$ ./y86sim --mode both tests/sum.yo
=== EQUIVALENCE CHECK ===
SEQ final state matches PIPE final state: PASS
SEQ instructions: 37
PIPE cycles: 52
CPI: 1.41
Solution Architecture
High-Level Design
+-----------------------------------------------------------------------+
| Y86-64 SIMULATOR |
+-----------------------------------------------------------------------+
| |
| +------------------+ |
| | Main Driver | |
| | - Parse args | |
| | - Load program | |
| | - Select mode | |
| +--------+---------+ |
| | |
| +--------------------+--------------------+ |
| | | | |
| v v v |
| +------------------+ +------------------+ +------------------+ |
| | Object Loader | | SEQ Simulator | | PIPE Simulator | |
| | - Parse .yo file | | - Fetch | | - Pipeline regs | |
| | - Load memory | | - Decode | | - Hazard detect | |
| | - Symbol table | | - Execute | | - Forwarding | |
| +--------+---------+ | - Memory | | - Stall/Bubble | |
| | | - Writeback | | - Trace output | |
| v | - PC update | +--------+---------+ |
| +------------------+ +--------+---------+ | |
| | Memory Model | | | |
| | - Read/Write | +----------+----------+ |
| | - Bounds check | | |
| +------------------+ v |
| ^ +------------------+ |
| | | Register File | |
| +------------| - 15 registers | |
| | - Read ports | |
| | - Write ports | |
| +------------------+ |
| |
+-----------------------------------------------------------------------+
Key Data Structures
/* Instruction codes */
typedef enum {
I_HALT = 0x0,
I_NOP = 0x1,
I_RRMOVQ = 0x2, /* Also cmovXX */
I_IRMOVQ = 0x3,
I_RMMOVQ = 0x4,
I_MRMOVQ = 0x5,
I_OPQ = 0x6,
I_JXX = 0x7,
I_CALL = 0x8,
I_RET = 0x9,
I_PUSHQ = 0xA,
I_POPQ = 0xB
} icode_t;
/* Function codes */
typedef enum {
F_NONE = 0,
/* OPq functions */
A_ADD = 0, A_SUB = 1, A_AND = 2, A_XOR = 3,
/* Jump/cmov conditions */
C_YES = 0, C_LE = 1, C_L = 2, C_E = 3,
C_NE = 4, C_GE = 5, C_G = 6
} ifun_t;
/* Processor status */
typedef enum {
STAT_AOK = 1, /* Normal operation */
STAT_HLT = 2, /* halt instruction */
STAT_ADR = 3, /* Invalid address */
STAT_INS = 4 /* Invalid instruction */
} stat_t;
/* Register identifiers */
typedef enum {
R_RAX = 0, R_RCX = 1, R_RDX = 2, R_RBX = 3,
R_RSP = 4, R_RBP = 5, R_RSI = 6, R_RDI = 7,
R_R8 = 8, R_R9 = 9, R_R10 = 10, R_R11 = 11,
R_R12 = 12, R_R13 = 13, R_R14 = 14,
R_NONE = 0xF
} reg_t;
/* Condition codes */
typedef struct {
bool ZF; /* Zero flag */
bool SF; /* Sign flag */
bool OF; /* Overflow flag */
} cc_t;
/* Processor state (for SEQ) */
typedef struct {
uint64_t PC;
uint64_t regs[15];
cc_t CC;
stat_t status;
uint8_t *memory;
size_t mem_size;
} cpu_state_t;
/* Pipeline register contents */
typedef struct {
stat_t stat;
icode_t icode;
ifun_t ifun;
reg_t rA, rB;
int64_t valC;
uint64_t valP;
} f_register_t;
typedef struct {
stat_t stat;
icode_t icode;
ifun_t ifun;
int64_t valC;
int64_t valA, valB;
reg_t dstE, dstM;
reg_t srcA, srcB;
} e_register_t;
typedef struct {
stat_t stat;
icode_t icode;
bool Cnd;
int64_t valE;
int64_t valA;
reg_t dstE, dstM;
} m_register_t;
typedef struct {
stat_t stat;
icode_t icode;
int64_t valE, valM;
reg_t dstE, dstM;
} w_register_t;
/* Pipeline state */
typedef struct {
uint64_t predPC;
f_register_t F; /* Fetch output / Decode input */
e_register_t D; /* Decode output / Execute input */
m_register_t E; /* Execute output / Memory input */
w_register_t M; /* Memory output / Writeback input */
/* Forwarding values */
int64_t e_valE; /* ALU output this cycle */
int64_t m_valM; /* Memory read this cycle */
/* Control signals */
bool F_stall, D_stall;
bool D_bubble, E_bubble;
/* Statistics */
uint64_t cycles;
uint64_t instructions;
uint64_t load_use_stalls;
uint64_t branch_mispredicts;
uint64_t ret_stalls;
uint64_t forwards;
} pipe_state_t;
Module Structure
y86sim/
|-- src/
| |-- main.c # Entry point, argument parsing
| |-- loader.c # Object file loading
| |-- memory.c # Memory model
| |-- registers.c # Register file operations
| |-- seq_sim.c # Sequential simulator
| |-- pipe_sim.c # Pipelined simulator
| |-- stages/
| | |-- fetch.c # Fetch stage logic
| | |-- decode.c # Decode stage logic
| | |-- execute.c # Execute stage logic
| | |-- memory.c # Memory stage logic
| | |-- writeback.c # Writeback stage logic
| |-- hazard.c # Hazard detection
| |-- forward.c # Forwarding logic
| |-- trace.c # Trace output formatting
| |-- alu.c # ALU operations
| |-- condition.c # Condition code logic
|-- include/
| |-- y86.h # Type definitions
| |-- stages.h # Stage function declarations
| |-- hazard.h # Hazard detection interface
|-- tests/
| |-- simple/ # Basic instruction tests
| |-- hazards/ # Hazard test cases
| |-- programs/ # Full programs
|-- Makefile
|-- README.md
Implementation Guide
Phase 1: Foundation (Days 1-5)
Goals:
- Set up project structure
- Implement memory model
- Implement object file loader
- Implement register file
Tasks:
- Memory Model: ```c typedef struct { uint8_t *data; size_t size; } memory_t;
memory_t *memory_create(size_t size); void memory_destroy(memory_t *mem); uint64_t memory_read_quad(memory_t *mem, uint64_t addr, stat_t *status); void memory_write_quad(memory_t *mem, uint64_t addr, uint64_t val, stat_t *status); uint8_t memory_read_byte(memory_t *mem, uint64_t addr, stat_t *status);
2. **Object Loader**:
Parse .yo file format:
0x000: 30f40002000000000000 | irmovq $0x200, %rsp 0x00a: 30f10100000000000000 | irmovq $1, %rcx
3. **Register File**:
```c
uint64_t reg_read(cpu_state_t *cpu, reg_t r);
void reg_write(cpu_state_t *cpu, reg_t r, uint64_t val);
Checkpoint: Can load a .yo file and display memory contents.
Phase 2: Sequential Simulator (Days 6-14)
Goals:
- Implement all instruction semantics
- Complete the SEQ datapath
- Pass basic instruction tests
Tasks:
- Instruction Fetch: ```c typedef struct { icode_t icode; ifun_t ifun; reg_t rA, rB; int64_t valC; uint64_t valP; stat_t status; } fetch_result_t;
fetch_result_t seq_fetch(cpu_state_t *cpu);
2. **Decode Stage**:
```c
typedef struct {
int64_t valA, valB;
reg_t srcA, srcB;
} decode_result_t;
decode_result_t seq_decode(cpu_state_t *cpu, fetch_result_t *f);
- Execute Stage: ```c typedef struct { int64_t valE; bool Cnd; cc_t new_cc; } execute_result_t;
execute_result_t seq_execute(cpu_state_t *cpu, fetch_result_t *f, decode_result_t *d);
4. **Memory Stage**:
```c
typedef struct {
int64_t valM;
stat_t status;
} memory_result_t;
memory_result_t seq_memory(cpu_state_t *cpu, fetch_result_t *f,
decode_result_t *d, execute_result_t *e);
- Writeback Stage:
void seq_writeback(cpu_state_t *cpu, fetch_result_t *f, execute_result_t *e, memory_result_t *m); - PC Update:
uint64_t seq_pc_update(cpu_state_t *cpu, fetch_result_t *f, execute_result_t *e, memory_result_t *m);
Instruction Implementation Template:
/* Example: addq rA, rB */
case I_OPQ:
switch (ifun) {
case A_ADD:
valE = valA + valB;
break;
case A_SUB:
valE = valB - valA;
break;
case A_AND:
valE = valA & valB;
break;
case A_XOR:
valE = valA ^ valB;
break;
}
/* Set condition codes */
new_cc.ZF = (valE == 0);
new_cc.SF = ((int64_t)valE < 0);
new_cc.OF = /* overflow detection */;
break;
Checkpoint: Sequential simulator passes all instruction tests.
Phase 3: Pipeline Registers (Days 15-20)
Goals:
- Implement pipeline register structures
- Create register update logic
- Handle bubble injection
Tasks:
- Pipeline Register Operations:
void pipe_init(pipe_state_t *pipe); void pipe_update_F(pipe_state_t *pipe, bool stall, uint64_t new_predPC); void pipe_update_D(pipe_state_t *pipe, bool stall, bool bubble, f_register_t *new_D); void pipe_update_E(pipe_state_t *pipe, bool bubble, e_register_t *new_E); void pipe_update_M(pipe_state_t *pipe, m_register_t *new_M); void pipe_update_W(pipe_state_t *pipe, w_register_t *new_W); - Bubble Values:
e_register_t bubble_E = { .stat = STAT_AOK, .icode = I_NOP, .ifun = F_NONE, .valC = 0, .valA = 0, .valB = 0, .dstE = R_NONE, .dstM = R_NONE, .srcA = R_NONE, .srcB = R_NONE }; - Clock Cycle Logic:
void pipe_cycle(pipe_state_t *pipe, cpu_state_t *cpu) { /* Compute new values for each stage (combinational) */ w_register_t new_W = compute_W(pipe); m_register_t new_M = compute_M(pipe, cpu); e_register_t new_E = compute_E(pipe, cpu); f_register_t new_D = compute_D(pipe, cpu); uint64_t new_predPC = compute_F(pipe, cpu); /* Compute control signals */ compute_control(pipe); /* Update all registers simultaneously */ pipe_update_W(pipe, &new_W); pipe_update_M(pipe, &new_M); pipe_update_E(pipe, pipe->E_bubble, &new_E); pipe_update_D(pipe, pipe->D_stall, pipe->D_bubble, &new_D); pipe_update_F(pipe, pipe->F_stall, new_predPC); }
Checkpoint: Pipeline advances correctly with nop instructions.
Phase 4: Hazard Detection (Days 21-25)
Goals:
- Implement forwarding logic
- Implement stall detection
- Handle all hazard cases
Tasks:
- Forwarding Logic:
int64_t forward_valA(pipe_state_t *pipe, reg_t srcA, int64_t rvalA) { if (srcA == R_NONE) return 0; /* Priority: most recent first */ if (srcA == pipe->E.dstE) return pipe->e_valE; if (srcA == pipe->M.dstM) return pipe->m_valM; if (srcA == pipe->M.dstE) return pipe->M.valE; if (srcA == pipe->W.dstM) return pipe->W.valM; if (srcA == pipe->W.dstE) return pipe->W.valE; return rvalA; /* From register file */ } - Load-Use Detection:
bool detect_load_use(pipe_state_t *pipe) { bool E_is_load = (pipe->E.icode == I_MRMOVQ || pipe->E.icode == I_POPQ); if (!E_is_load) return false; return (pipe->E.dstM == pipe->D.srcA || pipe->E.dstM == pipe->D.srcB); } - Branch Misprediction Detection:
bool detect_mispredict(pipe_state_t *pipe) { return (pipe->E.icode == I_JXX && !pipe->e_Cnd); } - Return Detection:
bool detect_ret(pipe_state_t *pipe) { return (pipe->D.icode == I_RET || pipe->E.icode == I_RET || pipe->M.icode == I_RET); } - Control Signal Generation:
void compute_control(pipe_state_t *pipe) { bool load_use = detect_load_use(pipe); bool mispredict = detect_mispredict(pipe); bool ret_hazard = detect_ret(pipe); pipe->F_stall = load_use || ret_hazard; pipe->D_stall = load_use; pipe->D_bubble = mispredict || (ret_hazard && !load_use); pipe->E_bubble = load_use || mispredict; }
Checkpoint: All hazard test cases pass.
Phase 5: Integration and Validation (Days 26-30)
Goals:
- Integrate all components
- Validate against SEQ
- Comprehensive testing
Tasks:
- Equivalence Testing:
bool validate_equivalence(const char *program) { cpu_state_t seq_cpu, pipe_cpu; load_program(&seq_cpu, program); load_program(&pipe_cpu, program); /* Run SEQ to completion */ seq_run(&seq_cpu); /* Run PIPE to completion */ pipe_run(&pipe_cpu); /* Compare final states */ return compare_states(&seq_cpu, &pipe_cpu); } - Trace Output:
void trace_cycle(pipe_state_t *pipe) { printf("Cycle %lu:\n", pipe->cycles); print_stage("F", pipe->F); print_stage("D", pipe->D); print_stage("E", pipe->E); print_stage("M", pipe->M); print_stage("W", pipe->W); if (pipe->F_stall || pipe->D_stall) printf(" STALL: %s\n", stall_reason(pipe)); if (pipe->D_bubble || pipe->E_bubble) printf(" BUBBLE: %s\n", bubble_reason(pipe)); print_forwards(pipe); }
Checkpoint: All test programs produce identical results in SEQ and PIPE modes.
Testing Strategy
Test Categories
| Category | Purpose | Examples |
|---|---|---|
| Unit Tests | Test individual instructions | addq, mrmovq, jle |
| Hazard Tests | Test specific hazards | Load-use, branch mispredict |
| Integration | Full programs | Factorial, sum array |
| Equivalence | SEQ vs PIPE matching | All programs |
Hazard Test Cases
Load-Use Hazard:
# Test: mrmovq followed by immediate use
irmovq $0x100, %rax
irmovq $5, %rbx
rmmovq %rbx, (%rax)
mrmovq (%rax), %rcx # Loads value
addq %rcx, %rdx # Uses %rcx - LOAD-USE HAZARD!
halt
RAW Hazard (No Stall - Forwarding):
# Test: irmovq followed by use (should forward)
irmovq $10, %rax # Produces %rax
addq %rax, %rbx # Needs %rax - FORWARD from E
halt
Branch Misprediction:
# Test: conditional branch not taken
irmovq $5, %rax
irmovq $10, %rbx
subq %rax, %rbx # Sets CC (ZF=0, SF=0)
je target # Not taken! (ZF=0)
irmovq $1, %rcx # Should execute
halt
target:
irmovq $2, %rcx # Should NOT execute
halt
Return Hazard:
# Test: ret instruction
irmovq stack, %rsp
call func
halt
func:
irmovq $42, %rax
ret # Needs 3 bubble cycles
.pos 0x200
stack:
Full Program Tests
Factorial:
# Compute factorial(5) = 120
irmovq $5, %rdi
call factorial
halt
factorial:
irmovq $1, %rax # Base case result
andq %rdi, %rdi
je done
pushq %rdi
irmovq $1, %rsi
subq %rsi, %rdi
call factorial
popq %rdi
mulq %rdi, %rax # (Note: mulq not in Y86, use repeated add)
done:
ret
Sum Array:
# Sum array of 5 elements
irmovq array, %rdi
irmovq $5, %rsi
call sum
halt
sum:
xorq %rax, %rax
andq %rsi, %rsi
je sum_done
sum_loop:
mrmovq (%rdi), %r8
addq %r8, %rax
irmovq $8, %r9
addq %r9, %rdi
irmovq $1, %r9
subq %r9, %rsi
jne sum_loop
sum_done:
ret
.align 8
array:
.quad 1
.quad 2
.quad 3
.quad 4
.quad 5
Validation Matrix
+-----------------------------------------------------------------------+
| VALIDATION MATRIX |
+-----------------------------------------------------------------------+
| Test Type | SEQ Correct | PIPE Correct | SEQ == PIPE |
|----------------------|-------------|--------------|------------------|
| Basic Instructions | [ ] | [ ] | [ ] |
| Arithmetic (OPq) | [ ] | [ ] | [ ] |
| Memory Access | [ ] | [ ] | [ ] |
| Branches (taken) | [ ] | [ ] | [ ] |
| Branches (not taken) | [ ] | [ ] | [ ] |
| Call/Return | [ ] | [ ] | [ ] |
| Push/Pop | [ ] | [ ] | [ ] |
| Load-Use Hazard | N/A | [ ] | [ ] |
| Data Forward (E) | N/A | [ ] | [ ] |
| Data Forward (M) | N/A | [ ] | [ ] |
| Data Forward (W) | N/A | [ ] | [ ] |
| Branch Mispredict | N/A | [ ] | [ ] |
| Return Stall | N/A | [ ] | [ ] |
| Factorial Program | [ ] | [ ] | [ ] |
| Sum Array Program | [ ] | [ ] | [ ] |
+-----------------------------------------------------------------------+
Common Pitfalls
Frequent Mistakes
| Pitfall | Symptom | Solution |
|---|---|---|
| Wrong instruction length | PC points to wrong place | Create length table, verify against YAS |
| Sign extension errors | Wrong values for negative immediates | Use signed types, careful casting |
| Forgetting %rsp update | Stack corruption | Handle pushq/popq/call/ret specially |
| Wrong forwarding priority | Stale values used | Forward from most recent first |
| Missing hazard case | Incorrect execution | Systematic testing of all combinations |
| Off-by-one in cycles | Wrong pipeline timing | Draw timing diagrams carefully |
| Bubble vs Stall confusion | Instructions lost or duplicated | Bubble clears, Stall preserves |
| CC set at wrong time | Wrong branch decisions | Only OPq sets CC, only in Execute |
Debugging Strategies
- Single-Step Mode: Execute one cycle at a time, examine all state
- Comparison Testing: Run same program in SEQ and PIPE, compare at each step
- Known Programs: Use programs with known outputs (factorial, sum)
- Minimal Reproduction: Reduce failing case to minimum instructions
- Pipeline Diagrams: Draw actual vs expected pipeline timing
Tricky Edge Cases
Consecutive Memory Operations:
mrmovq (%rax), %rbx
mrmovq (%rbx), %rcx # Uses %rbx - load-use!
Self-Modifying Code (don’t support, but detect):
irmovq target, %rax
irmovq $0x00, %rbx
rmmovq %rbx, (%rax) # Writes to code section!
target:
addq ... # Modified instruction
Stack Pointer as Source and Dest:
pushq %rsp # What value gets pushed?
popq %rsp # What value gets popped?
Answer: For pushq %rsp, push the old (pre-decrement) value of %rsp.
Extensions
Beginner Extensions
- Interactive Mode: Step through execution, inspect state
- Disassembler: Convert binary back to assembly
- Memory Dump: Formatted hex dump of memory regions
Intermediate Extensions
- Branch Prediction: Implement BTFNT or 2-bit saturating counter
- Branch Target Buffer: Cache branch targets for faster prediction
- Performance Counters: Track IPC, cache hits (simulated), etc.
- Visualization: GUI showing pipeline state over time
Advanced Extensions
- Out-of-Order Execution: Implement Tomasulo’s algorithm
- Speculative Execution: Execute past branches, rollback on mispredict
- Superscalar: Issue multiple instructions per cycle
- Cache Simulation: Add L1 instruction and data caches
- SMT (Hyperthreading): Multiple hardware threads
Research Extensions
- Power Modeling: Estimate power based on pipeline activity
- Timing Attacks: Demonstrate speculative execution vulnerabilities
- Custom ISA Extensions: Add new instructions (multiply, divide)
Real-World Connections
Modern Processor Design
Your Y86-64 simulator models concepts found in real CPUs:
+-----------------------------------------------------------------------+
| Y86-64 CONCEPTS IN MODERN PROCESSORS |
+-----------------------------------------------------------------------+
| |
| Y86-64 Feature Modern Equivalent |
| ------------------ -------------------------------------------- |
| 5-stage pipeline 10-20+ stage pipelines (Intel, AMD) |
| Simple forwarding Complex bypass networks |
| Predict taken Sophisticated branch predictors (TAGE) |
| In-order execution Out-of-order with reorder buffer |
| Single issue 4-8 wide superscalar |
| Unified memory Separate I/D caches, TLBs, prefetchers |
| |
| Concepts that scale directly: |
| - Pipeline hazards (still fundamental) |
| - Forwarding networks (more complex but same idea) |
| - Branch misprediction penalties (larger with deeper pipelines) |
| - Memory latency hiding (critical in modern designs) |
| |
+-----------------------------------------------------------------------+
Industry Applications
- CPU Verification: Simulators validate hardware before fabrication
- Compiler Development: Understand how code maps to microarchitecture
- Performance Analysis: Profile software at the microarchitecture level
- Security Research: Analyze timing channels and speculative vulnerabilities
- Education: Foundation for computer architecture courses
Related Technologies
- gem5: Open-source full-system simulator
- QEMU: Emulator for full system emulation
- Spike: RISC-V ISA simulator
- Intel SDE: Software Development Emulator for x86
- LLVM: Uses similar concepts for instruction scheduling
Interview Relevance
This project prepares you for questions like:
- “Explain how a CPU pipeline works”
- “What are data hazards and how are they resolved?”
- “Why does branch misprediction hurt performance?”
- “How does out-of-order execution work?”
- “Explain forwarding in a pipelined processor”
Resources
Essential Reading
- CS:APP Chapter 4: “Processor Architecture” - Complete coverage of Y86-64 and PIPE
- CS:APP Chapter 5: “Optimizing Program Performance” - Why pipeline details matter
- Patterson & Hennessy: “Computer Organization and Design” - Alternative perspective
Y86-64 Tools
- YAS: Y86-64 assembler (assembles .ys to .yo)
- YIS: Y86-64 sequential simulator (reference implementation)
- SSIM: Student simulator framework
Available at: http://csapp.cs.cmu.edu/3e/labs.html
Video Resources
- CMU 15-213 lectures on processor architecture
- MIT 6.004 computational structures
- David Patterson’s “Computer Architecture” MOOC
Reference Documentation
- Y86-64 Programmer’s Manual: Detailed ISA specification
- HCL Description: Hardware Control Language for pipeline description
- PIPE Implementation Notes: Stage-by-stage implementation details
Related Projects in This Series
- Previous: P6 (Attack Lab Workflow) - Understanding x86-64 calling conventions
- Next: P8 (Performance Clinic) - Applying pipeline knowledge to optimization
- Related: P9 (Cache Lab) - Memory hierarchy understanding
Self-Assessment Checklist
Understanding
- I can explain each stage of the 5-stage pipeline
- I can identify RAW, WAR, and WAW hazards in code
- I understand why forwarding works and when it doesn’t (load-use)
- I can explain branch prediction and misprediction penalties
- I understand the difference between stall and bubble
- I can trace pipeline execution on paper for small programs
Implementation
- Sequential simulator executes all instructions correctly
- Pipeline registers update correctly each cycle
- Forwarding paths cover all cases
- Load-use hazard detection works
- Branch misprediction recovery works
- Return instruction stalls correctly
- All test programs produce correct results
Validation
- SEQ and PIPE produce identical final states
- Cycle counts match expected values
- Trace output explains all hazard events
- Edge cases are handled (consecutive hazards, etc.)
Growth
- I can predict CPI for simple programs
- I understand performance implications of code ordering
- I can explain modern CPU concepts in terms of what I learned
- I debugged at least one subtle hazard bug
Submission / Completion Criteria
Minimum Viable Completion:
- Sequential simulator passes all instruction tests
- Pipelined simulator produces correct final state
- Basic trace output showing pipeline stages
Full Completion:
- All hazard cases handled correctly
- Detailed trace output with hazard explanations
- Equivalence testing passes for all programs
- Statistics output (CPI, hazard counts)
Excellence (Going Above & Beyond):
- Branch prediction with accuracy tracking
- Interactive debugging mode
- Visualization of pipeline state
- Performance comparison with real processors
- Extension to handle additional instructions
The Core Question You’re Answering
“How does a CPU execute instructions, and what are the fundamental trade-offs between simplicity and performance that led to pipelining - including all the complexity required to make pipelining correct?”
This question is central to understanding computer architecture. You’re learning:
- How an ISA specification translates into hardware behavior
- Why pipelining improves throughput but creates hazards
- How forwarding and stalling maintain correctness while preserving performance
- The concept of “time as a discrete resource” - thinking in cycles
Concepts You Must Understand First
Before starting this project, ensure you understand these concepts:
| Concept | Where to Learn | Why It’s Needed |
|---|---|---|
| Sequential Logic | CS:APP 4.2 | Understand clock cycles and state transitions |
| Combinational Logic | CS:APP 4.2 | Know how values propagate through gates in zero time |
| Instruction Encoding | CS:APP 4.1.3 | Decode Y86-64 instruction bytes |
| Register File Operation | CS:APP 4.2.5 | Implement multi-port read/write |
| ALU Operations | CS:APP 4.2.3 | Understand arithmetic and condition code setting |
| Pipeline Stages | CS:APP 4.4 | Know what happens in F, D, E, M, W |
| Data Dependencies | CS:APP 4.5.5 | Identify RAW, WAR, WAW hazards |
| Control Dependencies | CS:APP 4.5.8 | Understand branch and return handling |
Questions to Guide Your Design
As you implement the simulator, ask yourself:
- What state must I track? Registers, memory, PC, condition codes, status - what else?
- How do I decode instructions? Given bytes, how do I extract icode, ifun, registers, constants?
- What happens in each stage? For each instruction type, what does Fetch/Decode/Execute/Memory/Writeback do?
- When is state updated? At the clock edge - how do I model simultaneous updates?
- What creates a hazard? When does an instruction need a value not yet available?
- How do I detect hazards? Compare source registers with destination registers in later stages
- What is the correct action? Stall, bubble, or forward - and when?
Thinking Exercise
Before you start coding, trace through this instruction sequence by hand:
0x000: irmovq $100, %rax # I1
0x00a: irmovq $200, %rbx # I2
0x014: addq %rax, %rbx # I3 - needs %rax and %rbx
0x016: mrmovq 0(%rbx), %rcx # I4 - needs %rbx
0x020: addq %rcx, %rax # I5 - needs %rcx (LOAD-USE!)
0x022: halt # I6
Fill in this pipeline diagram:
Cycle: 1 2 3 4 5 6 7 8 9 10 11
I1: [F] [D] [E] [M] [W]
I2: [F] [D] [E] [M] [W]
I3: [?] [?] [?] [?] [?]
I4: [?] [?] [?] [?] [?]
I5: [?] [?] [?] [?] [?] [?]
I6: [?] [?] [?] [?] [?]
Questions to answer:
- When I3 is in Decode (cycle 3), where are %rax and %rbx? Are they available?
- What forwarding is needed for I3?
- When I4 needs %rbx, where is that value?
- When I5 needs %rcx from I4’s load, can we forward it? Why or why not?
- How many stall cycles are needed? When?
Expected answers:
- I3 in D at cycle 3: %rax is being written by I1 (W stage), %rbx is in I2 (E stage, result available as e_valE)
- Forward %rax from W_valE, forward %rbx from e_valE
- %rbx is in M stage (M_valE) when I4 decodes - forward from M_valE
- NO - I4 produces valM at end of M stage, I5 needs it at start of D stage. Must STALL for 1 cycle.
- 1 stall cycle when I5 reaches D and I4 is in E (load-use hazard)
Hints in Layers
If you get stuck, reveal hints one at a time. Try each level before moving to the next.
Hint 1 - Start with SEQ
Build the sequential simulator FIRST. Get every instruction working correctly before attempting pipelining. SEQ is your correctness reference.
Hint 2 - Pipeline Registers as Structs
Model each pipeline register (F, D, E, M, W) as a struct holding all values passed between stages. Update ALL registers simultaneously at the end of each cycle.
Hint 3 - Forwarding Priority
When checking for forwarding, priority matters: check Execute stage first (most recent), then Memory, then Writeback. First match wins.
Hint 4 - Hazard Detection Logic
Three conditions to check every cycle:
- Load-use: Is E stage a load AND does D stage need E’s dstM?
- Misprediction: Is E stage a conditional jump AND was prediction wrong?
- Return: Is there a RET in D, E, or M stages?
The Interview Questions They’ll Ask
After completing this project, you should be able to answer these interview questions:
- “Explain the 5 stages of a classic RISC pipeline.”
- Fetch: Read instruction from memory, increment PC
- Decode: Read registers, determine operation
- Execute: Perform ALU operation or address calculation
- Memory: Read/write data memory
- Writeback: Write results back to register file
- “What are the three types of pipeline hazards?”
- Structural: Two instructions need same hardware (rare in simple pipelines)
- Data: Instruction needs result from previous instruction not yet available (RAW most common)
- Control: Branch/jump target unknown, wrong instructions may be in pipeline
- “What is forwarding (bypassing) and why does it help?”
- Forwarding sends computed value directly to where it’s needed
- Avoids waiting for writeback stage
- Reduces stalls from 2-3 cycles to 0 for most RAW hazards
- “Why can’t we always avoid stalls with forwarding?”
- Load-use hazard: Memory read value (valM) not available until end of Memory stage
- But Decode stage needs it at the beginning of the cycle
- Must stall 1 cycle to let load complete
- “How do you handle branch misprediction in a pipeline?”
- Speculate: predict branch outcome, fetch predicted path
- Verify: check prediction when branch executes (E stage for conditional)
- Squash: if wrong, insert bubbles (cancel instructions) and fetch correct path
- “What is the CPI (Cycles Per Instruction) for an ideal pipeline? Why is real CPI higher?”
- Ideal CPI = 1.0 (one instruction completes per cycle)
- Real CPI > 1 due to: load-use stalls, branch mispredictions, return stalls
- Typical CPI: 1.2-1.5 for well-designed code
Books That Will Help
| Topic | Book | Chapter/Section |
|---|---|---|
| Y86-64 ISA Specification | CS:APP 3e | Section 4.1 |
| Sequential Implementation | CS:APP 3e | Section 4.3 |
| Pipeline Implementation | CS:APP 3e | Section 4.4-4.5 |
| Hazards and Forwarding | CS:APP 3e | Section 4.5.5-4.5.8 |
| Alternative Pipeline View | Patterson & Hennessy | Appendix C |
| Advanced Pipelining | Hennessy & Patterson (CAQA) | Chapter 3 |
| Digital Logic Background | CS:APP 3e | Section 4.2 |
| HCL Reference | CS:APP 3e | Section 4.2.5 |
This guide was expanded from CSAPP_3E_DEEP_LEARNING_PROJECTS.md. For the complete learning path, see the project index.
When you complete this project, you will have built a working computer inside a computer. Every modern processor, from smartphones to supercomputers, uses the concepts you’ve implemented. The pipeline, hazard detection, and forwarding logic you write are direct analogs of what runs in silicon.